Python Pandas 做数据分析之玩转 Excel 报表分析
各位朋友大家好,非常荣幸和大家聊一聊用 Python Pandas 处理 Excel 数据的话题。因为工作中一直在用 Pandas,所以积累了一些小技巧,在此借 GitChat 平台和大家分享一下心得。
在开始之前我推荐大家下载使用 Anaconda,里面包含了 Spyder 和 Jupyter Notebook 等集成工具。到百度搜索一下就可以找到官方下载链接,下载个人版就可以(本文使用的 Python 版本为 3.6.0 ,只要大家用的是 Python 3,那么语法就和文中几乎没有差异)。
一、数据的读取
在工作中,实验数据和工作表格通常存储在 Excel 的文件中。也有人使用数据库,数据库本身自带简单的求和、计数等功能。如果做深入的数据分析,就离不开像 Python Pandas、TensorFlow 等专业工具了。数据库导出的数据文件通常为 CSV、UNL 格式。CSV 和 UNL 格式数据也可以用 Excel 打开并正常显示为表格,它们是使用特殊分隔符(比如 ,、| 或 ;)的文本型数据文件。用 UltraEdit 之类的纯文本编辑器打开的样子是这样的:
1.1 读取 CSV 文件
read_csv 是 Pandas 读取 CSV 文件时使用的方法。
import pandas as pd #首先引入pandas包,并称它为pd
fpath=r'e:\tj\zt1802\car.csv' #定义文件所在的位置
df=pd.read_csv(fpath,header=0,index_col=None,encoding='gbk') #read_csv读取数据
encoding='gbk'在这里指定了文件的编码格式,不设置此选项时 Pandas 默认使用 UTF-8 来解码。header=0是指将文件中第 0 行(正常人理解应该是第一行)作为“列名”。如果没有设置则默认取第一行,设置为None的时侯 Pandas 会用自然数 0、1、2……来标识列名。DataFrame 中的列名叫 columns,行名叫 index,因为是用来索引数据。所以 columns 和 index 在 Pandas 中被定成了 “index 类型”。index_col=None的意思是,文件中没有数据作为“行名”index,这时 Pandas 会从 0、1、2、3 做自然排序分配给各条记录。当然也可以取数据中的第一列为行索引index_col=0,比如学号、股票代码、数据库导出数据的主键。- 读出的数据存在名为 df 的 DataFrame 中,可以将 DataFrame 简单理解为一个二维数据表或矩阵。一维向量(或一个序列)在 Pandas 中被称为 Series,DataFrame 的一行或一列就是一个 Series。
- 这里还有一点需要注意,就是没有使用 sep 选项,sep 用来指定数据分割符。如
df=pd.read_csv("e:/tj/zt1802/ins.unl",sep="|"),这里就是明确指定文本数据使用“|”做数据的分割符。我有时侯会用 DbVisualizer 读取数据库数据,然后导出 CSV 文件,因为默认使用 Tab 而不是逗号做了分割符。这时侯 sep 参数就是“/t”。
1.2 读取 Excel 文件
Pandas 读取 Excel 文件的语法格式和读取 CSV 文件是相似的,但使用的 Pandas 方法略有不同,需要使用单独的支持模块 xlrd。如果出现以下类似报错:
ImportError: No module named 'xlrd'
用 pip 安装一下就不会再报错了。
pip install xlrd
Pandas 读取 Excel 的语法如下:
pandas.read_excel(io,sheet_name = 0,header = 0,index_col = None,usecols = None,dtype = None, ...)
#本人常用操作方法
fpath='E:/TJ/xtxy/
vfile='市场表.xlsx'
vdate='2018年9月份'
vdate1='2017年9月份'
sheet1='表1-各主体累计营业收入'
xy18=pd.read_excel(fpath+vdate+vfile, sheetname=sheet1,index_col=[0,1],header=[1,2],skiprows=0,skipfooter=3)
- 这里的 io 就是之前的 fpath,即文件位置。如果文件命名很有规律并且经常使用,可以用字符串拼接方式构造文件位置路径,这样方便换文件和下次再用。
sheet_name = 0是指读取 Excel 文件中的第一个工作表,这里也可以直接指定名字sheet_name = '工作表名称',如果不指定就默认读取第一个。skiprows=0就是读取数据时跳过第一行。这是因为 Excel 第一行为文本标题,如果skipfooter=3,就是跳过数据尾部的 3 行。- 如果数据分析只使用文件中的若干列,那么
usecols=[A:E]很有用了,意思是只读取 A 到 E 列到 Pandas。 dtype参数用来指定特定列的数据类型,参数传递为字典,如{‘a’: np.float64, ‘b’: np.int32}。parse_dates :可以传递一个列表比如 [1,3,5],这样就会把 1、3、5 列作为日期格式传递给 DataFrame,当然也可以后期再改。- 在读文件时你可能发现了,
index_col和header传递了列表index_col=[0,1],header=[1,2]。这表示用 2 行、2 列分别做列索引 column 和行索引 index。这时侯的 column 和 index 被称为 MultiIndex。为了保证源数据的规范整洁,通常是需要避免使用 MultiIndex 的。但在对 Excel 做处理时就无可避免,我们后面很快会说到关于 MultiIndex 的数据筛选。
3. 批量读取数据文件
在实验室或工作场景中经常会遇到处理大量数据结构相同的源数据。怎么批量将这些数据导入同一个 DataFrame 呢?看下面的代码:
#读取数据
import pandas as pd
import numpy as np
import glob,os
path=r'e:\tj\month\fx1809'
file=glob.glob(os.path.join(path, "zk*.xls"))
print(file)
dl= []
for f in file:
dl.append(pd.read_excel(f,header=[0,1],index_col=None))
df=pd.concat(dl)
首先确定自己数据文件的存放位置,然后利用 Python 的 glob 模块,模糊匹配路径下以“zk”开头,且后缀为“.xls”的文件。之后把完整的路径名存储到 file 的列表中。print(file) 可以显示匹配到的文件。

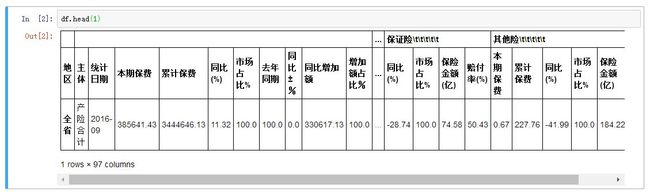
生成一个空列表 dl,利用 append 方法将各个文件分别读入并存储到 dl。dl 列表中的每个元素就是一个 DataFrame。然后利用 concat 方法把这些结构相同的 DataFrame 合并到一起。预览 DataFrame 内容可以使用 df.head(5) 或者 df.tail(1)。
二、数据的处理
了解完基础的数据读取,我们再来试一试利用 NumPy 生成一组实验数据来继续学习。
import numpy as np
import pandas as pd
MyCol=list('ABCDE')
MyIndex=pd.DatetimeIndex(start='2018-01-01',periods=3,freq='D')
df=pd.DataFrame(np.random.rand(15).reshape(3,5),index=MyIndex,columns=MyCol)
生成数据的效果如下:

这一段代码中:
- 这里预先定义了 DataFrame 的 columns 和 index。
DatetimeIndex用来生成日期格式的 index,periods是生成的步长,freq是时间频率(可以选择月 M、日 D、小时 H。同时可以在 M 、D、 H 加上数字,比如 12H,就是生成以 12 小时为间隔的序列)。然后利用pd.DataFrame创建了一个 DataFrame。 random.rand(15)是 NumPy 库用来创建随机数的,reshape(3,5)将矩阵转化成 3 行 x 5 列。pd.DataFrame 如果不设置 columns 和 index 时,columns 和 index 将使用 0、1、2、3 自然数做名字。
目前实验的数据有了,就开始跟着练练一代码吧!
2.1 数据选择之 index 和 column
2.1.1 打印 columns 和 index 的名字
DataFrame 的预览可以使用 head 和 tail 两个方法,当查询特殊行和列时就要用到 index 和 columns 了。首先需要确定的是,这些 index 和 column 的名字是什么呢?
df.columns #显示有哪些列名
df.index #显示index的名字

2.1.2 利用 columns 和 index 检索数据
在知道了 columns 和 index 的名字之后,就可以查询特殊一列或一行了。

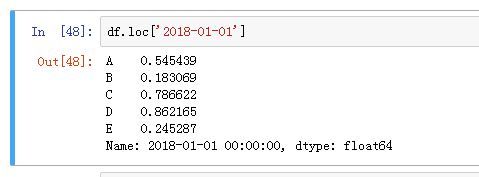
查询行时需要用到 loc 方法,比如查询日期为 2018-01-01 时,使用以下代码:
df.loc['2018-01-01']
2.1.3 检索多行或多列数据
当需要选择多列数据时,需要在列表中传递一个列表,例如:
df[['A','C']]

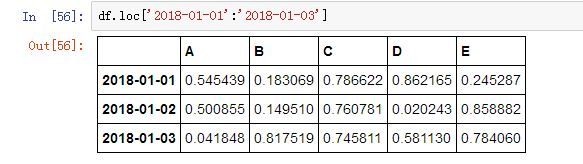
当查询多行时就得使用列表中切片的方法:
df.loc['2018-01-01':'2018-01-03']
2.1.4 iloc 方法选择数据
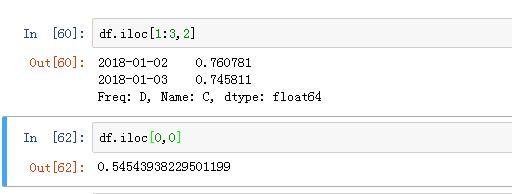
iloc 不使用 index 和 columns 的名字来选择数据,而是用自然数。比如第一行数据用:
df.iloc[0]
选择 0~2 行时用:
df.iloc[0:3]
选择 0 行 0 列对应元素就是:
df.iloc[0,0]
2.1.5 index 和 columns 的重命名
当 index 和 columns 需要重命名时也很简单,直接传递列表就可以:
df.columns=['cat','dog','pig','tiger','monkey']
df.index=['A','B','C']
2.2 MultiIndex 的操作
为了实现在 MultiIndex 的学习,我们利用以下代码生成一些实验数据:
import numpy as np
import pandas as pd
itersA=[['jack','leo','tim'],['A','B','C']]
itersB=[['CA','CB'],['key1','key2']]
idxma=pd.MultiIndex.from_product(itersA,names=['one','two'])
idxmb=pd.MultiIndex.from_product(itersB,names=['first','second']) df=pd.DataFrame(np.random.rand(36).reshape(9,4),index=idxma,columns=idxmb)
数据:

运行 df.columns 和 df.index 可以分别显示列和行的 MultiIndex 的结构:
#df.columns的结构
MultiIndex(levels=[['CA', 'CB'], ['key1', 'key2']],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]],
names=['first', 'second'])
#df.index的结构
MultiIndex(levels=[['jack', 'leo', 'tim'], ['A', 'B', 'C']],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 2], [0, 1, 2, 0, 1, 2, 0, 1, 2]],
names=['one', 'two'])
以 df 的 index 为例:这里面的 levels 是指 index 中各层所包含的元素,index 的 level=0的这一层名字为one,包含元素 ['jack', 'leo', 'tim']。其中 level=1 这一层名字就是 two,元素就是 ['A', 'B', 'C']。labels 显示了各层元素在 index 中的分布情况。
2.2.1 MultiIndex 的列选择操作
在列的 level=0 上选择其中一项:
df['CA']
在列的 level=0 上选择其中多项:
df[['CA','CB']]

同时在列的 level=0 和 level=1 上选择:

但是 df[['CA','CB']][['key1','key2']] 是不可以用的。
2.2.2 MultiIndex 的行选择操作
使用 loc 选择更加灵活一些,下面的代码选择了 index 中 level=0 的’leo’和 columns 中 level=0 的‘CB’。
df.loc['leo','CB']
组合使用 loc 和 slice 来选择数据:
df.loc[(slice('leo','tim'),slice('B','C')),slice(None),slice('key1'))]

2.2.3 使用 xs 进行数据选择
xs 是多重索引取值的另一个工具,需要分别指定索引的标签名,同时说明 level。axis=1 轴为 1 时是在列中操作,axis=0 则是指行。
df.xs('key2',level=1,axis=1)
MultiIndex 操作相对复杂,使用 MulitIndex 一般出现在从 Excel 读取的数据中。对于实验室数据来说,只要保证源数据规范整洁就可不用 MultiIndex。一般来说遵循以下原则对后期数据处理会非常方便。
- 同一个数据表只存储同一实验目的所产生的实验数据。
- 每一个被观测对象只产生一条数据记录。
- 每一个列必须为被观测对像的一个观测属性。
2.3 数据内容相关操作
2.3.1 处理空值和重复记录
了解完基础的数据筛选,那么我们进入数据处理的阶段。在读取 Excel 数据时,可能会遇到空值。空值并不是 0,而是没有数据,在 Pandas 中被表示为 Nan。为了进行统计的方便我们会把空值填充为 0,其它内容,也可能删除掉。这里我们先做一个带有空值的 DataFrame。
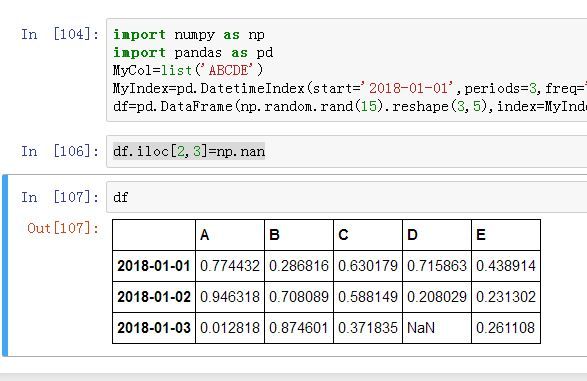
- 查找空值:
df.isnull()会在有空值的位置显示为 True。df.notnull()会把非空值的位置显示为 True,空值的位置显示为 False。df.D.isnull()中的 D 是列标签的名字,这样可以查看某列中的空值。 - 删除空值:
df.dropna(how='any')可以删除空值,how 的参数还可以是 all。any 指记录中只要有一个位置出现空值即删除该记录。all 表示当这一条记录中所有地方都是空值时,才删除记录。这里引申一下去除重复值。自己用代码试一试吧! - 填充空值:
df.fillna(0)这里是指把空值位置变成 0,也可以是其它数。df.fillna(method='ffill')这里是复空值上面的数值,参数为 bfill 是按它后面的值来填充。 - 重复记录:
df.drop_duplicates(keep='first')用来删除重复记录,并且保留重复记录中的第一条记录。当然参数也可以是 last。
2.3.2 利用数据内容进行数据筛选
通过构造一个和数据内容相关的表达式也可以实现数据筛选。df[df['A']>0.5] 会返回df中A列数值大于 0.5 的记录。其中df['A']>0.5 会返回一个包含 True 和 False 的序列,然后 df[df['A']>0.5] 会将表达式返回为 True 的记录筛选出来。当然表达式中的运算符也可以是其它形式,这里简单列几个。
- 等于:==
- 小于于等于:<=
- 不等于:!=
- 为空:isnull()
- 包含在:isin([list])

2.3.3 更改数据
- 类型更改:读 Excel 之后有些数据类型不对,更改方法是使用
astype。df['A']=df['A'].astype(int)这里会把 A 列数据转换为整型数。 - 数值更改:当需要对 DataFrame 中的每一个元素进行修改时,使用
applymap(f)。仅对一个 Series 更改时用apply(f)。这里的 f 是自定义 Python 函数。例如:df.applymap(lambda x: np.round(x*100,2))将每个元素乘 100 后,取到 2 位小数。

2.3.4 简单统计和分组统计
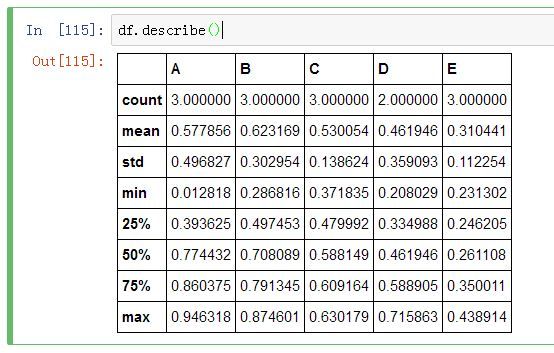
Pandas 本身提供了一个非常简单的统计方法,describe() 可以返回统计的样本数、平均值、标准差、最大值、最小值。
df.describe()
除此之后,还可以自定义统计方法。
- 查行方向中的最大值:
df.max(axis=1) - 求列方向的汇总数据:
df.sum(axis=0) - 求列方向的平均值:
df.mean()不使用 axis 时默认为列方向统计。
分组统计:
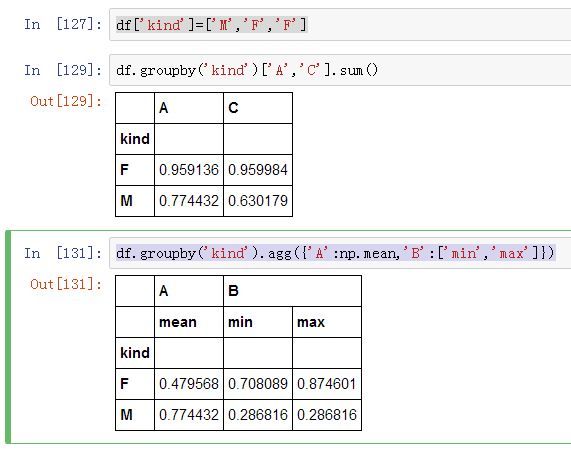
为了进行分组统计,这里在 DataFrame 中虚拟一个可以分组的列叫 kind。

df.groupby('kind')['A','C'].sum()
df.groupby('kind').agg({'A':np.mean,'B':['min','max']})
代码中的 groupby 提供了分组依据,当配合使用 agg 时,可以对不同的列应用不同的统计方法。下例中以 kind 进行分组统计,A 列计算平均值,B 列计算最小、最大值。Pandas 的灵活强大感受到了吗?
2.3.5 DataFrame 的合并
在数据分析中,经常需要合并两个 DataFrame。通常有 2 种方法实现,就是 concat 和 merge。为了能够明显地看出效果,我们做一个 df1,使其和 df 的 column、index 部分一致。

concat 方法:在不定义条件下进行,但会按索引进行自动匹配。遇到不匹配的索引则会增加行或列。效果如下:

merge 方法:在自定义条件下进行,效果如下:
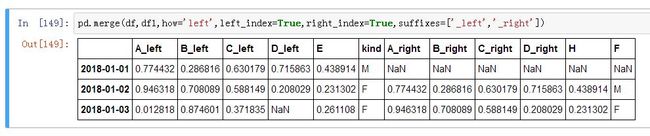
当 how 的参数为 right 时,出来的效果是按 df1 的索引 index 进行匹配;how='full' 时会出现从 2018-01-01 到 2018-01-04 共 4 条记录;当 how='inner' 时出现的仅为 df 和 df1 的 index 的交集。merge 也可以用 left_on='左侧某列' 和 right_on='右侧某列' 来进行匹配。
2.3.6 melt 和 pivot_table
melt:可以用来进行列转换。id_vars 表示用来仍保留为 columns 的列,value_vars 参数中对应列的 columns 名称变成一列参数,其各列对应的数值则变成新的一列,就像做了一锅东北乱炖。简单地说:列变少了,行增加了。
pd.melt(df,id_vars=['kind'],value_vars=['A','B','C','D','E'],var_name='myvar',value_name='myval')

pivot_table:和 Excel 中的数据透视表是一样的,将之前被 melt 的 DataFrame,即现在的 dfm 的中的 kind 列元素变成了 columns,dfm 的 myvar 列变成了 index,数据区域是 myval,在透视过程中进行求和操作(即 np.sum)。
dfm.pivot_table(values='myval',index=['myvar'],columns='kind',aggfunc=np.sum)

2.3.7 导出 Excel 文件
学会上面提到过的 Pandas 用法,就可以做很多工作了。对于处理好的数据如何保存到 Excel 表格中呢?当生成 CSV 文件时用 to_csv 方法,下例中会在 e:/tj/zt1802/ 文件夹下生成一个叫 newdata.csv 的文件。
df.to_csv('e:/tj/zt1802/newdata.csv')
导出 Excel 文件时略复杂:
writer = pd.ExcelWriter("e:/new.xlsx", engine='xlsxwriter')
df.to_excel(writer,sheet_name='df',merge_cells=True)
......
writer.save()
首先创建一个 ExcelWriter 的对象,这个 Excel 文件如果不存在则会新建一个文件。对于存在的文件,to_excel 会把 DataFrame 以追加的形式写进这个文件,在工作簿最后面追加为一个新的工作表。工作表的名称为由 sheet_name 参数来进行自定义。如果 DataFrame 中有 MultiIndex,参数 merge_cells 设置为 True,就可以保证新工作表中写入的数据自动生成带合并单元格式。写完成操作之后,不要忘记用 writer.save() 进行保存关闭。
三、Matplotlib 基础作图
Excel 还有一个强大的功能就是作图!Excel 能做到的,万能的 Python 也可以。但是需要用到 Matplotlib 库。这里我们拿个例子把 Matplotlib 基础作图说一下。
3.1 引入画图包并做全局设置
import seaborn as sns
#seaborn是在Matplotlib上封装的,为了使用其样式我们引入这个包。
import matplotlib
#引入matplotlib
import matplotlib.pyplot as plt
#我们需要用pylplot来画图
sns.set_style("whitegrid")
#我们选whitegrid主题样式
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False
matplotlib.fontsize='20'
#这一段设置了中文支持的字体,字体大小
3.2 建立画布
首先创建 figure 和 axes 实例。figure 是画布,axes 就是画布里的子分区。
fig, axs = plt.subplots(1, 2, figsize=(15,6), sharey=True)
- subplots(1, 2) 创建了包含一行两列的画布,即两个 axes 实例。
- figsize 确定了画布大小,sharey 控制共享坐标轴。如果没有子图,那么 fig=plt.figure() 就可以。
3.3 开始画饼图
labels = list(tpie.index) #label是一个大蛋糕切开后,每一块的名字。
sizes = list(tpie['18年市场占比']) #这里确定了每块重多少。
explode = (0.0,0.0,0.0, 0.0,0.0,0.0) #确定每块离中心位置多远
axs[0].pie(sizes, explode=explode, labels=labels, autopct='%1.2f%%',shadow=False, startangle=45,textprops={'fontsize': 18})
axs[0].set_title('18年1-3季度',fontsize='20')
axs[0].axis('equal')
- axs[0]:表示画布上第一块要画图了,pie 表示饼,plot 是线,bar 是柱。
- autopct:会把 sizes 换算成百分数。
- shadow:确定是否画阴影。
- textprops:配置数据标签字体大小。
- set_title:给第一个子图来个标题。
- axis('equal'):保证画出来的圆不会变扁。
3.4 保存图像
sizes = list(tpie['17年市场占比'])
explode = (0.0,0.0,0.0, 0.0,0.0,0.0)
axs[1].pie(sizes, explode=explode, labels=labels,autopct='%1.2f%%',shadow=False, startangle=45,textprops={'fontsize': 18})
axs[1].set_title('17年1-3季度',fontsize='20')
axs[1].axis('equal')
plt.savefig('e:/tj/month/fx1809/份额.png',dpi=600,bbox_inches = 'tight')
plt.show()
- axs[1]:开始了画第二个子图。
- plt.savefig:用来保存图像,第一个参数是存储文件位置及文件名,dpi 用来确定输出图像分辩率。
- plt.show():在 Jupyter Notebook 中显示图像。
上面这些代码的出图效果如下:

3.5 坐标轴及其它
下面的代码画了一个折线图,我们利用它说一说坐标轴的设置。
x=range(len(t6['统计日期']))
y=t6['承保数量(辆)']
plt.rcParams['figure.figsize'] = (8.0, 4.0)
plt.plot(x,y,marker="*",ms=15)
plt.xticks(x, t6['统计日期'])
#这一段用来添加数据标签。
for x, y in zip(range(len(t6['统计日期'])),t6['承保数量(辆)']):
plt.text(x, y+0.3, str(y), ha='center', va='bottom', ontsize=15.5)
plt.title('近年同期车险市场承保数量',fontsize='20')
plt.margins(0,0)
plt.ylabel('承保数量(辆)',fontsize='15')
plt.xlabel('统计时间',fontsize='15')
plt.ylim((500000,1000000))
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
xticks和yticks分别为横、纵坐标的刻度设置。xlabel和ylabel分别是横、纵坐标轴的名称。xlim和ylim分别是手动调整横、纵坐标轴显示刻度的长度范围。margins(0,0)表示图像不留白边。

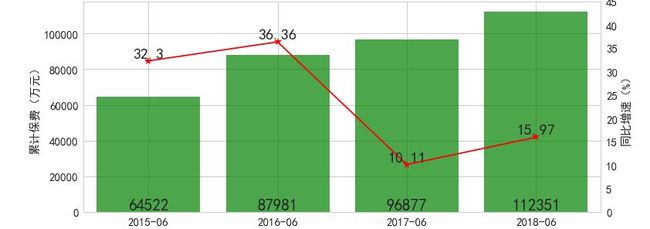
3.6 组合图作图方法
如果要作一个双坐标轴的组合图,需要先在 figure 画布上生成一个 Axes 实例为 ax1、ax1 上画了柱形图。然后再用 twinx 添加一个次坐标轴 ax2。
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.bar(x, y1,alpha=.3,color='b')
ax1.set_ylabel('累计保费(万元)',fontsize='15')
ax1.set_title("保费规模及同比增速对比图",fontsize='20')
plt.yticks(fontsize=15)
plt.xticks(x,t1.index)
plt.xticks(fontsize=15)
ax2 = ax1.twinx() # 添加次坐标轴
ax2.plot(x, y2, 'r',marker='*',ms=10)
ax2.plot(x, y3, 'g')
ax2.set_xlim([-0.5,9.5])
ax2.set_ylim([0,30])
ax2.set_ylabel('同比增速(%)',fontsize='15')
ax2.set_xlabel('同比增速(%)')
到这里,全部内容已结束。希您能为您的工作带来便利和效率。也欢迎大家和我交朋友。
转载:http://blogspring.cn/view/55