识别验证码模拟登录微博
前言:在微博进行模拟登录时需要点击验证码,使用网上打码平台来对验证码进行识别,完成登录。
1.模拟登录:
首先登录微博:https://passport.weibo.cn/signin/login

我们这里使用selenium进行模拟登录
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
browser=webdriver.Chrome()
wait=WebDriverWait(browser,20)
browser.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
username=wait.until(EC.presence_of_element_located((By.ID,'loginName')))
password=wait.until(EC.presence_of_element_located((By.ID,'loginPassword')))
submit=wait.until(EC.element_to_be_clickable((By.ID,'loginAction')))
username.send_keys('用户名')
password.send_keys('密码')
submit.click()
2.获取验证码图片
获取验证码图片有两种方法:
1、先获取整张验证码图片的坐标,然后用image.crop()方法其进行截图;
2、分析网页源代码,找到验证码图片的连接,通过直接获取验证码图片的链接来获得验证码图片;
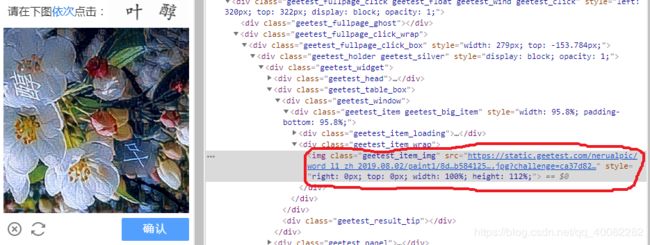
红笔标注的就是就是验证码图片的链接
我们这里采用第二种方法来获取验证码图片,代码如下:
img=wait.until(EC.presence_of_element_located((By.CLASS_NAME,'geetest_item_img')))
src=img.get_attribute('src')#获取链接信息
img_bytes=requests.get(src).content#获取验证码的字节流信息
3.使用超级鹰破解验证码
接下来我们需要将验证码图片的字节流信息发送到在线验证码平台进行识别了;
在做这一步之前我们需要有超级鹰的api以及在官网注册账号和密码;
超级鹰API代码如下(Python3版本):
import requests
from hashlib import md5
class Chaojiying(object):
def __init__(self, username, password, soft_id):
self.username = username
self.password = md5(password.encode('utf-8')).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def post_pic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def report_error(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
在这其中最重要的就是post_pic()方法和report_error();
**post_pic()**方法需要传入图片对象和验证码的类型,该方法会将图片和对象的相关信息发送给超级鹰的后台进行识别,然后将识别成功的JSON返回;
**report_error()**可以在发送错误的时候回调,调用此方法回返回相应的题分。
现在我们将验证码图片信息发送到超级鹰平台进行识别,代码如下:
from Chaojiying import chaojiying
CHAOJIYING_USERNAME='用户名'
CHAOJIYING_PASSWORD='密码'
CHAOJIYING_SOFT_ID=900288
CHAOJIYING_KIND=9102
chaojiying=chaojiying.Chaojiying_Client(CHAOJIYING_USERNAME,CHAOJIYING_PASSWORD,CHAOJIYING_SOFT_ID)
result=chaojiying.PostPic(img_bytes,9004)##返回json格式信息
返回的result信息格式如下:
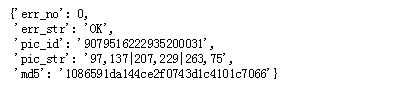
其中pic_str中则是我们需要的识别的验证码文字的坐标,是以字符串形式返回的,我们对其进行解析,代码如下:
#对result进行解析
groups=result.get('pic_str').split('|')
pic_id=result.get('pic_id')
locations=[[int(number) for number in group.split(',')] for group in groups]#返回验证码的坐标信息
4.模拟点击
最后我们使用selenium中的ActionChains进行模拟点击验证码,然后再点击确认按钮即可登录成功;
from selenium.webdriver import ActionChains
for location in locations:
print('开始点击:',location)
ActionChains(browser).move_to_element_with_offset(img,location[0],location[1]).click().perform()
time.sleep(2)
time.sleep(2)
button=browser.find_element_by_class_name('geetest_commit_tip')#点击确认按钮进行登录
button.click()
最后登录成功,验证码破解完成。
5.全部代码
全部代码如下:
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from Chaojiying import chaojiying
from selenium.webdriver import ActionChains
import requests
CHAOJIYING_USERNAME='用户名cjy'
CHAOJIYING_PASSWORD='密码cjy'
CHAOJIYING_SOFT_ID=900288
CHAOJIYING_KIND=9102
USERNAME='用户名wb'
PASSWORD='微博wb'
class CrackWeiboSlide():
def __init__(self):
self.url='https://passport.weibo.cn/signin/login'
self.browser=webdriver.Chrome()
self.wait=WebDriverWait(self.browser,20)
self.username=USERNAME
self.password=PASSWORD
self.chaojiying=chaojiying.Chaojiying_Client(CHAOJIYING_USERNAME,CHAOJIYING_PASSWORD,CHAOJIYING_SOFT_ID)
def __del__(self):
self.browser.close()
def open(self):
'''
打开网页输入用户名密码并点击
:return :None
'''
self.browser.get(self.url)
username=self.wait.until(EC.presence_of_element_located((By.ID,'loginName')))
password=self.wait.until(EC.presence_of_element_located((By.ID,'loginPassword')))
submit=self.wait.until(EC.element_to_be_clickable((By.ID,'loginAction')))
username.send_keys(self.username)
password.send_keys(self.password)
submit.click()
def get_img(self):
'''
查找图片节点
:return: 图片节点'''
img=self.wait.until(EC.presence_of_element_located((By.CLASS_NAME,'geetest_item_img')))
return img
def get_img_bytes(self,img):
'''
获取验证码图片的字节流信息
:img: 图片节点
:return:验证码图片
'''
src=img.get_attribute('src')
img_bytes=requests.get(src).content
return img_bytes
def get_points(self,result):
'''
解析识别结果
:result:返回的识别结果
:return:转化后的结果
'''
groups=result.get('pic_str').split('|')
pic_id=result.get('pic_id')
locations=[[int(number) for number in group.split(',')] for group in groups]
return locations,pic_id
def touch_click_words(self,locations):
'''
点击验证码图片
:param locations:点击位置
:return:None
'''
for location in locations:
print('开始点击:',location)
ActionChains(self.browser).move_to_element_with_offset(self.get_img(),\
location[0],location[1]).click().perform()
time.sleep(1)
def check_login_success(self):
'''
测试是否登录成功
:return:TRUE or False
'''
success=False
try:
self.wait.until(EC.presence_of_element_located((By.CLASS_NAME,'m-text-cut')))
success=True
except:
return success
return success
def main(self):
self.open()
print('开始登录')
tip=self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'geetest_radar_tip')))
tip.click()
time.sleep(6)
img=self.get_img()
button=self.browser.find_element_by_class_name('geetest_commit_tip')
img_bytes=self.get_img_bytes(img)
result=self.chaojiying.PostPic(img_bytes,9004)##返回json格式信息
locations,pic_id=self.get_points(result)#解析识别结果
self.touch_click_words(locations)#进行点击验证码
button.click()
if self.check_login_success():
print('登录成功')
else:
print('登录失败')
self.chaojiying.ReportError(pic_id)
crack.main()
if __name__=='__main__':
crack=CrackWeiboSlide()
crack.main()
运行结果如下所示:

这次登录共点击了验证码上的3个字,坐标如上所示,最终登录成功。