向量实验:相似度算法
向量实验
- 余弦相似度
- 工程应用:新闻分类自动化
- 欧式距离
- 总结
真实世界的数字不只有大小,还要方向!!
一个警察和匪徒在天台上追逐,匪徒跑到围墙边差点掉下去了,幸好还有一只手扣住了墙。

这时候,您该不该救呢?(经典的警匪片里有好多这样的情节。)
- 假如您重 72 72 72 公斤,俩臂伸展为 1.7 1.7 1.7 米, 1.8 1.8 1.8 米的个子,弯腰到 90 90 90 度;
- 而匪徒: 90 90 90 公斤。
估算一下:
- ① 匪徒重心离手应该比警察臂展长
- ② 匪徒又比警察重
- ③ 假设他们的臂展(单位长度)是相同的,但他们之间的夹角是 90º,所以只有合力的 1.4 1.4 1.4 左右
警察要是去救,警察都有可能被拉下去。
现在我们知道了,警察是不能直接上去拉的,但可以想别的方法救。(啧啧,没想到吧)
如果把警察的拉力看成 V 1 V1 V1,匪徒的重量看成 V 2 V2 V2, V 1 V1 V1、 V 2 V2 V2 之间是 90 º 90º 90º,也会产生一个新的力 V 3 V3 V3。
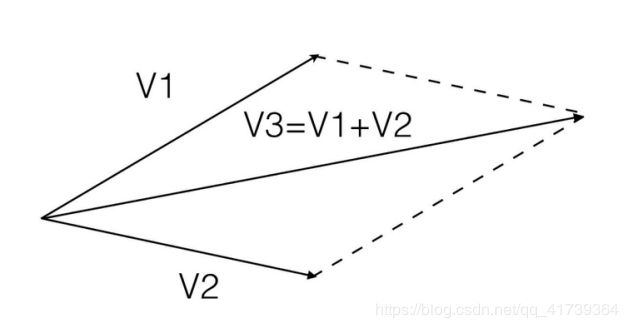
V 1 V1 V1 是警察, V 2 V2 V2 是匪徒,为了凸显方向的作用,我们认为他们的臂展( V 1 V1 V1、 V 2 V2 V2 单位长度 = 1 1 1)是相同的, V 3 V3 V3 的长度就会随方向( V 1 V1 V1、 V 2 V2 V2的夹角)不同而不同:
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 0 º 0º 0º , V 3 = 2 V3 = 2 V3=2
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 30 º 30º 30º, V 3 = 1.93 V3 = 1.93 V3=1.93
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 60 º 60º 60º, V 3 = 1.73 V3 = 1.73 V3=1.73
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 90 º 90º 90º, V 3 = 1.4 V3 = 1.4 V3=1.4
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 120 º 120º 120º, V 3 = 1 V3 = 1 V3=1
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 150 º 150º 150º,V 3 = 0.5 3 = 0.5 3=0.5
- V 1 、 V 2 V1、V2 V1、V2 的夹角是 180 º 180º 180º, V 3 = 0 V3 = 0 V3=0
根据 V 3 V3 V3 的值来看,如果两个向量的夹角超过了 120 º 120º 120º,那么两个力加起来还不如一个力的作用。
可见,方向真的很重要。要形成合力,方向就得一致,方向是怎么样的,就是计算俩个向量间角度。
那怎么计算俩个向量的夹角呢?
数学家把勾股定理一般化,从 90 º 90º 90º 的夹角扩展到 任意大小的角,得到了一个可计算出俩个向量夹角的定理:【余弦定理】。
我们不妨也来推导一下,理解 TA 的来龙去脉。
余弦定理是从勾股定理推过来的,就是三角形有一个直角,第三边长 = c 2 = a 2 + b 2 =c^{2}=a^{2}+b^{2} =c2=a2+b2。
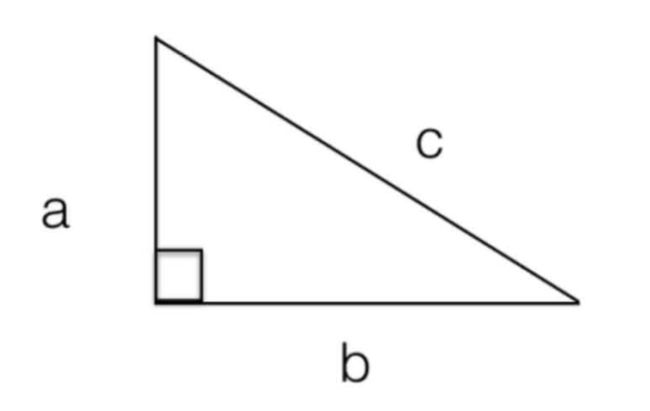
而后,我们把勾股定理一般化,从 90 º 90º 90º 的夹角推广到任意角,勾股定理的变化。
- 如果 a a a 和 b b b 的夹角等于 90 º 90º 90º(直角), a 2 + b 2 = c 2 a^{2}+b^{2}=c^{2} a2+b2=c2
- 如果 a a a 和 b b b 的夹角大于 90 º 90º 90º(锐角), a 2 + b 2 < c 2 a^{2}+b^{2}
- 如果 a a a 和 b b b 的夹角小于 90 º 90º 90º(钝角), a 2 + b 2 > c 2 a^{2}+b^{2}>c^{2} a2+b2>c2
对比一下 a 2 + b 2 、 c 2 a^{2}+b^{2}、c^{2} a2+b2、c2 就知道夹角是什么样的角。
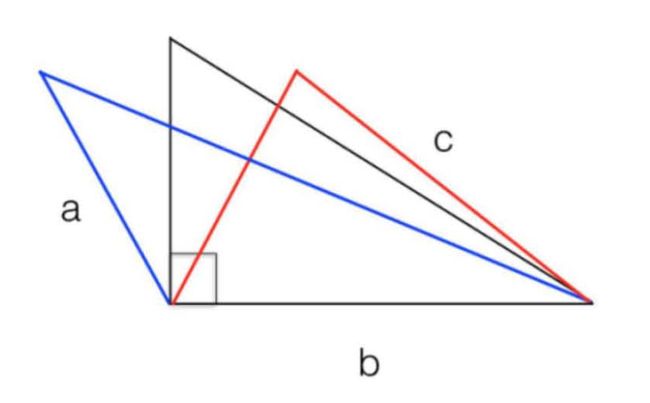
把 c 2 c^{2} c2 移到等式左边, a 2 + b 2 − c 2 = 0 a^{2}+b^{2}-c^{2}=0 a2+b2−c2=0。
将等式左边作为判定因子 Δ \Delta Δ,用 Δ \Delta Δ 和 0 0 0 比较大小,可判定夹角:
- Δ > 0 \Delta > 0 Δ>0,锐角;
- Δ = 0 \Delta = 0 Δ=0, 直角;
- Δ < 0 \Delta < 0 Δ<0,钝角。
如果从函数的角度看,判定因子 Δ \Delta Δ 是 a 、 b 、 c a、b、c a、b、c 三个变量的函数。
对于同样的角度,
- 如果三角形边长比较长,那 Δ \Delta Δ 的动态范围会很大;
- 如果三角形边长比较短,那 Δ \Delta Δ 的动态范围就很小。
我们可以将 Δ \Delta Δ 除以夹角的俩个边长的积 a ∗ b a*b a∗b, Δ \Delta Δ 的动态范围就固定到 [ − 2 , 2 ] [-2, 2] [−2,2]。(这一步的推导可能有疑问,不清楚怎么推的,那可以再思考思考)
- 当 Δ = − 2 \Delta = -2 Δ=−2 时,是 180 º 180º 180º(最大的夹角);
- 当 Δ = 0 \Delta = 0 Δ=0 时,是 90 º 90º 90º。
不知道您有木有想到什么,范围是 [ − 2 , 2 ] [-2, 2] [−2,2]…如果再除以2,范围就是 [ − 1 , 1 ] [-1, 1] [−1,1],这也是夹角的余弦。
我们从勾股定理开始,让 Δ \Delta Δ 和角度的函数用余弦表示出来,这种关系也被称为【余弦定理】。

余弦相似度
那这个会计算向量的夹角有什么用呢,就欣赏一下纯推理吗?
向量在工程中运用的十分广泛,就说计算向量的夹角吧,它就可以进行相似性度量。
相似度度量是计算个体之间相似程度的算法,此类算法多如牛毛,比如余弦相似度。
余弦相似度:用空间中俩个向量夹角的余弦值的大小,来衡量俩个向量间的差异。
多用于处理文字之间相似度的算法。应用有论文查重、文章自动分类、广告推送、订单识别、人群聚类、简历筛选自动化。
工程应用:新闻分类自动化
现在浏览器上的新闻,都是计算机自动分类的,而且就是根据相似度将文章自动分入科技、体育、军事等类别中。
余弦定理可以只靠俩个三角形的俩个边的向量,计算出这俩个边的夹角。
如果我们采用余弦相似度计算相似度,那计算机新闻分类的原理是这样:
一篇新闻里会有很多词,像 “之乎者也的” 这种虚词,对判断新闻的分类没有太大的意义。而像 “股票”、“利息” 这种实词,是判断新闻分类的重点词。
科学家精选了一个词汇表,这里面收录着 64000 64000 64000 个词,每个词都对应一个编号。他们先把大量文字数据输入计算机,算出每个词出现的次数。
一般出现次数越少的词越有搜索价值,比如 “爱因斯坦”、“某个人名”;而出现次数越多的词,越没有搜索价值,比如“一个”、“这里” 等等。
根据这个标准,把词汇表里的 64000 64000 64000 个词都算出各自的权重,越特殊的词权重越大。
然后,再往计算机里输入要分类的新闻,计算出这 64000 64000 64000 个词在这篇新闻里的分布,如果某些词没有在这篇新闻里出现,对应的值就是零,如果出现,对应的值就是这个词的权重。
这样,这 64000 64000 64000 个数,就构成了一个 64000 64000 64000 维的向量,我们就用这个向量来代表这篇新闻,把它叫做这篇新闻的特征向量。
不同类型的新闻,用词上有不同的特点,比如金融类新闻就经常出现 “股票”、“银行” 这些词,所以不难判断,同类新闻的特征向量会有相似性。
只要算出不同新闻特征向量之间夹角的大小,就可以判断出是不是同一类新闻。
这时就要用到余弦定理,来把两则新闻的特征向量之间的夹角算出来。
科学家可以人工设定一个值,只要两个向量之间的夹角小于这个值,这两则新闻就可以判定成同一类新闻。
在向量中公式转换为:
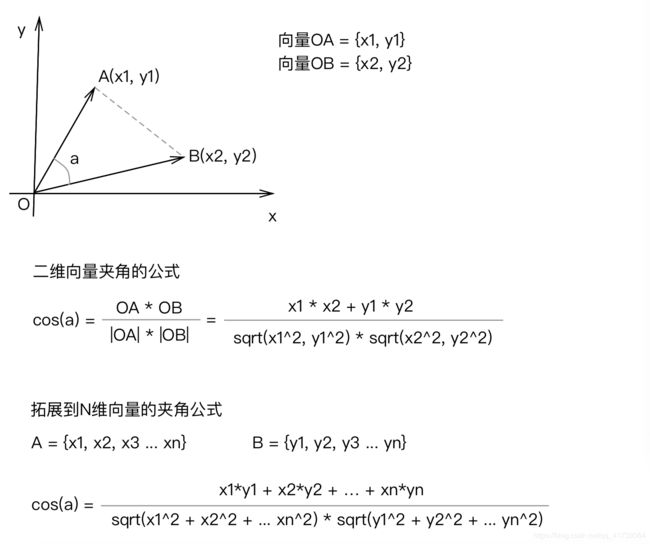
再把公式翻译为 C++ 代码:
double CosSimilarity(double *va, double *vb, int vn) {
// vn 是多少维,也就是词典中有多少个词
double cossu = 0.0;
double cossda = 0.0;
double cossdb = 0.0;
for (int i = 0; i < vn; i++) {
cossu += va[i] * vb[i];
cossda += va[i] * va[i];
cossdb += vb[i] * vb[i];
}
return cossu / (sqrt(cossda) * sqrt(cossdb));
}
测试用例:
- 文 件 1 文件1 文件1 的内容是:口径为 155 155 155 毫米的榴弹炮,炮弹的射程超过 40 40 40 公里,炮弹发射后击中目标的弹道是一条抛物线
- 文 件 2 文件2 文件2 的内容是:大口径榴弹炮射程很远且弹道弯曲,炮弹通常都不是直接对着目标瞄准,而是计算好抛物线弹道,以一定的仰角和方向发射炮弹
- 文 件 3 文件3 文件3 的内容是:我们必须统一口径,抵挡敌人发射的糖衣炮弹的进攻
#include 新闻分类的步骤:
- 建立词典
- 词频统计(如果是中文,数据得先经过中文分词)
- 计算余弦相似性
- 根据相似度做判断,余弦相似度,值越大(越接近 1 1 1)就表示越相似。
原理就是这样,现在把这个项目完整的写出来:
// 运行:可打开命令行,输入 g++ -std=c++11 当前源文件.cpp
#include 除此之外,还有论文查重、文章自动分类、广告推送、订单识别、人群聚类、简历筛选自动化都是相似度问题。
-
论文查重:是把统一的字典改为从两篇文章中整理关键词汇或者俩篇文章中所有词汇,合并成一个字典即可。
-
文章自动分类:建立各个领域的词典,上面我们只有一个军事新闻的字典,而且只计算了一次;实现文章字典分类得所有领域都计算一次,分到相似度最高的领域即可。
-
广告推送、订单识别:也会用到文本相似度的判断。
-
简历筛选自动化:类似。
向量不仅可以对新闻分类,对人也可以分类。
现在大公司在招聘伙伴时,由于简历特别多,会先用计算机筛选简历。
原理:先把简历向量化,而后计算夹角。
把各种技能和素质列在一张表里,这个表就有 N N N 个维度啦。
而后不同岗位因为评比的方式不同,某些向量的权值就很高,一些就很低甚至是零。
比如,开发人员的权值:
- 编程能力: 4 4 4
- 工程经验: 2 2 2
- 沟通能力: 1 1 1
- 学历: 1 1 1
- 领导力: 1 1 1
- 企业文化融合度: 1 1 1
接下来计算机会对每份简历进行分析,把每份简历变成一个 N N N 维的向量,假设是 P P P。
计算 P P P、 V V V 的夹角,如果夹角非常小说明某一份简历和某一个岗位比较匹配,这时简历才会递给 H R HR HR。
所以,写给大公司的简历,一定要突出重点。别把自己描述为全能的,不然直接被计算机卡死啦,最好是先打探内部消息,知道这家公司看重什么维度,我再往上面写。
欧式距离
除此余弦距离之外,向量也是空间中的一个点;既然是一个点,就可以结合 欧式距离。
相对于欧式距离,余弦距离注重的是俩个向量在方向上的差异(注重的是方向),对绝对数值(距离)不敏感。
- 向量夹角越大(方向差异越大),余弦值 c o s θ cos \theta cosθ 就会越小(相似性越小);
- 向量夹角越小(方向差异越小),余弦值 c o s θ cos \theta cosθ 就会越大(相似性越大);
欧式距离度量:注重每份数据的绝对数值差异(距离),对方向不敏感。
多用在从数值大小的发现特征的算法,如根据用户的行为数据分析用户的价值大小、评估用户消费能力算法。
举个例子,这是上月用户对商品的评分数据:

先让数据转为向量形式:
张三: ∥ 1 1 ∥ \begin{Vmatrix} 1 \\ 1\\ \end{Vmatrix}~~~~~~~~~~~~ ∥∥∥∥11∥∥∥∥ 李四: ∥ 5 5 ∥ \begin{Vmatrix} 5 \\ 5\\ \end{Vmatrix}~~~~~~~~~~~~ ∥∥∥∥55∥∥∥∥ 王五: ∥ 5 0 ∥ \begin{Vmatrix} 5\\ 0\\ \end{Vmatrix}~~~~~~~~~~~~ ∥∥∥∥50∥∥∥∥
我们要对评分的用户进行分类(人群聚类算法)。
物以类聚,人以群分。这种分类看的就是一种相似度,所以我们可以使用相似度算法。
但该使用哪种相似度算法呢?
- 余弦距离注重的是方向,相似度是由俩个向量间的夹角决定的;
- 欧式距离注重的是距离,相似度是由俩个向量间的距离决定的;
可以给您一个提示,可供对比。
这是用户的消费数据:

先让数据转为向量形式:
- 张三: ∥ 2 10 ∥ \begin{Vmatrix} 2 \\ 10\\ \end{Vmatrix}~~~~~~~~~~~~ ∥∥∥∥210∥∥∥∥ 李四: ∥ 20 100 ∥ \begin{Vmatrix} 20 \\ 100\\ \end{Vmatrix}~~~~~~~~~~~~ ∥∥∥∥20100∥∥∥∥ 王五: ∥ 3 15 ∥ \begin{Vmatrix} 3 \\ 15\\ \end{Vmatrix} ∥∥∥∥315∥∥∥∥
我们要通过它,评估用户消费能力。
原理:让选一个标准让所有用户和标准比,超过那个标准标为高消费人群,就多多推荐商品出去。
显然,评估用户消费能力也是一个相似性度量问题,但和人群聚类算法有什么不同呢?
问题在于,您可不可以看出这俩个算法的核心因素是什么,是计算距离,还是计算方向!!
评估用户消费能力,让选一个标准让所有用户和标准比,超过那个标准标为高消费人群,就多多推荐商品出去。
评估用户消费能力也是一个相似性度量问题,那是用欧式距离还是用余弦距离呢???
这就要看我们收集的数据,只有消费数据和总消费额,如果使用余弦相似度那张三和李四的结果是相同的,显然不能采用,因为李四消费水平高了一个量级,在绝对数值方面,选欧式距离才能得出用户真正的消费能力。
# 运行:在命令行输入 python 当前源文件.py
import numpy as np
import matplotlib.pyplot as plt
# 欧式距离,核心算法
def dist(vec1,vec2):
return np.sqrt(np.sum(np.square(vec1-vec2)))
# 用户数据
a_1 = np.array([2,10]) # 张三
b_1 = np.array([20,100]) # 李四
c_1 = np.array([3,15]) # 王五
print("dist(a_1,b_1) = ",dist(a_1,b_1)) # 比较张三、李四
print("dist(a_1,c_1) = ",dist(a_1,c_1))
print("dist(b_1,c_1) = ",dist(b_1,c_1))
# 数据可视化
plt.xlim(0, 30) # x 轴大小
plt.ylim(0, 110) # y 轴大小
plt.grid(color='#A9A9A9')
plt.plot(a_1[0],a_1[1],'ro') # 把张三的数据标为红点
plt.plot(b_1[0],b_1[1],'go') # 把李四的数据标为绿点
plt.plot(c_1[0],c_1[1],'bo') # 把王五的数据标为蓝点
plt.show()
俩俩对比的结果:
![]()
可视化展示:
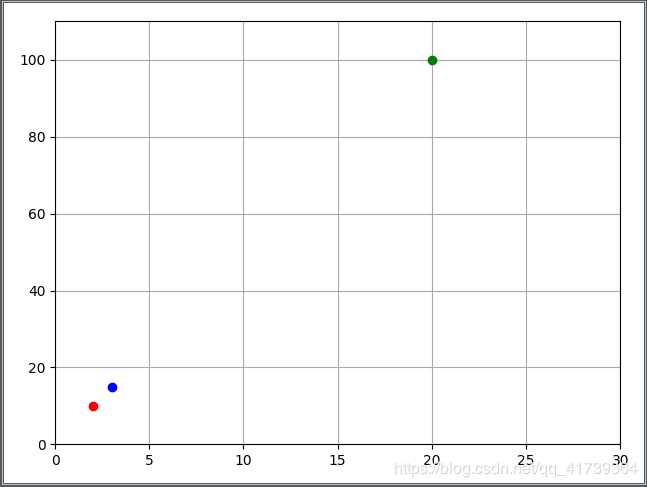
对标数轴的 x,y 就知道点是谁了,如绿点 ( 20 , 100 ) (20,100) (20,100) 就是李四。
绿 点 > 蓝 点 > 红 点 绿点 > 蓝点 > 红点 绿点>蓝点>红点,因此,李四的消费能力 > 王五的消费能力 > 张三的消费能力,商家应该把产品优先推给 李 四 李四 李四。
其实这三个点都在一条直线上,因此 余弦值 c o s θ cos\theta cosθ 是零,采用余弦相似度是不行的。
欧式距离注重每份数据的绝对差异(距离),多用在从数值大小的发现特征的算法,如根据用户的行为数据分析用户的价值大小。
物以类聚,人以群分 — 这样的分法,不是注重用户绝对的数值,而是方向。
那,应采用余弦距离。
就上图而言,张三和李四的方向相同,分为一类,王五的方向则不同,就是另一类。
# 运行:在命令行输入 python 当前源文件.py
import numpy as np
import matplotlib.pyplot as plt
# 余弦相似度,核心算法
def Sim(vec1,vec2):
return np.dot(vec1,vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# 用户数据
a_2 = np.array([1,1]) # 张三
b_2 = np.array([5,5]) # 李四
c_2 = np.array([5,0]) # 王五
print("sim(a_2,b_2) = ",Sim(a_2,b_2)) # 比较张三、李四
print("sim(a_2,c_2) = ",Sim(a_2,c_2))
print("sim(b_2,c_2) = ",Sim(b_2,c_2))
# 数据可视化
plt.xlim(0, 6)
plt.ylim(0, 6)
plt.grid(color='#A9A9A9')
plt.plot(a_2[0],a_2[1],'ro') # 把张三的数据标为红点
plt.plot(b_2[0],b_2[1],'go') # 把李四的数据标为绿点
plt.plot(c_2[0],c_2[1],'bo') # 把王五的数据标为蓝点
plt.show()
俩俩对比的结果:
![]()
可视化展示:
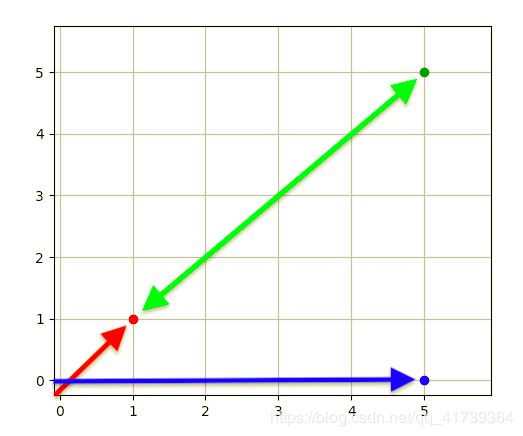
- 绿 点 : 李 四 绿点:李四 绿点:李四
- 红 点 : 张 三 红点:张三 红点:张三
- 蓝 点 : 王 五 蓝点:王五 蓝点:王五
红点和绿点是在同一条线上,因此归为一类,而蓝点所在的线刚好是 x x x 轴,是另一类。
余弦相似度注重的是方向,对绝对数值不敏感,多用在用户对内容评分的数据来分析兴趣差异。
总结
向量的夹角计算通常用于相似算法,用于判断相似度的理论有很多,比如欧氏距离(欧氏相似度)、余弦距离(余弦相似度)、 J a c c a r d Jaccard Jaccard 距离、编辑距离等。
我们主要学习了余弦距离:
- 向量夹角越大(方向差异越大),余弦值 c o s θ cos \theta cosθ 就会越小(相似性越小);
- 向量夹角越小(方向差异越小),余弦值 c o s θ cos \theta cosθ 就会越大(相似性越大);
余弦相似度,值越大(越接近 1 1 1)就表示越相似。
而后,对比了余弦、欧式距离:
- 欧式距离:注重的是方向(俩个向量夹角),多用在从向量的方向发现特征的算法;
- 余弦距离:注重的是距离(绝对数值方面),多用在从数值的大小发现特征的算法。
这些只是我知道一点向量的工程应用,欢迎您补充,我也想 G e t Get Get 新知识。