爬虫入门教程⑩— 用漂亮的图表展示爬取到的数据
经过了前面的努力,我们成功获取到了数据,并且学会了保存,但是只是用网页展示出来,是不是有一些不够美观呢?
所以本节的内容是:数据的可视化。拿到了数据却不能使其简单易懂并且足够突出,那就是不是好的数据工程师。
效果图:

安装pyecharts这个Python的图表库,在之前我们安装了requests、lxml、bs4。所以只需要再在cmd里面 pip3
install pyecharts 就OK啦,如果失败,请仔细阅读教程:爬虫入门教程⑥—安装爬虫常用工具包
pyecharts简介:
这是百度echarts图表库,使用Python接口进行生成图表的一个库,非常炫酷。在之前绘图基本上是用的【Matplotlib】这个库,这个库功能非常强大,但是缺点也比较明显,api调用比较复杂,新手上手很慢也很难。于是在去年,陈键冬大佬推出了一个简单易用的绘图库 pyecharts。
我当时怀着试一试的心情使用了一下,哇,超好用的,对新手超友好的,代码和图都写出来了,非常详细,同时配置项也非常清晰。一口气画5个图都超快超简单的~!
确定可视化的目标
这是很重要的一步,先确认哪些数据值得拿来可视化,然后再去编写代码。一部电影的信息有:名字、上映日期、地区、类型、关注者数量。最明显的当然是关注者数量排行榜(柱状图),除此之外我还想了几个:
上映电影类型占比(饼图)
上映地区占比(饼图)
上映日期柱状图
采集所有电影信息
先上之前的代码:
采集所有电影信息
先上之前的代码:
import requests
from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup
#请求网页
url = "https://movie.douban.com/cinema/later/chengdu/"
response = requests.get(url)
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
all_movies = soup.find('div', id="showing-soon") # 先找到最大的div
for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div
# print(each_movie) # 输出每个影片div的内容
all_a_tag = each_movie.find_all('a')
all_li_tag = each_movie.find_all('li')
movie_name = all_a_tag[1].text
moive_href = all_a_tag[1]['href']
movie_date = all_li_tag[0].text
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text
print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers))
这是数据的基础信息,我们先全部拿到,然后放进一个list,方便后续的比较分析处理。同时我们在代码顶部,从pyecharts引入Page(在一张图显示多个图表)、Pie(饼图)、Bar(柱状图)。
# 可视化爬取结果
import requests
from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup
from pyecharts import Page, Pie, Bar # 引入绘图需要的模块
#请求网页
url = "https://movie.douban.com/cinema/later/chengdu/"
response = requests.get(url)
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
all_movies = soup.find('div', id="showing-soon") # 先找到最大的div
# 先把所有的数据存到这个list里面
all_movies_info = []
for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div
# print(each_movie) # 输出每个影片div的内容
all_a_tag = each_movie.find_all('a')
all_li_tag = each_movie.find_all('li')
movie_name = all_a_tag[1].text
moive_href = all_a_tag[1]['href']
movie_date = all_li_tag[0].text
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text.replace('人想看', '') # 去掉除了数字之外的字
# 把电影数据添加到list
all_movies_info.append({'name': movie_name, 'date': movie_date, 'type': movie_type,
'area': movie_area, 'lovers': movie_lovers})
# print('名字:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
# movie_name, movie_date, movie_type, movie_area, movie_lovers))
print(all_movies_info) # 输出一下检查数据是否传递成功
绘制关注者排行榜
处理逻辑:首先把所有的电影以关注者数量排个序,然后从所有电影里面以获取到电影的名字和电影的关注者数量,最后添加到柱状图里。
sorted函数,第一个参数接受一个可以遍历的对象,key参数接受一个匿名函数,用以指定以遍历对象内的哪个元素作为排序的依据
以下代码添加到上一个示例代码后面即可。
# 绘制关注者排行榜图
# i['name'] for i in all_movies_info 这个是Python的快捷方式,
# 这一句的作用是从all_movies_info这个list里面依次取出每个元素,
# 并且取出这个元素的 name 属性
sort_by_lovers = sorted(all_movies_info, key=lambda x: int(x['lovers']))
all_names = [i['name'] for i in sort_by_lovers]
all_lovers = [i['lovers'] for i in sort_by_lovers]
lovers_rank_bar = Bar('电影关注者排行榜') # 初始化图表,给个名字
# all_names是所有电影名,作为X轴, all_lovers是关注者的数量,作为Y轴。二者数据一一对应。
# is_convert=True设置x、y轴对调,。is_label_show=True 显示y轴值。 label_pos='right' Y轴值显示在右边
lovers_rank_bar.add('', all_names, all_lovers, is_convert=True, is_label_show=True, label_pos='right')
lovers_rank_bar # jupyter下直接显示图表在输出框内
运行截图:
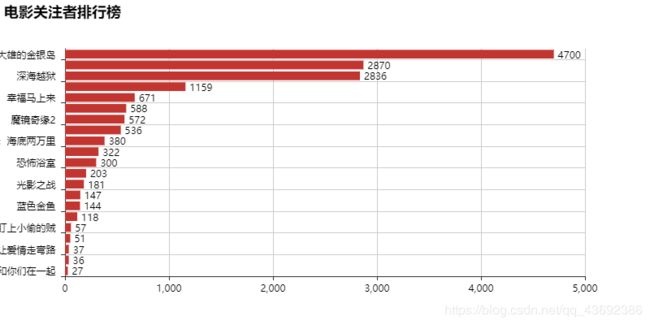
绘制电影类型占比图
我们先从所有电影里获取所有的电影类型(一个电影可能有多个类型,比如动画 / 奇幻 / 冒险,就需要先分割成3个);然后通过代码统计这些类型的数量,最后绘制成饼图。代码同样添加到之前的代码之后就OK。
# 绘制电影类型占比图
all_types = [i['type'] for i in all_movies_info]
type_count = {}
for each_types in all_types:
# 把 爱情 / 奇幻 这种分成[爱情, 奇幻]
type_list = each_types.split(' / ')
for e_type in type_list:
if e_type not in type_count:
type_count[e_type] = 1
else:
type_count[e_type] += 1
# print(type_count) # 检测是否数据归类成功
type_pie = Pie('上映类型占比', title_top=20) # 因为类型过多影响标题,所以标题向下移20px
# 直接取出统计的类型名和数量并强制转换为list。
type_pie.add('', list(type_count.keys()), list(type_count.values()), is_label_show=True)
type_pie # jupyter下直接显示
效果:
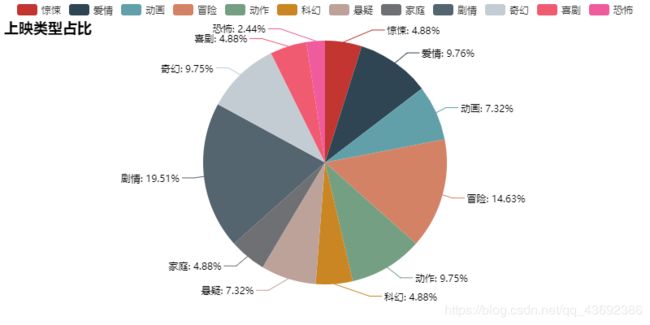
绘制上映日期图
类似于上一个步骤,我们同样拿到所有的上映日期并做一个数量统计再添加到条形图就OK了。代码同样也是添加到上面的代码之后就OK了。
# 绘制电影上映日期柱状图
all_dates = [i['date'] for i in all_movies_info]
dates_count = {}
for date in all_dates:
if date not in dates_count:
dates_count[date] = 1
else:
dates_count[date] += 1
# print(dates_count) # 输出验证数据是否正确
dates_bar = Bar('上映日期占比')
dates_bar.add('',list(dates_count.keys()), list(dates_count.values()), is_label_show=True)
dates_bar # jupyter下直接显示
效果图:
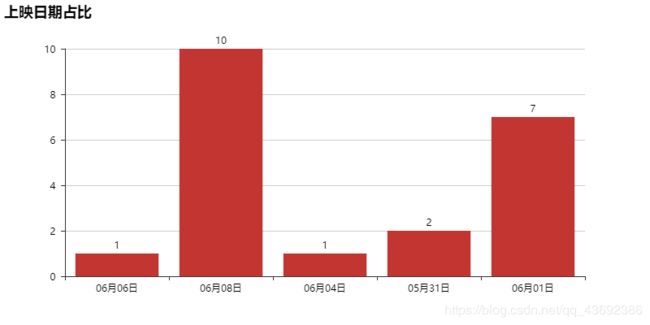
完整代码
要把所有的图表都添加到一起一次性输出,那么就需要使用Page这个类,把图表加进去,这些图表就会按照添加顺序,挨个展示。完整代码如下:
等下,遇到了问题,运行报错了(获取上映日期代码报错list out of range:也就是我们要第四个元素,但是它只有3个元素,所以超过了range),发现是过了12点,豆瓣更新了2部电影,这两部电影,没有上映日期~!所以更改了一点代码以增强兼容性。爬虫就是这样,网页结构变化了,代码就要修改。所以这个工作还是可以做得比较久的。
# 可视化爬取结果
import requests
from bs4 import BeautifulSoup # 从bs4引入BeautifulSoup
from pyecharts import Page, Pie, Bar
#请求网页
url = "https://movie.douban.com/cinema/later/chengdu/"
response = requests.get(url)
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
all_movies = soup.find('div', id="showing-soon") # 先找到最大的div
all_movies_info = []
for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div
# print(each_movie) # 输出每个影片div的内容
all_a_tag = each_movie.find_all('a')
all_li_tag = each_movie.find_all('li')
movie_name = all_a_tag[1].text
moive_href = all_a_tag[1]['href']
# 运行报错 index out of range:是因为有电影没显示日期
if len(all_li_tag) == 4:
movie_date = all_li_tag[0].text
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text.replace('人想看', '')
else: # 网站结构改变,跟着改变代码
movie_date = "未知"
movie_type = all_li_tag[0].text
movie_area = all_li_tag[1].text
movie_lovers = all_li_tag[2].text.replace('人想看', '')
all_movies_info.append({'name': movie_name, 'date': movie_date, 'type': movie_type,
'area': movie_area, 'lovers': movie_lovers})
# print('名字:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
# movie_name, movie_date, movie_type, movie_area, movie_lovers))
# print(all_movies_info) # 输出一下检查数据是否传递成功
page = Page() # 同一个网页显示多个图
# 绘制关注者排行榜图
# i['name'] for i in all_movies_info 这个是Python的快捷方式
# 这一句的作用是从all_movies_info这个list里面依次取出每个元素,
# 并且取出这个元素的 name 属性
sort_by_lovers = sorted(all_movies_info, key=lambda x: int(x['lovers']))
all_names = [i['name'] for i in sort_by_lovers]
all_lovers = [i['lovers'] for i in sort_by_lovers]
lovers_rank_bar = Bar('电影关注者排行榜')
lovers_rank_bar.add('', all_names, all_lovers, is_convert=True, is_label_show=True, label_pos='right')
page.add(lovers_rank_bar)
# lovers_rank_bar
# 绘制电影类型占比图
all_types = [i['type'] for i in all_movies_info]
type_count = {}
for each_types in all_types:
# 把 爱情 / 奇幻 这种分成[爱情, 奇幻]
type_list = each_types.split(' / ')
for e_type in type_list:
if e_type not in type_count:
type_count[e_type] = 1
else:
type_count[e_type] += 1
# print(type_count) # 检测是否数据归类成功
type_pie = Pie('上映类型占比', title_top=20)
type_pie.add('', list(type_count.keys()), list(type_count.values()), is_label_show=True)
# type_pie
page.add(type_pie)
# 绘制电影上映日期柱状图
all_dates = [i['date'] for i in all_movies_info]
dates_count = {}
for date in all_dates:
if date not in dates_count:
dates_count[date] = 1
else:
dates_count[date] += 1
# print(dates_count) # 输出验证数据是否正确
dates_bar = Bar('上映日期占比')
dates_bar.add('',list(dates_count.keys()), list(dates_count.values()), is_label_show=True)
# dates_bar
page.add(dates_bar)
page # jupyter下自动显示
简单的分析
关注者排行榜图里,大雄的金银岛,6.1上映,关注人数4700,当之无愧的最火最期待的电影,毕竟是这么多快到中年的年轻人小时候很喜欢的动漫,并且也几乎从来没让人失望过。
上映电影类型图里,最多的是剧情类,不过这个标签比较平常,所以略过。剩下最多的就是冒险和动漫了,这个也和最近的日子有关系,毕竟明天就儿童节了,所以大部分电影和儿童、少年沾边了。
上映日期也表明了,大部分电影在6.1和6.8上映。6.1儿童节,大家容易理解,6.8呢?6.8是高考结束的那天啊!!!广大高三学子终于解放了!!!解放了肯定就要看看电影啊~作为一个即将毕业的老人,提前恭祝广大学子高考金榜题名!
后记
爬虫入门教程就到此为止了,非常高兴能够和大家一起分享知识。一起学习Python爬虫,把这门实用又有趣的技术,通过简单的代码,向各位展示出来。希望各位能从这个小小的爬虫教程中,获取到一点编程的乐趣,也了解一下为什么Life is short, I use Python是Python的slogan。
所以我真的太喜欢Python了。本着分享技术的精神,向各位从爬虫的概念,基础知识,编码,数据提取,数据可视化,简单数据分析 向大家介绍了Python爬虫方面的简单知识。如果这几篇文章能够让你对代码,对爬虫,对Python产生一点积极的作用,那我会觉得非常开心!
Python的禅宗三字经——蒂姆•彼得斯
优美胜于丑陋,
明了胜于晦涩,
简洁胜于复杂,
复杂胜于凌乱,
间隔胜于紧凑,
可读性很重要,
即便假借特例的实用性之名,也不可违背这些规则,
不要包容所有错误,除非你确定需要这样做,
当存在多种可能,不要尝试去猜测 ,
而是尽量找一种,最好是唯一一种明显的解决方案,
虽然这并不容易,因为你不是 Python 之父。
做也许好过不做,但不假思索就动手还不如不做,
如果你无法向人描述你的方案,那肯定不是一个好方案;
反之亦然,命名空间是一种绝妙的理念,我们应当多加利用
是的,在Python任何版本,代码里面输入import this,就会出现Python的格言。意在劝告人们写Python要遵循的规则,也就是写代码要pythonic~!
In [1]: import this
"""
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""