TCP减压引擎,第一次听说这个名词,但是并不是一个新的概念了,若干年前听说过设备厂商在研究在FPGA之中实现TCP Stack,但是后来没有听到任何的产品出来,应该是路由设备to host的traffic不多,而对于FW设备,中间的TCP Proxy实现过于复杂,工程上不可能实现。
现在的所谓TOE实现我理解主要用于host的interface之中,用于为Gbits以及10Gbits接口场景中为CPU减压,例如部署在数据中心内部的服务器,CPU虽然越来越快,但是对于汹涌澎湃的Traffic来说,还是有些力不从心。
上面是TOE应用前后协议栈的差别,我觉得画的有点绝对,TCP Stack不太可能完全实现在interface之中,其实TOE主要实现如下的offload:
1.TCP/IP Checksum offload
CPU可以不用计算checksum而由网卡计算
2.CPU不用考虑数据的分段了,估计是直接将socket送过来的buf交给网卡。
如果是仅仅实现上述功能TOE是很可能工程化实现的。
在另一篇文档中提到了TOE的一些优势,但是我的分析,这个可能是要实现TOP替代整个TCP之后的优势。
1.减少中断:不用每个报文都产生中断,如果10G接口这个对于CPU是很大的开销。
2.减少memory拷贝次数,很多时候网卡的buffer和app的可以直接共享。
3.协议处理的节约,这个是当然的了。
显而易见TOE有一些问题。
1.没有标准,导致协议栈实现困难,无法标准化的进行剪裁
2.硬件中实现,有bug怎么办?
TCP/IP 协议早已是网络的标准语言。随着Internet SCSI、Remote Diret Memory Access这些网络存贮标准的问世和实用化,从某种意义上说,TCP/IP又成了一种存贮协议。
我们知道,用TCP/IP协议处理网络流量,要占用大量服务器资源。为了减轻服务器的压力,一种称为TCP减负引擎(TCP Offload Engine :TOE)的技术应运而生。TCP减负引擎一般由软硬两部分组件构成,将传统的TIP/IP协议栈的功能进行延伸,把网络数据流量的处理工作全部转到网卡上的集成硬件中进行,服务器只承担TCP/IP控制信息的处理任务。这种为服务器减轻负担的技术,得到了大多数厂商的肯定。
普通网卡用软件方式进行一系列TCP/IP相关操作,因此,会在三个方面增加服务器的负担,这三个方面是:数据复制、协议处理和中断处理。
网络上每个应用程序在收发大量数据包时,要引发大量的网络I/O中断,对这些I/O中断信号进行响应,成了服务器的沉重负担。比如,一个典型的 64Kbps的应用程序在向网络发送数据时,为了将这些数据装配成以太网的数据包,并对网络接收确认信号进行响应,要在服务器和网卡间触发60多个中断事件,这么高的中断率和协议分析工作量已经是相当可观的了。虽然某些网络操作系统具有中断捆绑功能,能够有效减少中断信号的产生,但却无法减少服务器和网卡间响应事件的处理总量。
TCP减负引擎网卡的工作原理与普通网卡不同。普通网卡处理每个数据包都要触发一次中断,TCP 减负引擎网卡则让每个应用程序完成一次完整的数据处理进程后才触发一次中断,显著减轻服务器对中断的响应负担。还是以64Kbps的应用程序为例,应用程序向网络发送数据全部完成后,才向服务器发送一个数据通道减负事件中断,数据包的处理工作由TCP减负引擎网卡来做,而不是由服务器来做,从而消除了过于频繁的中断事件对服务器的过度干扰。网络应用程序在收发数据时,经常是同一数据要复制多份,在这种情形下,TCP减负引擎网卡发挥的效益最明显。
普通网卡通过采用支持校验功能的硬件和某些软件,能够在一定程度上减少发送数据的复制量,但却无法减少接收数据的复制量。对大量接收数据进行复制通常要占用大量的机器工作周期。普通网卡先将接收到的数据在服务器的缓冲区中复制一份,经系统处理后分配给其中一个TCP连接,然后,系统再将这些数据与使用它的应用程序相关联,并将这些数据由系统缓冲区复制到应用程序的缓冲区。TCP减负引擎网卡在接收数据时,在网卡内进行协议处理,因此,它不必将数据复制到服务器缓冲区,而是直接复制到应用程序的缓冲区,这种“零拷贝”方式避免了网卡和服务器间的不必要的数据往复拷贝。
TCP减负引擎网卡能显著减轻由数据大量移动造成的服务器过载负担。实测证明,对于文件服务器和以内容服务为主的服务器应用环境来说,如果用TCP减负引擎网卡代替普通网卡,相当于为服务器增加了一个CPU
对于网络安全来说,网络传输数据包的捕获和分析是个基础工作,绿盟科技研究员在日常工作中,经常会捕获到一些大小远大于MTU值的数据包,经过分析这些大包的特性,发现和网卡的offload特性有关,本文对网卡Offload技术做简要描述。
网络分片技术
MTU
最大传输单元,指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位)。
在以太网通信中,MTU规定了经过网络层封装的数据包的最大长度。例如,若某个接口的MTU值为1500,则通过此接口传送的IP数据包的最大长度为1500字节。
小编注:对于普通用户来说,如果你优化过迅雷的下载速度,可能通过这篇文章《合理设置MTU,提升下载速度》,对MTU的基础知识有所了解。
IP分片
当IP层需要传送的数据包长度超过MTU值时,则IP层需要对该数据包进行分片,使每一片的长度小于或等于MTU值。在分片过程中,除了对payload进行分片外,数据包的IP首部也需要进行相应的更改:
- 将identifier字段的值复制给每个分片;
- 将分片数据包的Flags中的DF位置为0;
- 除最后一个分片之外的其他分片,将MF位置为1;
- 将Fragment Offset字段设置正确的值。
MSS
最 大分段长度,TCP数据包每次能够传输的最大数据分段长度,在TCP协议的实际实现中,MSS往往用MTU-(IP Header Length + TCP Header Length)来代替。在TCP通信建立连接时,取两端提供的MSS的最小值作为会话的MSS值。由于TCP分段有MSS值的限制,通常情况下TCP数据 包经IP层封装后的长度不会大于MTU,因此一般情况下,TCP数据包不会进行IP分片。
网卡offload机制
早先TCP设计的目标是为了解决低速网络传输的不可靠性问题(拨号上网的年代),但随着互联网骨干传输速度的提升(光纤、千兆以太、万兆以太)以及用户端更可靠的访问机制的出现(ADSL等),相关的数据中心及客户端桌面环境上的TCP软件常常需要面临大量的计算需求。
当网络速度超过1Gb的时候,这些计算会耗费大量的CPU时间,有数据表明,即便使用千兆全双工网卡,TCP通信也将消耗CPU的80%的使用率(以2.4GHz奔腾4处理器为例),这样留给其他应用程序的时间就很少了,表现出来就是用户可能感觉到很慢。
小编注:当年的蠕虫病毒对CPU的影响与此近似。
为了解决性能问题,就产生了TOE技术(TCP offload engine),将TCP连接过程中的相关计算工作转移到专用硬件上(比如网卡),从而释放CPU资源。从2012年开始,这项技术开始在普通用户的网卡上应用。
随 着技术的日趋成熟,目前越来越多的网卡设备开始支持offload特性,以便提升网络收发和处理的性能。本文所描述的offload特性,主要是指将原本 在协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行,降低系统CPU的消耗,提高处理性能。
发送模式
**TSO (tcp-segmentation-offload) **
从 名字来看很直观,就是把tcp分段的过程转移到网卡中进行。当网卡支持TSO机制时,可以直接把不超过滑动窗口大小的payload下传给协议栈,即使数 据长度大于MSS,也不会在TCP层进行分段,同样也不会进行IP分片,而是直接传送给网卡驱动,由网卡驱动进行tcp分段操作,并执行checksum 计算和包头、帧头的生成工作。例如,
在本地主机上(10.8.55.1)发送一个超长的HTTP请求,当TSO模式关闭时,10.8.55.1抓包如下
当TSO模式开启时,10.8.55.1抓包如下:
**UFO(udp-fragmentation-offload) **
是一种专门针对udp协议的特性,主要机制就是将IP分片的过程转移到网卡中进行,用户层可以发送任意大小的udp数据包(udp数据包总长度最大不超过64k),而不需要协议栈进行任何分片操作。目前貌似没找到有支持UFO机制的网卡,主要是应用在虚拟化设备上。
**GSO(generic-segmentation-offload) **
相 对于TSO和UFO,GSO机制是针对所有协议设计的,更为通用。同时,与TSO、UFO不同的是,GSO主要依靠软件的方式实现,对于网卡硬件没有过多 的要求。其基本思想就是把数据分片的操作尽可能的向底层推迟直到数据发送给网卡驱动之前,并先检查网卡是否支持TSO或UFO机制,如果支持就直接把数据 发送给网卡,否则的话再进行分片后发送给网卡,以此来保证最少次数的协议栈处理,提高数据传输和处理的效率。
接收模式
**LRO/GRO(large-receive-offload) **
在网卡驱动层面上将接受到的多个TCP数据包聚合成一个大的数据包,然后上传给协议栈处理。这样可以减少协议栈处理的开销,提高系统接收TCP数据的能力和效率。
generic-receive-offload,基本思想和LRO类似,只是改善了LRO的一些缺点,比LRO更加通用。目前及后续的网卡都采用GRO机制,不再使用LRO机制。例如,
当本地主机(10.51.19.40)开启GRO模式时,从主机10.8.55.11向主机10.51.19.40发送一个超长请求。
10.8.55.11抓包如下:
10.51.19.40抓包如下:
**RSS(Receive Side Scaling) **
具备多个RSS队列的网卡,可以将不同的网络流分成不同的队列,再将这些队列分配到多个CPU核心上进行处理,从而将负荷分散,充分利用多核处理器的能力,提交数据接收的能力和效率。
网卡offload模式的设置
Linux
在linux系统下,可以通过ethtool查看各模式的状态并进行设置:
**查看状态 **
- ethtool –k 设备名
**设置开关状态 **
- ethtool –K 设备名 模式名(缩写)on/off
windows
在windows系统下,可以通过设备管理器中网卡设备的属性对网卡模式进行查看和调整。以Intel 82579LM和Intel I217-LM网卡为例
- IPv4、TCP、UDP校验和分载传输控制的是在网卡中进行checksum的计算和校验,其中Rx表示接收数据、Tx表示发送数据。
- 大型发送分载对应的是前文中提到的TSO模式
- 接收方调整和接收方调整队列对应的是RRS模式的启用状态以及RSS队列的个数设置。
网卡Offload技术给网络数据包分析带来的影响
目 前常用的抓包工具大部分都是从协议栈中(如数据链路层)捕获数据包,而网卡的offload特性会将数据包的分片、重组等工作转移到协议栈以下的硬件层面 进行,因此在开启TSO、GRO等机制的情况下,我们使用tcpdump、wireshark等工具抓取到的数据包往往不能真实反应链路上实际的数据帧, 给网络流量特征的分析造成不利影响。
在某些情况下,例如分片攻击等攻击方式,甚至可能会因为网卡设备的offload机制处理,而规避防火墙、IDS以及人工的检查。针对这些情况,可以选择关闭网卡offload的相关选项,或者在链路的其他节点进行抓包。
TSO(TCP Segment Offload)技术是一种利用网卡的少量处理能力,降低CPU发送数据包负载的技术,需要网卡硬件及驱动的支持。
在不支持TSO的网卡上,TCP层向IP层发送数据会考虑mss,使得TCP向下发送的数据可以包含在一个IP分组中而不会造成分片, mss是在TCP初始建立连接时由网卡MTU确定并和对端协商的,所以在一个MTU=1500的网卡上,TCP向下发送的数据不会大于min(mss_local, mss_remote)-ip头-tcp头。
而当网卡支持TSO时,TCP层会逐渐增大mss(总是整数倍数增加),当TCP层向下发送大块数据时,仅仅计算TCP头,网卡接到到了IP层传下的大数 据包后自己重新分成若干个IP数据包,添加IP头,复制TCP头并且重新计算校验和等相关数据,这样就把一部分CPU相关的处理工作转移到由网卡来处理。 内核TCP/IP协议栈也必须考虑下发包数和实际包数不一致的情况,例如处理拥塞控制算法时必须做一些特殊的处理等等。
注:参考内核版本为2.6.9;
1 TCP/IP协议栈对TSO的支持
1.1 逐渐增大mss(offload)
在不支持TSO的网卡 上,TCP层向IP层发送数据会考虑mss,使得TCP向下发送的数据可以包含在一个IP分组中而不会造成分片, mss是在TCP初始建立连接时根据网卡MTU确定并和对端协商的,所以在一个MTU=1500的网卡上,TCP向下发送的数据不会大于min (mss_local, mss_remote)-ip头-tcp头。
在应用层向传输层传输数据时,对于TCP协议,最终会调用如下函数:
文件 net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size)
该函数会调用如下函数
文件 net/ipv4/tcp.c
unsigned int tcp_current_mss(struct sock *sk, int large)
获得当前的mss值,如果网卡不支持TSO,则该函数返回的mss值将和原来相同,否则如果当前不是一个MSG_OOB类型的消息,内核将尝试增大 mss值,注意: 最大的mss值不会大于65535-ip头-tcp。 内核根据/proc变量tcp_tso_win_divisor决定增大后的mss占当前拥塞控制窗口的比率(snd_cwnd)。最终的效果是:增大的mss总是原有mss值的整数倍,但是不会超过snd_cwnd/tcp_tso_win_divisor。
1.2 对skb计数的修正
在启用TSO时,由于TCP层向下发送一个skb, 有可能最终会发出n个IP数据包,即一个skb和一个IP packet可能不是一一对应的关系,而我们都知道,TCP拥塞控制算法需要精确跟踪当前发送、接收以及拥塞控制窗口来决定最终发送多少数据包,TSO的 存在给计算带来了一定的复杂性,所以内核在每一个skb的末尾维护了额外的数据(struct skb_shared_info,通过skb_shinfo取出),表示该skb包含多少个packet。内核提供下列函数操作这块数据:
tcp_skb_pcount
tcp_skb_mss
tcp_inc_pcount
tcp_inc_pcount_explicit
tcp_dec_pcount_explicit
tcp_dec_pcount
tcp_dec_pcount_approx
tcp_get_pcount
tcp_set_pcount
tcp_packets_out_inc
tcp_packets_out_dec
tcp_packets_in_flight
最终,当TCP协议栈在调用tcp_snd_test决定是否可以发送当前skb时,会调用上述函数修正计算结果。
2 网卡驱动层对TSO的支持
如果skb_shinfo(skb)->tso_size不为0,则表明网卡需要对这样的skb作特殊的处理(而只有当网卡驱动初始化时声明自己支持TSO,才可能出现这样的skb),以e1000网卡驱动为例:
函数e1000_tso,在文件drivers/net/e1000/e1000_main.c,被e1000_xmit_frame (即hard_start_xmit服务函数)调用
if(skb_shinfo(skb)->tso_size) {
…
// 计算头部偏移
ipcss = skb->nh.raw - skb->data;
ipcso = (void *)&(skb->nh.iph->check) - (void *)skb->data;
tucss = skb->h.raw - skb->data;
tucso = (void *)&(skb->h.th->check) - (void *)skb->data;
tucse = 0;
……
//把头部偏移放入context,最终写入寄存器
context_desc = E1000_CONTEXT_DESC(adapter->tx_ring, i);
context_desc->lower_setup.ip_fields.ipcss = ipcss;
context_desc->lower_setup.ip_fields.ipcso = ipcso;
context_desc->lower_setup.ip_fields.ipcse = cpu_to_le16(ipcse);
context_desc->upper_setup.tcp_fields.tucss = tucss;
context_desc->upper_setup.tcp_fields.tucso = tucso;
context_desc->upper_setup.tcp_fields.tucse = cpu_to_le16(tucse);
context_desc->tcp_seg_setup.fields.mss = cpu_to_le16(mss);
context_desc->tcp_seg_setup.fields.hdr_len = hdr_len;
context_desc->cmd_and_length = cpu_to_le32(cmd_length);
……
}
……
//设置TSO标志
if (likely(tso))
tx_flags |= E1000_TX_FLAGS_TSO;
……
//发送“大”的skb数据
e1000_tx_queue(adapter,
e1000_tx_map(adapter, skb, first, max_per_txd, nr_frags, mss),
tx_flags);
即驱动需要告诉网卡硬件(设置E1000_TX_FLAGS_TSO标志),让网卡对这个skb重新分块,对每一个分块计算TCP头和IP头校验和,为此需要告诉网卡对应字段的偏移。
3 TSO对基于 RAW_SOCKET的抓包工具的影响
当发送数据包时,skb经过如下路径发向网卡驱动
net_tx_action->dev_queue_xmit()-> 驱动的hard_start_xmit服务函数
在函数dev_queue_xmit()中,如果有抓包工具开启了RAW_SOCKET,则该函数会在调用hard_start_xmit之前调用 dev_queue_xmit_nit clone一份skb交给抓包工具。如果skb是一个TSO-enable的特殊skb,抓包工具将会看到这个长度大于MTU的“特殊”skb。 而且,由于TCP、IP的校验和与长度字段将由网卡重新计算,一些版本的内核有可能为了优化而不去计算填写这些数值,所以除了会出现大数据包、校验和与长 度错误的现象。
例如:使用tcpdump在支持TSO的网卡抓取外出数据包可能会出现如下3种错误,其中第一种一般出现在使用e1000网卡驱动的2.6.9内核上,第2种出现在使用bnx2网卡驱动的2.6.9内核上,第3种出现在2.6.23+版本后的内核上:
* ip bad len = 0
000001 IP 192.168.13.1.61941 > 192.168.13.223.32879: . ack 4345 win 32768
000145 IP bad-len 0
000229 IP 192.168.13.1.61941 > 192.168.13.223.32879: . ack 8689 win 32768
000011 IP bad-len 0
* bad csum
16:29:32.561407 IP (tos 0x60, ttl 48, id 14116, offset 0, flags [DF], length:
80) 69.42.67.34.2612 > 81.13.94.6.1234: . [bad cksum 0 (->2610)!] ack 93407
win 9821
{122367:127103}{128551:129572}{122367:127103} >
* “包合并”
在MTU=1500的网卡上抓包,出现了比1500还大的IP包
21:58:36.691026 IP (tos 0x0, ttl 64, id 38181, offset 0, flags [DF], proto 6, length: 52) 10.13.100.34.45043 > 10.1
3.100.102.34476: . [tcp sum ok] 1:1(0) ack 482281 win 16664
21:58:36.691029 IP (tos 0x0, ttl 64, id 10688, offset 0, flags [DF], proto 6, length: 23220) 10.13.100.102.34476 >
10.13.100.34.45043: . 525769:548937(23168) ack 1 win 1448
21:58:36.691031 IP (tos 0x0, ttl 64, id 38183, offset 0, flags [DF], proto 6, length: 52) 10.13.100.34.45043 > 10.1
3.100.102.34476: . [tcp sum ok] 1:1(0) ack 485177 win 16664
21:58:36.691033 IP (tos 0x0, ttl 64, id 38185, offset 0, flags [DF], proto 6, length: 52) 10.13.100.34.45043 > 10.1
3.100.102.34476: . [tcp sum ok] 1:1(0) ack 488073 win 16664
根据上面的分析,可以知道这些现象本质都是TSO造成的假象,即TCPDUMP抓取的*外出*数据包并不能真实反应链路上实际的数据帧, 解决办法有两种:
1. 关闭网卡的TSO选项
[xxx]#ethtool -K eth0 tso off
2. 使用其他的旁路链路层的抓包工具
合理设置MTU,提升下载速度
2010年09月06日 19:03| 155,863 次浏览| 发布者 强伊文| 395 评论
可能很少有雷友注意过“本机、网络”的“MTU”值对自己网络性能产生的影响。对于追求更快的下载速度来说,MTU值设置不当,就仿佛穿着高跟鞋跑步一般。
MTU是什么?
“MTU=最大传输单元 单位:字节”
我们在使用互联网时进行的各种网络操作,都是通过一个又一个“数据包”传输来实现的。而MTU指定了网络中可传输数据包的最大尺寸,在我们常用的以太网中,MTU是1500字节。超过此大小的数据包就会将多余的部分拆分再单独传输。
为什么MTU影响网络性能?
让我们看看这个情况,在Windows系统中,默认MTU值也是1500字节,但是“不同的接入方式、不同地区的网络运营商、不同的路由器”有着不同的MTU设置。
例如:ADSL接入时MTU为1492字节,假设A需要给B传输3000字节数据,如果整个传输过程中各个环节的MTU都是1500,那么2个数据包就可以传输完成。可是偏偏这时ADSL接入方式的MTU是1492字节,数据包就因为这个MTU差异额外拆分为3个(为了便于理解,暂时不将“数据包报头”纳入考虑范围)
显然这额外增加了需要传输的数据包数量,而且拆包组包的过程也浪费了时间。如果从本地到网络采用一致的MTU就可以避免额外拆包。
对下载速度的影响会有多大?
就拿伊文家里的线路质量不太好的电信4M带宽为例,将操作系统的MTU值改为1492,再将路由器的MTU值从1460改为1492后,下载速度从原本的435KB/s提升到了450KB/s,提升了15KB/s。电信的带宽检测工具的检测结果也从4.09M提升到了4.19M。
我该如何合理设置MTU呢?
更快的下载速度,对于迅雷的用户来说,显然很有意义。可是MTU设置不能一个值天下通用,所以我们讲究合理设置MTU。
那么什么情况下的MTU值才是合理的呢?
我们先看看什么是不合理的:
1、本地MTU值大于网络MTU值时,本地传输的数据包过大导致网络会拆包后传输,不但产生额外的数据包,而且消耗了“拆包、组包”的时间。
2、本地MTU值小于网络MTU值时,本地传输的数据包可以直接传输,但是未能完全利用网络给予的数据包传输尺寸的上限值,传输能力未完全发挥。
这样我们就知道,所谓合理的设置MTU值,就是让本地的MTU值与网络的MTU值一致,既能完整发挥传输性能,又不让数据包拆分。
接下来最重要的就是要找出对于你的网络环境来说MTU多少才是合理的。
方法如下:
1、按Win+R组合键,调出“运行”菜单,输入“cmd”然后回车
2、在出现的“命令提示符”窗口中输入“ping -l 1472 -f www.baidu.com”然后回车
含义:
ping:发起一个探测请求;
-l(L的小写):限制探测包大小;
1472:包大小为1472字节;
-f:禁止路由器拆分数据包
www.baidu.com:设百度为探测目标
(你问我为什么不用Google做目标?考虑到Google时不时被墙,还是算了吧。。)
3、这时有2种情况:
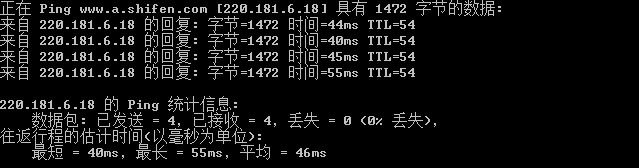
(1)、如果收到了回复,那么说明你的网络允许最大MTU值就是1500字节,与系统默认值相同,只需要将路由器的MTU值也设置为1500即可;
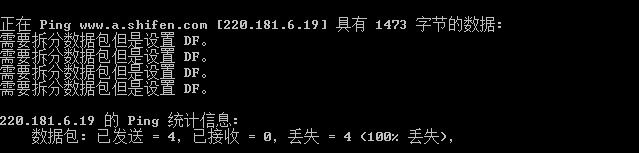
(2)、如果出现需要拆分数据包但是设置 DF。或是Packer needs to be fragmented but DF set.的提示,那就说明数据包大小超过了网络限定的MTU大小。需要减小探测包大小再次尝试。(为了截效果图,我将探测包改为1473了)
4、按“上箭头”恢复刚才输入的命令,然后以5为跨度减小包大小为1467字节,再次回车探测。
5、这时同样也有两种可能:
(1)、如果有返回,说明数据包小于MTU限制,就将包大小+3再次探测,如果+3之后没有返回,那就以1为跨度降低数据包大小进行探测。
(2)、如果还是没有返回,就继续以5为跨度减小包大小,直至有返回后进行5(1)中的操作。
6、直至你发现数据包-1后,有了返回,就说明你探测到了MTU允许的准确数据包大小。(例如从1465降低到1464就有了返回,那么允许的数据包大小就是1464)
7、不过上面得到的值还不能设置为操作系统或路由器的MTU,你找到的数据包大小需要加上28字节的“数据包报头”,才是完整的数据包尺寸。
(例如:探测到的数据包大小是1464,那么加上28字节,最终MTU=1492字节)
8、最后,只需要将路由器和操作系统中的MTU值设置为你得出的结果即可。
路由器设置方法见路由器说明书!建议使用“Windows优化大师、超级兔子魔法设置、鲁大师”等软件修改操作系统的MTU。
以下是较复杂的方法:
(1)、XP操作系统设置方法:
1、 按Win+R组合键,调出“运行”菜单,输入regedit,然后回车;
2、 选择“HKEY_Local_Machine>SYSTEM>CurrentControlSet>Services>Tcpip>Parameters>interface”;
3、在 interface 中下可能有很多项,需要逐个观察键值,会有一个项与你的网卡IP一致,选中该项;
4、然后在该项上点击右键,选择“编辑>新建>DWORD值”,然后在右侧将其命名为“MTU”;
5、右键点击MTU,选择“修改”,在弹出的窗口中选择“十进制”,填入你得出的合理MTU值即可。
(2)、Vista、Win7操作系统设置方法:
1、进入系统盘:\Windows\System32\找到cmd.exe,右键“以管理员身份运行”;
2、在出现的“命令提示符”窗口中输入“netsh interface ipv4 show subinterfaces”并回车来查看当前的MTU值
3、接下来输入“netsh interface ipv4 set subinterface "需修改的连接名" mtu=你得出的合理值 store=persistent”并回车即可
例如:“netsh interface ipv4 set subinterface "本地连接" mtu=1492 store=persistent”