Linux系统分析与编程-复习总结
文章目录
- linux 概述
- linux 文件系统
- linux 文件权限
-
-
- 基本权限 UGO
- 基本权限 ACL(Aceess Control List)
- 高级权限
- 文件属性
- 进程掩码umask
-
- linux 用户管理
- linux 文本处理
-
-
-
- Vim编辑器
-
-
- linux 编程基础
-
-
- 使用 gcc 编译 C程序
- 使用 make 编译 C程序
- 通过编译源代码安装程序
-
- linux 进程管理
-
-
- 进程基础
- 进程管理
- 进程通信
-
- linux 多命令协作(I/O重定向与管道)
-
-
- 命令行数据流
- 重定向
- 管道
-
- linux shell编程
-
-
-
- **变量**
- **输入输出**
- 分支控制语句
- 循环控制语句
-
-
- linux 磁盘管理
-
-
-
- 磁盘分区
-
-
- linux LVM磁盘
-
-
-
- 逻辑卷
- 文件系统
-
-
- 杂记
linux 概述
linux:一切皆文件
linux 内核:内存管理、进程管理、设备驱动程序、虚拟文件管理、网络管理

linux 文件系统
文件类型:普通文件,目录文件,链接文件,设备文件,管道文件
细分为

提问:如何判断文件的类型?
-
Linux系统中文件是没有扩展名
-
使用文件类型判断命令
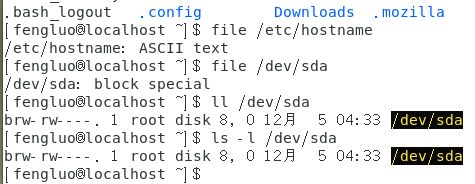
file -
使用 ls -l [文件] 查看
-
使用 ll [文件] 查看
-
使用 stat [文件] 查看文件详细信息
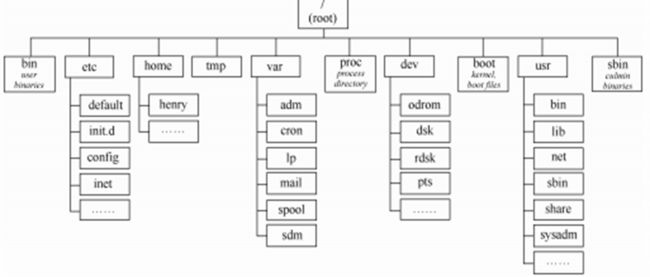
linux 文件系统结构(单根树状结构)
当前工作目录:每个shell或系统进程都有一个当前工作目录,使用 pwd 命令查看当前工作目录
文件名:最多255个字符,区分大小写,点号开头是隐藏文件
文件和文件夹都统称为文件
绝对路径从 “/” 开始
tree 命令显示路径结构
cd 切换工作目录,~ 表示 home 目录即主目录,root默认主目录为 /root,用户默认的 home 目录是添加用户时指定的 /home/xxx
cd - 返回到上一次目录
cd … 返回到上一级目录
ls(list)命令
对于目录,ls 输出该目录下的所有子目录与文件,字母序排序
对于文件,ls 输出文件名以及要求的其他信息
-a 隐藏信息 -A 隐藏信息不输出…
-d 列出目录文件本身的状态
-l 显示文件的详细信息
-L 链接文件指向的文件
-R 文件信息及内容,递归
ls -a 显示所有文件(含隐藏文件)
ls a* 显示以字母 a 开头的文件
绿色 — 可执行文件
浅蓝色 — 链接文件
红色 — 压缩文件
黄色 — 设备文件
mkdir 创建命令 mkdir n1 n2 n3
rmdir 删除目录 rmdir -p abc/adb
touch filename 创建文件
touch -am a.txt 修改文件的读取和修改时间
使用 stat 命令查看 stat a.txt
cat filename 命令 查看文件内容
cat -n a.txt 查看 a.txt内容,并显示行号
more 命令 逐页查看内容,空格翻页,b键上一页,ctrl+c中断
less 命令 分页显示内容 方向键控制 按q退出
head 命令 查看前几行内容 head -n
tail 命令 查看文件的后几行内容
cp 命令 cp [option] source dest,source 要复制的文件,dest 复制到的目录
mv 命令 为文件或目录改名或者将文件有一个目录移动到另一个目录中
mv [option] source dest
rm [option] filename 删除文件
sort 命令对文件中的各行排序 sort [option] filename
grep / egrep / fgrep 查找文件内容
find 在目录结构中搜索文件,并执行指定的操作
locate 查找文件,比find快,因为它不是搜索具体目录,而是搜索一个数据库(含有本地所有文件信息的数据库,每天更新一次)
whereis 查找文件,查找二进制文件、源代码文件、man手册页
文件链接类型
-
硬链接,不能引用不在同一磁盘分区的文件,无法引用目录
-
符号链接(软链接),特殊类型的文件包含了指向引用文件或目录的文本指针
一个文件或目录有三种时间:访问时间、修改时间、状态时间,没有创建时间

linux 文件权限
基本权限 UGO
u:owner为属主,文件所有者
g:group 为属组,同组用户
o:other 为其他用户
文件所有者一般是文件的创建者,对该文件的访问权限拥有控制权
r:read,数字设定值为4
w:write,数字设定值为2
x:execute,数字设定值为1
root 权限下
chown 修改文件属主、属组
chown [-cfhvR] [--help] [--version] user[:group] file...
chgrp 修改文件属组
与 chown 命令不同,chgrp 允许普通用户改变文件所属的组,只要该用户是该组的一员。
chgrp \[-cfhRv\]\[--help\]\[--version\]\[所属群组\]\[文件或目录...\]
chgrp \[-cfhRv\]\[--help\]\[--reference=<参考文件或目录>\]\[--version\]\[文件或目录...\]
chmod 修改文件权限
chmod [-cfvR] [--help] [--version] mode file...
修改文件权限的方法有两种
- 符号法
- 数字法
文件:注意 x 权限
目录:注意 w 权限
存储在磁盘上的文件就像是一个链表,表头是文件的起始地址,整个文件不连续存放。
要访问某个文件,只要找到表头即可。
删除文件时,其实只是把表头删除了,䪶的数据并没有删除,直至下一次进行写磁盘操作需要占用节点所在位置时,才会把数据覆盖。
基本权限 ACL(Aceess Control List)
UGO权限只针对一个用户,一个组与其他用户,使用上有局限性。
getfacl / setfacl
最大有效权限 mask。系统给用户的最终权限是ACL权限和mask权限的逻辑与。
mask并不能影响所有用户。例如owner与other并没有因mask变化而变化。
为方便管理文件权限,通常将other的权限设置为空。
mask能临时降低用户或组(除owner和other)的权限,而不是如setfacl –d命令去除所有权限。
只要有任何ACL权限设置,mask会自动还原。
高级权限
在进程文件(二进制,可执行)上增加SUID权限,让本来没有相应权限的用户也可以访问没有权限访问的资源。
普通用户通过 SUID 提升权限
在一个程序上添加 SGID 权限,用户在执行过程中会获得该程序用户组的权限(相当于临时加入了程序的用户组)
添加 Sticky 权限,当用户对目录具有w、x权限,在该目录下建立文件或目录,仅有自己与root才有权删除该文件。
系统还存在一些目录(如tmp目录),为了保证该目录下文件的安全,系统自动为其增加了“t”权限,因此目录下的文件只有属主可以删除。
/tmp目录为全局可写,其权限只能为1777,否则会导致程序不能正常运行
权限的字符位只有9位,当增加特殊权限后会占用“x”权限的位置。
为了区分目录或文件是否含有“x”权限,系统会以特殊权限的大小写方式给予提示。
-
当符号为大写时,表示不含有“x”权限。
-
当符号为小写时,表示含有“x”权限。
文件属性
lsattr 查看文件属性
chatrr 修改文件属性
进程掩码umask
当用户创建新目录或文件时,系统会赋予目录或文件一个默认的权限,umask作用就是指定权限默认值。
-
为系统设置一个合理的umask值,确保创建的文件或目录具有所希望的缺省权限,保证数据安全。
-
umask值表示要减掉的权限(可以理解为权限的“反码”),进程、新建文件、目录的默认权限都会受到umask的影响。
-
umask 命令查看当前终端的 umask 值
最终新建文件、目录的访问权限是由默认权限和umask属性的差值决定的,每个终端都拥有一个umask属性
一般普通用户的默认umask是002,root用户的默认umask是022
不同的进程也可以设置自己的umask
新创建的用户/home目录的权限默认为700
linux 用户管理
用户组
每个用户都有一个唯一的uid用来标识
uid为用户id,gid为用户所属的组id
id命令 查看当前用户登录信息 id [option] [username]
用户分:
- root 用户,id为0,最高权限
- 系统用户,不具有登录的能力,系统运行所需,id 1-499,centos7中1-999
- 普通用户,可以登录,使用权限有限,500以上,centos7中1000以上
管理用户
useradd 添加用户 useradd [option] username
passwd 修改密码
userdel 删除用户
usermod 修改用户属性 usermod [option] username
gpasswd 从用户组中移除一个用户
管理用户组
groupadd:添加用户用户组
groupmod:修改用户组
groupdel:删除用户组
查看用户属于哪个组
-
groups:查看用户属于哪个组
-
查看文件 /etc/group
-
id命令法
与用户有关的文件
/etc/passwd 用户信息(注册名,口令,用户标识号,组标识号,用户名,用户主目录,命令解释程序)
/etc/shadow 加密的用户密码,root可查看(将密码和其他/etc/passwd文件不能包括的信息(如有效期限)单独保存在/etc/shadow中)
/etc/group 用户组信息(组名,口令,组标识号,组内用户列表)
/etc/login.defs 配置文件
su 命令,切换root用户
linux 文本处理
Vim编辑器
三种工作模式
- 命令模式:默认进入,esc返回命令模式
- 插入模式:仅此模式可以编辑文本
- 末行模式:按:键进入末行模式
查找
- f 行内搜索
- / 搜索整个文件,n查找下一个
替换
- 末行模式,:1,5s/df/dd 1-5行中第一次出现的df换为dd
剪切 cut,必须指定-b、-c、-f标志之一
粘贴 paste,向文本中添加信息,将文件合并后存入另一个文件
连接 join,与paste类似,向文本中添加信息
文本比较
有序文件逐行比较命令 comm,只能对已经排序的文件操作,所以要先对文件排序(sort命令)
逐行比较命令 diff,比较文件的区别,文件可以是无序的,可以是大的文件集,查找版本不同之处,-c 上下文格式,-u 统一格式,-y 并排格式
原文件比较 patch,首先利用diff查找文件的不同,生成patch命令可操作的diff文件,利用patch更新,patch a1.txt < b1.txt
格式化输出 printf
格式化段落,是文本看上去更整齐 fmt
为文本创建行号 nl,不影响原文件的文本内容
指定行长度命令 fold,将文本折叠,长行分解为短行
awk 文本处理工具
sed 文本编辑器
vi/vim 添加行号,1. 在文本中输入 set number 字段 2. 命令模式下,输入set nu 字段,set nonu 取消
linux 编程基础
cat 查看文件内容
使用 gcc 编译 C程序
-
gcc 命令可以编译c文件
-
当程序依赖多个文件时,可以先将每个文件编译成目标文件,再把所有目标文件链接成可执行文件。也可以直接引用在一个文件里
编译过程四阶段:预处理、编译、汇编 和链接
-
1.编写程序
-
2.无论静态库,还是动态库,都是由.o文件创建的。因此,我们必须将源程序通过gcc先编译成.o文件。gcc -c hello.c -std=c11
-
3.由.o创建静态库文件libmyhello.a,ar命令,ar -cr libmyhello.a hello.o
-
4.在程序中使用静态库,gcc -o main main.c -L. -lwsort
-
5.由.o创建动态库,生成动态链接库 gcc -shared -fPCI -o libmyhello.so hello.o -std=c11
-
6.在程序中使用动态库,gcc -o hello main.c -L. -lmyhello
-
7.编写makrfile
-
B_NAME?=libsort all:static_library shared_library static_library: gcc -c *.c; ar -cr lib${LIB_NAME}.a *.o; shared_library: gcc -shared -fpic -o lib${LIB_NAME}.so *.c; clean: rm -rf *.o rm -rf *.a *.so -
文件操作:
-
#includevoid create(char name[], char content[]) { FILE *f = fopen(name, "w+"); fputs(content, f); fclose(f); } int main() { create("file.txt", "Hello World"); return 0; }
使用 make 编译 C程序
-
make可以获知所管理项目中源文件的修改情况,根据程序员设定的规则,自动编译被修改过的部分,而那些没有修改的部分将不会重新编译(提高项目开发效率)。
-
make是如何知道哪些文件被修改了?需要执行什么指令才能保证程序的正确?make通过makefile文件描述的内容自动维护编译工作。makefile文件需要程序员按照某种格式编写,并说明项目中各个源文件之间的依赖情况。
-
make [ -f makefile ] [ options ] … [ targets ] …WARNING
makefile文件说明:
-
第一行说明了程序prog2由3个目标文件hello2.o、func1.o和 ffunc2.o链接生成。
-
第3、第5、第7行说明了三个目标文件依赖的.c文件(若有.h文件,也放在此)。
-
第2、第4、第6、第8则是根据这些依赖关系,编译目标文件或可执行文件(前面一定要用Tab键)。
-
clean是清除不需要的文件(前面一定要用Tab键)。
通过编译源代码安装程序
- Linux系统中,许多程序都直接提供源代码,可以利用make和makefile文件编译源代码并完成程序的安装。
- pcre,是一个Perl库,用于来解决C语言中使用正则表达式的问题。
安装 pcre 步骤
-
安装 wget命令 用来从指定的 url 下载文件
-
tar.gz 解压 tar 文件
-
进入目录pcre2-10.23,查看是否有文件configure。
-
运行 configure, ./configure --enable-utf8 configure脚本作用是分析当前系统的环境,并且检查系统是否已经安装了必要的外部工具和组件,然后生成合适的makefile文件以便下一步编译。
-
如果在检查过程中,发现了某些导致安装无法进行的问题,如缺少开发用的某些软件或开发库,configure会以失败告终。
-
若编译顺利完成,则可以使用命令make install进行安装。该命令会在安装目录下生成可执行程序。
-
查看是否安装好
linux 进程管理
进程基础
为了保证程序能够并发执行,需要对程序的执行过程进行动态控制。进程就是用来描述这一控制过程的,组织安排不同程序等待CPU的调度。
进程是一个具有一定独立功能的程序或程序段在一组数据集合上的一次动态执行过程,同时也是程序能够并发执行的基础机制。各种资源的分配和管理都是以进程为单位。
进程的基本组成结构:
-
进程控制块PCB(Processing Control Block)是进程动态特征的反映,主要包括进程的描述信息、控制信息、进程使用资源情况等。用于跟踪管理程序状态。
-
程序段是该进程需要完成功能的程序代码。
-
数据结构集是进程执行时需要访问的工作区和数据对象,即执行进程时需要的系统资源。
进程在创建时,会被内核赋予一个PID(非负整数)作为进程唯一标识号
进程PID可以重用,当进程终止后,Linux一般通过延迟重用算法,使得赋予新进程的PID不同于最近终止进程的PID
在Linux系统中可以同时运行多个进程,为了方便跟踪管理所有的进程,内核中存在一个进程表,以PID为索引,每个进程在进程表中都会存在一条记录,描述及管理进程所需的信息
交互进程:由Shell启动的进程,既可以在前台运行,也可以在后台运行,且必须由用户给出某些参数或者信息,进程才能继续执行。
批处理进程:与终端没有联系,是一个进程序列,负责按照顺序启动其他进程。
守护进程:执行系统特定功能或者执行系统相关任务的进程,并在后台运行。
-
守护进程是一个特殊进程,不是内核的组成部分。
-
大部分守护进程是在系统启动时启动,直到系统关闭时才停止运行。
在 linux 中,用户程序装入系统形成一个进程的实质是系统为用户程序提供一个完整的运行环境。进程运行环境是由它的程序代码、程序运行所需的数据结构和硬件环境组成的。
进程运行环境主要包括:
-
进程空间中的代码和数据、各种数据结构、进程堆栈和共享内存区等。
-
环境变量:提供进程运行所需的环境信息。
-
系统数据:进程空间中的对进程进行管理和控制所需的信息,包括进程任务结构体以及内核堆栈等。
-
进程访问设备或者文件时的权限。
-
各种硬件寄存器。
-
地址转换信息。
由于硬件寄存器的值以及进程控制信息是随着进程的运行而不断变化的,所以进程的运行环境是动态变化的。
在Linux中把系统提供给进程的处于动态变化的运行环境总和称为进程上下文。上下文(运行环境)
系统中的每一个进程都有自己的上下文。
-
当前进程是指一个正在使用处理器运行的进程。
-
进程切换是指当前进程因时间片用完或者因等待某个事件而阻塞时,进程调度需要把处理器的使用权从当前进程交给另一个进程的过程。
- 此时被调用进程成为当前进程
- 在进程切换时,系统要把当前进程的上下文保存在指定的内存区域,然后把下一个使用处理器运行的进程的上下文设置成当前进程的上下文。
- 当一个进程经过调度再次使用CPU运行时,系统要恢复该进程保存的上下文。
进程的切换也就是上下文切换。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便再次执行该进程时,能够得到切换时的状态执行下去。
进程管理
linux 进程状态:运行状态、就绪状态、阻塞状态(睡眠状态、暂停状态、僵死状态)
进程之间相互独立,一个进程不能改变另一个进程的状态。
运行状态
就绪状态
睡眠状态
暂停状态
僵死状态
一般情况下,一个进程至少有 3 种基本状态:运行状态、就绪状态、封锁状态(阻塞状态)
ps 命令 查看正在运行的进程信息以及状态
查看 pid
- 使用 cat 命令
- 使用 pidof 命令
- 使用 pgrep 命令
实时动态显示进程信息命令 top,top 命令将按照进程活动顺序,持续更新显示当前系统进程的信息
信号量控制进程
kill 命令终止指定进程的运行
1 sighup 重新加载进程。
9 sigkill 杀死一个进程。
15 sigterm 正常停止一个进程。
18 sigcont
19 sigstop
killall 命令 用于终止某个指定名称的服务所对应的全部进程
进程优先级
动态优先级,静态优先级
系统上常规的调度策略为SCHED_OTHER(也称SCHED_NORMAL),SCHED_OTHER调试策略使用的进程的相对优先级称为nice值,其值的范围为-20~19,数值越小,优先级越高,数值越大,优先级越低。
命令 nice -n 10 wc 设置 wc 优先级=10
作业控制
允许一个Shell实例来运行和管理多个命令
如果没有作业控制,父进程fork( )一个子进程后将休眠,直到子进程退出
使用作业控制可以选择性暂停、恢复以及异步运行命令,让 shell可以在子进程运行期间返回接受其他命令。
foreground:前台进程是在终端中运行的命令,该终端为进程的控制终端。background:后台进程没有控制终端,它不需要终端的交互。
ctrl+c 停止命令
jobs命令用于显示当前shell中的作业列表及作业状态,包括后台运行的任务。该命令可以显示作业ID。
bg命令可以把任务移动至后台。fg命令可以将后台进程移动到前台,进程会占用终端,即可以使用键盘读取或写入。
系统管理员经常通过SSH或者telent远程登录到Linux服务器,运行一些时间很长才能完成的任务,比如系统备份、ftp传输等
Screen是一款用于会话终端切换的多重视窗管理程序软件,通过该软件同时连接多个本地或远程的主机。当远程连接一台主机时,如果出现连接非正常中断,只要Screen没有终止,再次登录到主机上执行“screen -r”命令,就可以恢复此前在其内部运行的会话。
每个进程都有自己的生命周期,主要包括进程的创建、进程的执行和进程的终止。
fork函数创建进程。
exec函数控制进程执行特定任务。
exit 函数终止进程。
wait 函数控制进程同步执行。
引用fork系统调用的进程是父进程,由fork创建的进程是子进程。
pid表示执行fork调用后的返回值:
-
pid=0,表示此进程是子进程。
-
pid>0,表示此进程是父进程。
-
pid<0,表示进程创建失败。
子进程从fork调用后的语句开始与父进程并发执行。
进程创建:用fork函数创建的子进程,与父进程执行相同的代码,如果需要子进程执行不同的任务,则需要在子进程中使用exec函数调用,让子进程执行新的代码段。
进程控制:exec函数调用格式:execve(pathname, argv, envp),六种调用方式,execl、execv、execle、execve、execlp、execvp
l:要求把参数指针数组的每个指针都作为独立的参数传递,并以空指针NULL结束。
v:同C语言使用argc、 argv传递参数一样,通过argv指针数组中的内容传递exec函数调用需要的参数。
e:从envp指针数组传递环境参数,表示要执行的程序需要新的运行环境,否则用现有环境变量复制新程序环境。
p:在搜索执行程序时,在环境变量PATH指定的目录中搜索指定的文件,否则在当前目录中进行搜索。
进程终止:进程终止后进入僵死状态,释放所占用的大部分资源
进程同步:为了让子进程的终止点和父进程同步,可以在父进程中引用wait调用,等待子进程完成其指定任务。
wait调用最常用的方式:wait(0),使父进程暂停执行,处于等待状态,一旦子进程执行完毕,父进程就会重新进入执行状态,从而保证子进程与父进程的执行同步。
进程通信
管道(pipe)可用于具有亲缘关系进程间的通信。
命名管道(named pipe或FIFO)克服了管道没有名字的限制,允许无亲缘关系进程间的通信。
管道(无名管道),管道是一种最基本的进程通信机制,使用内存实现进程通信,只适用于父子进程或父进程安排的各个子进程之间的通信。
通过pipe调用在内核中创建管道,函数原型为:int pipe(int fildes[2])
调用pipe函数,会得到两个文件描述符(一个读端,一个写端),然后通过fildes参数将这两个文件描述符传给用户程序:fildes[0]为读端,filedes[1]为写端,然后用户程序通过系统调用read(filedes[0])和write(filedes[1])进行管道的读和写。
命名管道:命名管道借助于磁盘在任意进程间通信。命名管道提供了一个路径名与之关联,以FIFO的文件形式存储在系统中,因此即使进程与创建FIFO的进程不存在亲缘关系,只要可以访问路径,就可以建立通信。
遵循先进先出的原则,即第一个被写入的数据首先从管道中读出。
通过mknod或mkfifo调用建立命名管道,函数原型为:
int mknod(const char *path, mode_t mod, dev_t dev)
int mkfifo(const char *path,mode_t mode);
信号
信号(signal)用于通知接收进程有某种事件发生。除了用于进程间通信外,进程还可以发送信号给进程本身。
进程通过kill调用发送信号。通过signal调用接收或捕获信号。
进程通过signal接收信号后,处理方法有:
-
指定处理函数,由函数来处理。
-
忽略信号,不做任何处理。
-
对该信号保留系统的默认值。
kill函数
kill函数用于发送信号,进程通过调用kill函数可以向自身或其他进程发送信号。函数原型为:int kill(pid_t pid, int sig)
kill函数作用是把信号sig发送给进程号为pid的进程。
函数调用成功返回值为0,
调用失败返回值为-1。调用失败的原因:
-
指定的信号无效。
-
发送权限不够,即目标进程由另一个用户拥有
-
目标进程不存在。
signal函数
signal函数用于处理信号进程。函数原型为:void ( *signal(int sig, void (*handler)(int)) ) (int)
消息队列
消息队列(message)是消息的链表,包括Posix消息队列和system V消息队列。消息队列的通信方式是一个进程向另一个进程随时发送一个数据块,不需要接收方准备好。只有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息,消息队列的读取不一定是先进先出。
msgget函数
msgget函数用来创建和访问一个消息队列。函数原型为:int msgget(key_t key, int msgflg)
其中,key表示消息队列的标识符。msgflg是一个权限标志,表示消息队列的访问权限,它与文件的访问权限一样。函数调用成功,返回一个以key命名的消息队列的标识符(非零整数),失败时返回-1。
msgsnd函数
msgsnd函数用来把消息添加到消息队列中。函数原型为:int msgsnd(int msgid, const void *msgp, size_t msgsz, int msgflg)
其中,msgid是由msgget函数返回的消息队列标识符。msgp是一个指向准备发送消息的指针,指针msgp指向的消息结构一定要是以一个长整型成员变量开始的结构体。msgsz是msgp指向的消息的长度,不包括长整型消息类型成员变量的长度。msgflg用于控制当前消息队列满或队列消息到达系统范围的限制时将要发生的事情。函数调用成功,消息数据的一个副本将被放到消息队列中,并返回0,失败时返回-1。
msgrcv函数
msgrcv函数用来从一个消息队列获取消息。函数原型为:ssize_t msgrcv(int msgid, void *msgp, size_t msgsz, long msgtyp, int msgflg)
其中,msgid、msgp、msgsz 的含义同msgsnd函数的一样。msgtyp确定接收消息的优先级。如果msgtyp为0,就获取队列中的第一个消息。如果msgtyp>0,将获取具有相同消息类型的第一个信息。如果msgtyp<0,就获取类型等于或小于msgtyp绝对值的第一个消息。msgflg用于控制当队列中没有相应类型的消息可以接收时将发生的事情。msgrcv函数调用成功,该函数返回放到接收缓存区中的字节数,消息被复制到由msgp指向的用户分配的缓存区中,然后删除消息队列中的对应消息。失败时返回-1。
msgctl函数
msgctl函数用来控制消息队列,函数原型为:int msgctl(int msgid, int cmd, struct msgid_ds *buf)
其中,msgid是由msgget函数返回的消息队列标识符。cmd是将要采取的动作,它可以取3个值。① IPC_STAT:把msgid_ds结构中的数据设置为消息队列的当前关联值,即用消息队列的当前关联值覆盖msgid_ds 的值。② IPC_SET:如果进程有足够的权限,就把消息列队的当前关联值设置为msgid_ds结构中给出的值。③ IPC_RMID:删除消息队列。buf是指向msgid_ds结构的指针,它指向消息队列模式和访问权限的结构。
Linux套接字
不同计算机间进程通信
源IP地址和目的IP地址以及源端口和目标端口号的组合称为套接字。其作用于标识客户端请求的服务器和服务。
套接字,支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点 简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
信号量
信号量(semaphore)的作用是协调进程访问共享资源。信号量是一种外部资源标识,本身不具有数据交换的功能,通过控制其他的通信资源实现进程间的通信。
当请求一个使用信号量表示的资源时,进程需要先读取信号量的值来判断资源是否可用。信号量的值>0时,表示资源可以请求。
信号量的值=0时,表示资源已经被占用,此时进程会进入睡眠状态等待资源可用。
对信号量进行操作常用函数:semget、semop、semctl
共享内存
共享内存是Linux系统中最底层的通信机制,速度最快速。共享内存是通过多个进程共享同一块内存区域来实现进程间的通信。
做法:由一个进程创建一块共享内存区域,然后多个进程可以对其进行访问。发送进程将要传出的数据存放到共享内存中,接收进程(一个或多个进程)则直接从共享内存中读取数据,避免了数据的复制过程。
采用共享内存的进程通信的特点:(1)当进程通信时,需要交互的数据或信息不发生存储移动。(2)当需要交互时,通信进程双方通过一个共享内存完成信息交互。(3)对共享内存,可以用虚拟映射方式将其作为交互过程中的一部分存储体使用。
用共享内存与另一进程通信的常用函数为:shmget、shmat、shmdt、shmctl
linux 多命令协作(I/O重定向与管道)
命令行数据流
在Linux系统中,命令行Shell数据流定义为三类:
-
0,标准输入STDIN(standard input):是用来采集信息的,命令是通过STDIN接收参数或数据,默认情况下,标准输入就是从键盘读入数据。
-
1,标准输出STDOUT(standard out):是用来输出结果的。
-
2,标准错误STDERR(standard error):是输出状态或错误信息等。
为了方便管理Shell中的数据流,并且可以通过管道和重定向机制控制CLI数据流。
默认情况下,标准输出和标准错误都是直接在终端(即屏幕)显示,不会被保存到磁盘中。
重定向
每一个进程在运行中都会打开一些文件,每一个文件都会有一个指定的数字标识,这个标识就叫做文件描述符。
-
0表示为标准输入,可以理解为键盘输入。
-
1表示为标准输出,输出到终端。
-
2表示为标准错误,输出到终端。
-
3及以上为常规文件的描述符。
默认情况下,标准输出在屏幕上显示,而重定向标准输出可以重新定义输出内容到文件。
重定向标准输出格式
重定向符“>”是把标准输出重定向到文件,即将标准输出内容保存到文件中,是覆盖操作。如果目标文件不存在,则创建文件并将标准输出内容保存进去;如果目标文件存在,则覆盖其中的内容。
重定向符号“>>(中间没有空格)”是追加操作,实现连续保存文件中的内容。即原来的文本内容不会被覆盖,而是在文件尾部添加标准输出的内容。如果文件不存在,也会自动创建。
重定向标准输入格式
默认情况下,标准输入就是从键盘读入数据,每次一行。按 Ctrl+D 组合键结束输入数据,重新回到 Shell 命令环境。
重定向标准输入可以重新定义从文件中读入数据。通过重定向符“<”,可以把标准输入重定向到文件,即从文件中读入数据作为某条命令的输入数据。
利用cat命令接收标准输入数据(从键盘输入),不带任何参数。说明:
输入cat命令回车后,光标会跳到下一行一直闪动,等待从键盘读入数据。由于cat把标准输入的内容显示在屏幕上,所以当输入一行,按下Enter键时,会显示刚刚输入的内容。按Ctrl+D组合键结束输入,并存盘(有重定向符<时)。按Ctrl+c组合键中断输入。
当数据文件已经存在,通过重定向符“<”,可以将文件中的内容会在屏幕上显示。
重定向标准错误格式
默认情况下,标准错误在屏幕上显示,而重定向标准错误可以重新定义输出错误内容到文件。
通过重定向符“2>”把标准错误内容保存到文件中,是覆盖操作。如果目标文件不存在,则创建文件并将标准错误内容保存进去。如果目标文件存在,则覆盖其中的内容。此命令用于日志中,执行一条指令可能有很多步操作。如果只想保存报错信息,就可用此命令。重定向符号“2>&1(中间没有空格)”是将标准输出和标准错误结合在一起输出到文件,即将正确结果及错误全部输出到文件。标准输出和标准错误的数据流是分开输出的。
subshell
Subshell是指括在圆括号里的命令会在另外的进程中执行。当需要让一组命令在不同的目录下执行时,采用这种方法可以不修改主脚本的目录。
管道
管道实际上也是一种重定向,重定向字符控制输出到文件,管道控制输出到其他程序。管道的作用是把上一个进程的输出作为下一个进程的输入,利用管道可以把若干个命令连接在一起。
统计字数命令wc
wc(word count)命令可以统计行、单词和字符的数量。统计的数据来自于一个或多个文件,或者其他命令的标准输入,因此wc命令与管道息息相关,在分析文本内容时有很大的作用。
wc命令格式:wc [option] [file],其中, option和file可以省略,option控制wc命令的输出结果。file是wc命令要操作的文件的名称。
管道线分流命令tee
tee命令的作用是从标准输入读取数据,并向标准输出和一个或更多的文件发送数据。当需要把获得的数据在同一时刻发送到两个地方时(同时完成两个任务),就可以使用tee命令。
tee命令格式:tee [-ai] [file…],其中,file是tee命令要操作的文件的名称。
查找重复行命令uniq
uniq命令会一行一行地检查数据,查找出连续重复的行。注意uniq只能查找有序的文件,重复行一定是连续的。
uniq命令的作用:消除重复行、选取重复行、选取唯一行和统计重复行的数量。
uniq命令格式:uniq [option] [input [output]],uniq [选项]… [文件]
awk文本处理工具
awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。按行处理文本。
awk工作流程:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 “[tab]键”。
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file



linux shell编程

#!/bin/bash
#我的第一个shell脚本
echo 'Hello,XiangTian!'
变量
命名规则:变量名必须由大写字母(A~Z)、小写字母(a~z)、数字(0~9)或下画线(_)构成;变量名的第一个字符不能是数字。
变量定义格式如下:变量名 = 变量值;
当第一次使用某个变量名时,实际上就定义了这个变量。如果没有给出变量值,则变量会被赋值为一个空字符串。
变量类型
Shell 变量分为自定义变量、环境变量、位置变量和预定义变量
Shell 变量只有字符串一种类型,即无论给 Shell变量赋予什么值,在存储时都会转换为字符串。
环境变量,类比全局变量。
位置变量,位置变量用于在命令行、函数或脚本中传递参数,其变量名不用自己定义,其作用也是固定的。执行脚本时,通过在脚本后面给出具体的参数(多个参数用空格隔开)对相应的位置变量进行赋值。$0代表命令本身,$1-$9代表接收的第1~9个参数,$10以上需要用{}括起来,如${20}代表接收的第20个参数。
预定义变量,预定义变量在Shell中可以直接使用,位置变量也是预定义变量的一种。预定义变量如下表。
| 预定义变量 | 说明 |
|---|---|
| $0 | 脚本名 |
| $* | 所有的参数 |
| $@ | 所有的参数 |
| $# | 参数的个数 |
| $$ | 当前进程的PID |
| $! | 上一个后台进程的PID |
| $? | 上一个命令的返回值,0表示成功。 |
变量操作
变量的操作归纳为:创建变量、获取变量的值、修改变量的值和删除变量。
1、创建变量
变量创建只需要指定变量名称和变量值,它们之间用等号(=)连接,等号两边不能有空格。
创建变量语法:NAME=value
变量创建好后,可以用$变量名的方式获取变量的值。若创建变量时没有赋值,则系统默认此变量的值为null。当用$符号获取并没有被创建过的变量时,系统会自动创建变量,并为变量赋值为 null。
2、获取变量的值
可以使用$符号获取变量的值。
如果变量后面需要紧跟其他字符将怎么办呢?
例如,需要将文件out.txt改名为out.txt1,可以通过 mv 命令快速实现。
方法1:mv out.txt out.txt1
方法2:用变量os来存储文件名,按左边方式执行mv命令
为了区分变量名和变量名后面紧跟的字符,可以**使用花括号{}**将变量名括起来。
变量的修改、删除、替换和替代
修改
直接修改即可
环境变量的修改与Shell变量有所不同,因为子进程对环境变量的修改不会传递到父进程中。
如果需要的话,可以用unset命令删除。unset命令也可以删除环境变量。
unset命令格式:unset NAME。
移除一个环境变量唯一的办法就是删除它。用户可以通过export命令将Shell变量导出为环境变量,但没有办法将环境变量再恢复成Shell变量。
删除
| 格式 | 说明 |
|---|---|
| ${变量名#关键字符} | 变量内容从头开始的数据符合“关键字符”,则将符合的最短数据删除。 |
| ${变量名##关键字符} | 变量内容从头开始的数据符合“关键字符”,则将符合的最长数据删除。 |
| ${变量名%关键字符} | 变量内容从尾开始的数据符合“关键字符”,则将符合的最短数据删除。 |
| ${变量名%%关键字符} | 变量内容从尾开始的数据符合“关键字符”,则将符合的最长数据删除。 |
替换
| 格式 | 说明 |
|---|---|
| ${变量名/旧字符串/新字符串} | 若变量内容符合“旧字符串”,则第1个“旧字符串”会被“新字符串”替换。 |
| ${变量名//旧字符串/新字符串} | 若变量内容符合“旧字符串”,则全部“旧字符串”会被“新字符串”替换。 |
替代
一般情况下,可以给一些变量设置默认值。例如,在连接数据库时,可以预先设置好端口,也可以由用户输入端口。
假如用户没有输入具体的端口号,脚本就使用预先设置的端口。
变量设置默认值格式:${变量名-新的变量名}
如果变量名没有被赋值,会使用”新的变量值”替代,如果变量已被赋值(包括空值),则该值不会被替代。
变量的算术运算
在Shell中,变量值的类型默认是字符串,不直接进行运算。
如果需要对Shell变量进行运算,需要使用特殊方法。用于整数运算的方法有expr、(())和$[]。Shell也可以对小数进行运算(不建议用)。
| 算术运算符 | 说明/含义 |
|---|---|
| +、- | 加法(或正号)、减法(或负号) |
| *、/、% | 乘法、除法、取余(取模) |
| ** | 幂运算 |
| ++、– | 自增和自减,可以放在变量的前面也可以放在变量的后面 |
| !、&&、|| | 逻辑非(取反)、逻辑与(and)、逻辑或(or) |
| <、<=、>、>= | 比较符号(小于、小于等于、大于、大于等于) |
| ==、!=、= | 比较符号(相等、不相等;对于字符串,= 也可以表示相当于) |
| <<、>> | 向左移位、向右移位 |
| ~、|、 &、^ | 按位取反、按位或、按位与、按位异或 |
| =、+=、-=、*=、/=、%= | 赋值运算符,例如 a+=1 相当于 a=a+1,a-=1 相当于 a=a-1 |
expr 数值运算命令:expr命令既可以用于整数运算,也可以用于相关字符串长度、匹配等运算处理。语法格式:expr expression,例:expr $n1 + $n2。在使用expr时,需要注意:运算符及用于计算的数字两边必须有空格,否则会执行失败。用expr进行乘法运算时,必须在*前用反斜线转义(Shell可能误解为*号)
双小括号 “(())” :作用是进行整数运算和数值比较,其效率很高,用法也非常灵活,是企业中常见的运算操作符。格式:“ ((expression))”,或“ [expression]”。括号内部两侧可以有空格,也可省空格。需要直接输出运算表达式的运算结果时,可以在“((表达式))”前加$符。
let数值运算命令:let数值符号可以直接进行计算,且不带回显功能,也就是说当使用let的时候,不再使用$引用变量。
shell 小数运算:bc计算器,效率低
变量自增运算类似 C语言
-
+ 、-、*、\ : 乘号前必须加\进行转义才可以进行乘法运算
-
加法运算
-
- val=`expr 2 + 2` (使用linux命令expr进行辅助运算)
- val= [ 2 + 2 ] ( 4 个 空 格 不 是 必 要 的 , 不 同 于 条 件 判 断 ) − v a l = [2+2] (4个空格不是必要的,不同于条件判断) - val= [2+2](4个空格不是必要的,不同于条件判断)−val=((2+2))
- let
- val=`expr 2 + 2` (使用linux命令expr进行辅助运算)
变量特殊符号
# 注释
; 在同一行中分隔两个或者两个以上的命令。也适用于循环语句
-
;; 用于终止case选项
- 空命令“:”和true命令作用相同。在while死循环和if/then中也可使用这个命令。
. 等价于source命令,是bash中的一个内建命令。.也可以作为文件名的一部分,如果“.”放在文件名的开头,那么这个文件将会成为“隐藏文件”。ls命令将不会正常显示出这个文件。当点作为目录名时,一个单独的点代表当前工作目录,而两个点表示上一级目录。
获取字符串长度
string="abcd"
echo ${#string} #输出 4
提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="runoob is a great site"
echo ${string:1:4} # 输出 unoo
注意:第一个字符的索引值为 0。
查找子字符串
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
string="runoob is a great site"
echo `expr index "$string" io` # 输出 4
注意: 以上脚本中 ` 是反引号,而不是单引号 ',不要看错了哦。
关系运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
输入输出
输入
echo 自动换行
printf 类似C语言
输出
直接给变量赋值
从键盘赋值,read 命令
使用命令行参数赋值
利用命令的输出结果赋值
从文件中读入数据赋值
引用
元字符:单条命令结束的分号“;”,重定向符<和>,以及刚提到的变量取值符$等。采用转义字符“\”加元字符的方式告诉Shell不使用特殊功能,并原样输出。使用转义字符取消了元字符的特殊含义,这样的操作称为引用。
单引号之间的所有内容都被引用了,这比使用转义字符高效许多。
3种引用方式:
-
转义字符:用于引用任意的单个字符。
-
单引号引用(强引用),不管引号里面是否有变量或者其他的表达式,都是原样输出。
-
双引号引用(弱引用),用于引用包含的字符串,但保留$、 \和`的特殊含义,即引号里面的变量或者函数会先解析再输出内容。
分支控制语句
文件测试:test 语句,[ n1 操作符 n2 ],注意有空格
整数测试:test 语句,[ n1 操作符 n2 ],((n1 操作符 n2))
字符串测试:字符串测试操作包括比较字符串是否相同,测试字符串的长度是否为0,[ 字符串1 = 字符串2 ],字符串测试运算符如下表:
| operator | 意义 |
|---|---|
| -n string | 测试以判断字符串是否不为空;字符串必须为test所识别 |
| -z string | 测试以判断字符串是否为空;字符串必须为test所识别 |
| string1 = string2 | 测试以判断 string1 是否与 string2 相同 |
| string1 != string2 | 测试以判断 string1 是否与 string2 不同 |
逻辑运算符
| Operator | 意义 |
|---|---|
| ! expr | 如果表达式评估为假,则为真 |
| expr1 -a expr2 | 如果 expr1 和 expr2 都为真,则结果为真,&& |
| expr1 -o expr2 | 如果 expr1 或 expr2 为真,则结果为真,|| |
注意:-a和-o在[]里面用,&&和||在[]外面用
if语句
单分支
if [ expression ];then code
fi
或者
if [ expression ]
then code
fi
双分支
if [ expression ];then code1
else code2
fi
或者
if [ expression ]
then code1
else code2
fi
多分支
if expression; then
command…
[elif expression; then
command…]
[else
command…]
fi
case语句
case value in
[ expression1) code1
;;#停止
expression2) code2
;;
…
*)code
]
esac
条件表达式匹配
| 条件表达式 | 说明 |
|---|---|
| * | 匹配任意字符 |
| ? | 匹配任意单个字符 |
| [abc] | 匹配a、b、c中的任意一个 |
| [a-n] | 匹配从a到n的任一字符 |
| | |
循环控制语句
Shell语言常用的循环语句:for、while、until、select循环语句,工作中常用的是for、while、until
1、while 命令
while expression; do
command…
done
2、until命令
until expression; do
command…
done
linux 磁盘管理
磁盘分区
在Linux中,每一个硬件设备都映射到一个系统的文件,包括硬盘、光驱等IDE或SCSI(Small Computer System Interface)设备。SCSI是一种用于计算机和智能设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准,SCSI是一种智能的通用接口标准。
磁盘分区命名方式
为各种IDE设备分配了一个由hd前缀组成的文件。为各种SCSI设备分配了一个由sd前缀组成的文件。
编号方法为英文字母表顺序。第一个IDE设备定义为hda;第二个IDE设备定义为hdb;以此类推。SCSI设备就应该是sda、sdb、sdc等。USB磁盘通常会被识别为SCSI设备,因此其设备名可能是sda。
磁盘命名规则为hdXY(或者 sdXY),其中X为小写英文字母,Y为数字。个别系统可能命名略有差异。
磁盘分区方法
对于一个新硬盘,首先需要对其进行分区。
centos系统默认是不支持ntfs格式的设备读取的
硬盘分区有2种,如表所示
| 分区类型 | 磁盘容量 | 分区软件 | 分区数 |
|---|---|---|---|
| MBR | <2TB | fdisk | 14个分区(4个主分区,扩展分区,逻辑分区 |
| GPT | 不限 | gdisk | 128个主分区 |
注意:从MBR转换到GPT或从GPT转换到MBR将会导致数据全部丢失!
MBR分区
采用MBR(Master Boot Record,主引导记录)分区表形式创建分区,可使用fdisk命令。
①查看磁盘和分区情况,使用fdisk命令,并添加“-l“参数可以查看整个系统所挂载的硬盘个数及分区数。
②MBR分区,采用MBR分区表,使用fidsk命令对sdc硬盘进行分区。
使用lsblk命令查看所有分区信息,使用ll命令可以查看到新分区的设备文件
在虚拟机或云主机上,分区后不需要重启系统,内核会自动识别到设备的新分区并为它创建设备文件。
在真实的物理硬盘上此时不会显示设备文件,需要重启系统或者使用partprobe命令。partprobe命令可以在不重启系统的情况下,让内核强制读分区表,并为新设备创建设备文件。
GPT分区
用GPT(GUID Partition Table,GUID磁盘分区表)创建分区,使用gdisk命令,其创建过程与MBR类似。
使用gdisk命令对sdd硬盘进行分区,系统显示创建新的GPT分区表。
操作成功后,如果为真实硬盘需执行partprobe命令。使用lsblk命令可以查看新分区信息。
分区格式化(创建文件系统)
分区后,需要格式化才能正常存取信息。格式化磁盘命令是mkfs。
输入“mxfs”后连续按2次tab键可以查看所有文件系统类型,CentOS 7的文件系统默认为XFS。
mkfs命令格式:mkfs [option] [-t type] [fs-options] device [block_size]
其中:type为文件系统格式,如ext4、 vfat、 ntfs等。device为设备名称,如/dev/hda1、 /dev/sdb1等。[block_size]为block大小,可选。
格式化交换分区的命令略有不同,不是 mkfs,而是 mkswap。
例如,将/dev/sdc2格式化为swap分区,使用如下命令:mkswap /dev/sdc2
磁盘挂载和卸载
1、挂载磁盘分区(mount命令)
要使用磁盘分区,还需要挂载该分区。挂载时指定需要挂载的设备和挂载目录(该挂载目录即是挂载点)。
mount命令格式为:mount -t type device dir
其中:type为文件系统格式,如 ext4、vfat、 ntfs等。device为设备名称,如/dev/hda1、/dev/sdb1。dir为挂载目录。一般dir在/dev下。
挂载成功后,就可以通过访问该目录访问该分区内的文件。未被使用的空目录,都可用于挂载分区。
查看文件系统的挂载情况df。
使用mount命令挂载是临时性的,系统重启后失效。用户可以修改文件/etc/fstab配置文件,使其永久有效。
新建2个目录/dsdb3,/dsdb5作为挂载点,然后用blkid命令查看设备的UUID。
从中找到sdb3和sdb5的分区,复制其UUID,并粘贴到配置文件/etc/fstab的末尾。
其中:分区sdb3的挂载点为dsdb3,文件系统为xfs,挂载选项为defaults,最后2个数字为9,表示不备份,不检测。分区sdb5的挂载点为dsdb5,文件系统为auto,挂载选项为defaults,最后2个数字为9,表示不备份,不检测。
df查看已挂载的设备信息
卸载磁盘分区(umount命令)
移除磁盘,如卸载USB磁盘、光盘或者某一硬盘分区,需要首先卸载该分区。umount命令格式:umount [device|dir],卸载时只需要一个参数,可以是设备名称,或者是挂载点(目录名称)。
对于没有卸载的磁盘,如遇到断电等突发情况,可能损坏文件系统目录结构或其中的文件。因此需要检查和修复磁盘分区。
检查和修复磁盘分区的命令为fsck。
fsck命令格式:fsck [option] device,其中, option选项可以省略,参数device 为设备名称,如/dev/hda1、 /dev/sdb1 等。
交换空间
当系统的物理内存不够用时,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间都没有什么操作的程序,这些释放的空间被临时保存到 Swap空间中,等到那些程序要运行时,再从 Swap中恢复保存的数据到内存中。Swap的调整对Linux服务器,特别是Web服务器的性能至关重要。调整Swap,有时可以越过系统性能瓶颈,节省系统升级费用。
Swap空间有两种形式:交换分区和交换文件
对Swap的读写都是磁盘操作。增加交换空间有以下两种方法。
1、使用分区
在安装OS时,划分出专门交换分区,空间大小要事先规划好,启动系统时自动进行mount。一旦设定好,就不能改变,除非重装系统。
2、使用swapfile(或者是整个空闲分区)
新建临时swapfile或者空闲分区,在需要时设定为交换空间,最多可以增加8个。交换空间的大小与CPU密切相关,如在i386系中,最多可以使用2GB的空间。在系统启动后,根据需要在2GB的总容量下增减。优点:比较灵活,比较方便;缺点是启动系统后需要手工设置。
运用swapfile增加交换空间涉及命令如下:
(1)free:查看内存状态命令,可以显示memory、swap、buffer cache等的大小及使用状况。
(2)dd:读取,转换并输出数据命令。
(3)mkswap:设置交换区。
(4)swapon:启用交换区,相当于mount。
(5)swapoff:关闭交换区,相当于umount。
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
linux LVM磁盘
逻辑卷
LVM(Logical Volume Manager)是逻辑卷管理的英文简写
物理卷(Physical Volume)处于LVM中的最底层,它可以是实际物理硬盘上的分区、整个物理硬盘或RAID设备。
卷组(Volume Group)是建立在物理卷之上,当卷组建立后便可动态添加物理卷到卷组中。
逻辑卷(Logical Volume)建立在卷组之上,卷组中的未分配空间可以用于建立新的逻辑卷,逻辑卷建立后便可动态地扩展和缩小空间。
物理块PE(Physical Extent)-PE是整个LVM 最小的储存区块,即信息都是由写入PE来处理的。LVM默认使用4MB的PE区块(类似于文件系统里面的block 大小),而LVM的LV最多仅能含有65534个PE (lvm1的格式),最大容量为4M*65534/(1024M/G)=256G。调整PE会影响到LVM的最大容量!PE在CentOS 6.x以后,由于直接使用lvm2的各项格式功能,因此这个限制已经不存在了。
与分区相比,逻辑卷最大的优势是可以进行扩容与数据迁移,且所有的操作都是在线的,即不需要卸载文件系统。
创建逻辑卷
物理硬盘初始化为物理卷命令pvcreate。命令格式:pvcreate [option]
查看物理卷的详细信息命令pvscan
创建卷组命令vgcreate
卷组(Volume Group)将多个物理卷组织成一个整体,屏蔽了底层物理卷细节。在卷组上创建逻辑卷时不用考虑具体的物理卷信息。命令格式:vgcreate [option] [arg]
创建逻辑卷命令lvcreate
该命令在卷组的可用物理扩展池中分配逻辑扩展。
通常,逻辑卷可以随意使用底层逻辑卷上的任意空间。修改逻辑卷将释放或重新分配物理卷的空间。
查看逻辑卷命令lvscan
格式化逻辑卷命令mkfs
挂载逻辑卷
逻辑卷格式完成后,还不能使用,因为逻辑卷还没有挂载到系统的某个目录上。挂载逻辑卷时,可以临时挂载,也可以永久挂载。
与挂载分区不同的是挂载逻辑卷,不需要使用UUID,使用设备名称即可。
逻辑卷名称不会发生变化,不会导致系统识别错误。
卷组扩容
若逻辑卷需要扩容,首先要用命令vgs查看其所属的卷组是否有空闲的容量。逻辑卷扩容时,若卷组中没有足够的存储空间,就需要增加卷组的容量。
vgextend命令可以将新的物理卷加入到卷组中。
例如,将物理硬盘/dev/sdd加入到逻辑卷组uservg中。
1、将物理硬盘/dev/sdd初始化成物理卷。
2、将物理卷加入逻辑卷组uservg中。
卷组缩减
当硬盘空间不足时,就需要减少卷组占用的空间。
如果删除的物理卷存有数据,需要先把数据移动到其他物理卷(保证有足够的空间存储数据)。
迁移物理卷的数据命令pvmove
逻辑卷扩容
逻辑卷最大的优点是可以弹性调节容量,逻辑卷存储空间不足时,就需要给扩容。
lvscan命令可以查看逻辑卷所属的卷组,lv1与lv2逻辑卷是属于uservg卷组。
逻辑卷扩容命令lvextend
逻辑卷组删除
vgdisplay 查看卷组包含的PV、LV信息
umount 卸载卷组上的逻辑卷
lvremove 删除逻辑卷LV
vgremove 删除卷组VG
pvremove 删除物理卷PV
编辑/etc/fstab 删除对应挂载点信息
重新挂载,查看逻辑卷信息
LVM快照应用环境
快照的主要作用是保留数据在某一刻的状态,磁盘快照文件和系统所对应的虚拟磁盘本身的大小不一样,快照比原数据小很多。
LVM提供逻辑卷快照功能,用户可以在某个时间点创建一个逻辑卷副本,它也占用卷组的存储空间,称为快照卷。
快照卷与原始的逻辑卷必须在同一个卷组。
快照卷是一种特殊的逻辑卷,它可以挂载在设备上。
Swap交换分区
当系统的物理内存不足时,就需要将物理内存中的一部分空间释放出来以供当前运行的程序使用。
被释放的空间可能来自一些很长时间没有运行的程序,它们被临时保存到Swap交换分区中,等到需要再次运行时,再从Swap分区恢复到内存中。
注意:只有在物理内存不足时,才使用Swap交换分区。
查看当前的交换分区可使用free命令,添加“-m”参数规定单位为M字节。
使用“swapon –s”命令查看交换分区大小及使用情况
交换分区可以在基本分区、逻辑卷或文件中创建,使用mkswap命令格式化即可。同时获取到UUID,挂载到swap上,类型为swap。用swapoff命令可以关闭交换分区,swapon命令可以开启交换分区。
在基本分区中增加交换分区
在逻辑卷中增加交换分区
在文件中增加交换分区
删除swap交换分区
1、停止正在使用的swap分区。
$ swapoff /dev/mapper/centos-swap
2、删除swap分区文件。
$ rm /dev/mapper/centos-swap
3、删除或注释在/etc/fstab文件中的以下开机自动挂载内容。
/dev/mapper/centos-swap swap swap default 0 0
文件系统
EXT文件系统
EXT(Extended file system,扩展文件系统)属于索引式文件系统,已经发展到ETX4,其中ETX2与EXT3已经淘汰。索引式文件系统好比带有目录的书本,目录会占用书的页面,索引信息也会占用存储空间。
硬盘的每一个分区都有一个引导扇区和一个文件系统。
文件系统又分为多个块组(Block Group)。
块组分为:
-
超级块(Super Block)
-
组描述表(GDT)
-
块位图(Block Bitmap)
-
索引节点位图(inode Bitmap)
-
索引结点表(inode Table)
-
数据块(Data Blocks)
索引节点表记录文件的属性(文件的元数据,metadata),包含:索引节点号、文件类型、权限、链接次数、文件所有者、大小、时间戳等信息。
使用dumpe2fs命令查看/dev/uservg/lv1文件系统的信息,包括文件系统的卷名、文件系统的UUID、文件系统的特性等。
在EXT文件系统上,新建一个文件的过程如下:
(1)确定使用者对新创建文件的目录有w与x权限。
(2)根据索引点位图找到没有使用的索引节点号码,并将文件的权限和属性写入。
(3)根据块位图找到没有使用的块号码,将文件的实际数据写入块中,且更新索引节点的块指向信息。
(4)将刚才写入的 索引节点与块信息同步更新索引节点位图与块位图 ,并更新超级块的内容。
一般将索引节点表与数据块称为数据存放区域。
将超级块、块位图与索引节点位图等称为元数据。
因为超级块、块位图及索引节点位图的数据是经常变动的,每次新增、移除、编辑都可能会影响到这三个部分的数据。
如果在执行上述第4步时,突然断电或系统内核发生错误,可能写入的信息仅有索引节点表及数据块而已,最后的同步更新的步骤并没有完成,这会造成metadata的内容与实际信息不一致。
当出现这种不一致的情况时,系统会自动修复。
若没有日志,系统会全盘扫描,该过程消耗较长的时间。若手动修复,则需要逐一排查,直到找到不一致文件。这样的情况造就了日志式文件系统的兴起。
为了避免上述文件系统不一致的情况发生,开发者提出了在文件系统中规划出一个区块,该区块专门记录写入或修订文件时的步骤,这样可以简化文件一致性检查。
步骤如下:
(1)准备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备写入的信息。
(2)实际写入:写入文件的权限与数据,更新元数据。
(3)结束:完成数据与元数据的更新后,在日志记录区块中完成文件的记录。
采用这种方式后,万一数据记录过程中出现了问题,系统只要去检查日志记录区块,就可以知道哪个文件出了问题,针对该问题做一致性检查即可,这样就可以实现文件系统的快速修复。这就是日志式文件系统的基础功能。
EXT故障
系统无法启动,fsck命令修复,Ctrl+d组合键重新启动,但没有解决根本问题。
磁盘只读的原因:一种是没有正常关机;二是磁盘故障。
(1)卸载分区。
(2)使用“fsck.ext4 -fy”修复分区。
(3)挂载分区,检查是否可以正常读写。如果仍旧不可以正常读写,请报修磁盘。
如果超级块损坏,则需要找到备份的超级块,然后利用备份的超级块恢复超级块。
XFS文件系统查看及修复
XFS文件系统同样是一种日志式文件系统,与EXT文件系统相比有如下特性。
-
高容量,支持大存储。
-
高性能,创建/修复文件系统快。
-
索引节点与块都是系统需要用到时才动态配置产生。
XFS文件系统有3个区:
-
数据区 (data section)
-
文件系统日志区 (log section)
-
实时运行区 (realtime section)
数据区与EXT文件系统数据区类似,包括索引节点、数据块、超级块等信息
使用xfs_info命令可以查看XFS文件系统信息
使用xfs_repair命令可以修复XFS文件系统,在修复前,需要先卸载。
mount详解
1、在虚拟机未开启之前新建一个硬盘sdg或逻辑卷。
2、把新硬盘格式化成xfs文件系统格式。
3、新建一个目录/dsdg
4、用mount命令把文件系统为XFS的/dev/sdg设备挂载到/dsdg目录上,可以添加“-t”参数选择文件系统类型,添加“-o”挂载选项为noexec(不允许执行二进制文件)。
5、挂载完成后,将/bin/date复制到/data01目录中,用ll查看date的执行权限为可执行,但实际执行时却不能执行。
当挂载选项为defaults时,系统会默认给予若干选项。
使用man工具查看mount中defaults的定义,当用户使用defaults选项时,它可以支持rw、suid、dev等挂载选项。
mount命令中常见的挂载选项如下
| 选项 | 作用 |
|---|---|
| rw | 读写 |
| ro | 只读 |
| pri | 指定优先级 |
| sync | 同步写入,直接往硬盘中写入,耗时长,效率低 |
| async | 异步写入,先写入到内存中,再写入硬盘 |
| acl | 支持acl功能 |
| usrquota | 支持用户级的磁盘配额功能 |
| grpquota | 支持组级的磁盘配额功能 |
| suid | 支持suid |
| exec | 允许执行二进制文件 |
| noexec | 不允许执行二进制文件 |
| dev | 支持设备文件 |
| nodev | 不支持设备文件 |
文件链接
在Linux系统中,文件链接分为两种:
符号链接 (Symbolic Link)
符号链接是指包含所链接文件的路径名。
注意:符号链接可以链接目录文件,也可以跨文件系统进行链接。
硬链接(Hard Link)
硬链接是指链接文件与原始文件的节点相同,即两者是同一个文件。
每添加一个硬链接,该文件的索引节点连接数就会增加1;只有当该文件的节点连接数为0时,该文件才彻底删除。
在使用硬链接时,注意:
–不允许给目录创建硬链接。
–硬链接只有在同一个文件系统中创建。
磁盘阵列
随着CPU性能的不断提升,运算速度可以达到每秒万亿次的浮点运算。与此同时,硬盘的性能却没有很大提升,成为计算机整体性能提升的瓶颈。
科学家提出了RAID(Redundant Array of Independent Disks,廉价磁盘冗余阵列)概念。
RAID技术是通过几种特定方式把若干硬盘组合成一个大的磁盘阵列,以提升容错能力与读写速率。
常见的RAID磁盘阵列类型有:
RAID 0
RAID 0也称为条带集或者条带卷,它是把至少2块以上硬盘串联在一起,组成一个卷组,并把数据分成若干小份,同时写入到每个硬盘中
在理想条件下,硬盘越多,读写速率越快,且利用率为100%。RAID 0是所有磁盘阵列类型中读写速率最快的,但不具备容错能力,一旦其中一块硬盘出现故障,整个系统的数据都会受到影响。RAID 0通常应用在对数据要求不高,但对速度要求高的场景。
RAID 1
RAID1也称为镜像集,2块硬盘为一组,数据同时写到这2块硬盘上,其中一份可视为数据的镜像
Raid 1具有容错能力,当某块硬盘出现故障,数据会自动以热交换的方式恢复正常。与Raid 0相比,Raid 1的读写速度较慢,硬盘利用率为50%。
RAID 5
RAID 5也称为带奇偶校验的条带集,至少需要3块硬盘。数据奇偶校验信息分别存放在每一行的某个硬盘上,任何一块设备出现故障,不会影响整个系统的数据,RAID 5占用一块硬盘存储奇偶校验信息,所以硬盘利用率为(n-1)/n。
由于要保存奇偶校验信息,其读写速率比RAID 0稍慢,但有一定的容错能力,3块硬盘可允许坏1块。
RAID 5可以理解为是RAID 0和RAID 1的折中方案,既保证读写速率,又在一定程度上兼顾了数据的安全。
一旦RAID 5某一块硬盘故障,所丢失的数据就需要通过奇偶验证信息计算,导致整体读写速度减慢。
如果更换一块新的硬盘,数据会有一个重建的过程,耗费时间视数据量而定在几十分到数小时不等。
如果在这个过程中又有其他硬盘出现故障,数据就会丢失。
RAID 6
RAID 6也称为带奇偶校验的条带集双校验,至少需要4块硬盘,硬盘利用率为(n-2)/n。
RAID 6读写速度快,有一定的容错能力,4块硬盘允许坏2块。RIAD 6 在服务器上比较少见,一般出现在专用的存储设备上。
RAID的实现方式有如下两种。
-
硬RAID:需要RAID卡,有CPU,处理速度快。
-
软RAID:通过操作系统实现。
实际环境中使用硬RAID,软RAID使用非常少。
安装madadm工具,创建RAID
lsof查看文件
lsof命令用于查看当前进程打开的文件,当意外地关闭了进程打开的文件,可以使用该命令进行恢复。
通过lsof恢复删除的文件
通过lsof恢复已删除的文件,前提条件的是这个文件有程序正在使用,可以通过lsof /path/to/filename能查看到正在使用此文件的程序。
杂记
cmd1&&cmd2 如果cmd1成功则执行cmd2
cmd1||cmd2 如果cmd1不成功则执行cmd2
cmd1|cmd2 这个是管道, 把cmd1的输出作为cmd2的输入
cmd1;cmd2 连续执行两条命令,先cmd1,然后cmd2,两个命令没有关系。不管cmd1是不是成功,都要执行cmd2
使用cd ~ 命令后,会进入用户的主目录
将逻辑分区建立在扩展分区上
vi/vim
‘u’ : 撤销上一个编辑操作
‘ctrl + r’ : 恢复,即回退前一个命令
‘U’ : 行撤销,撤销所有在前一个编辑行上的操作
在添加用户的时候可以使用 -d 参数来指定用户的用户主目录。
在Linux中,系统管理员(root)状态下的提示符是 #,默认为 $
linux操作系统关机可使用的命令是 init 0
Init 6是重新启动机器。
reboot也是重新启动机器。强制
shutdown -r now是立即停止然后重新启动
所有用户登录的缺省配置文件是 /etc/login.defs
安装Linux系统对硬盘分区时,必须有两种分区:根分区(/)、交换分区(swap)
将前一个命令的标准输出作为后一个命令的标准输入,称之为管道。
标准I/O提供了三种类型的缓冲,分别是全缓冲、行缓冲 和不带缓冲。
初始化互斥锁的宏是 PTHREAD_MUTEX_INIT ;
初始化条件变量的宏是 PTHREAD_COND_INIT ;
初始化读写锁的宏是 PTHREAD_RWLOCK_INIT;
用GCC编译过程可以被细分为四个阶段:预处理、编译、汇编和 链接
编译有线程的文件要加 -lpthread 参数
父进程等待子进程的结束,可以使用的函数是 wait() 和 waitpid() 。
mkdir 命令用来创建目录。
chmod 100 file 为脚本程序file文件所有者增加执行权的命令及参数
在常用的shell预定义变量中,$? 是命令执行后返回的状态。
显示Linux系统中正在运行的全部进程,应使用的命令及参数是 ps –a
“init”命令是所有进程的祖先,它的进程号始终为1
chown命令的作用是 改变文件或文件夹所属用户 。
用于复制文件的命令是 cp ,用于复制目录的命令是 cp -r 。
swap分区如果分配过大会带来 浪费硬盘空间、频繁死机问题 。
使用rpm可以很容易对rpm形式的软件包进行安装升级和 查询、卸载 及校验等操作。
压缩
tar –cvf jpg.tar *.jpg // 将目录里所有jpg文件打包成 tar.jpg
tar –zcvf jpg.tar.gz *.jpg // 打包成 jpg.tar 后,将其用 gzip 压缩,命名为 jpg.tar.gz
tar –jcvf jpg.tar.bz2 *.jpg // 打包成 jpg.tar 后,并且将其用 bzip2 压缩,命名为jpg.tar.bz2
tar –Zcvf jpg.tar.Z *.jpg // 打包成 jpg.tar 后,并且将其用 compress 压缩,命名为jpg.tar.Z
rar a jpg.rar *.jpg // rar格式的压缩,需要先下载 rar for linux
zip jpg.zip *.jpg // zip格式的压缩,需要先下载 zip for linux
解压
tar –xvf file.tar // 解压 tar 包
tar -zxvf file.tar.gz // 解压 tar.gz
tar -jxvf file.tar.bz2 // 解压 tar.bz2
tar –Zxvf file.tar.Z // 解压 tar.Z
unrar e file.rar // 解压 rar
unzip file.zip // 解压 zip
请简述主分区、扩展分区、逻辑分区的关系。 (注意语言准确性)
一块硬盘中刨除主分区以外剩余所有的空间都是扩展分区,所有的逻辑分区之和组成扩展分区。(1分)
linux中1-4是预留给主分区和扩展分区的,主分区至少要有1个,之多可以有4个,扩展分区至多只能有1个或者没有,但是主分区加上扩张分区数量不能超过4个。(2分)
扩展分区下必须再分逻辑分区,不然空间不能被格式化,逻辑分区的数量没有限制。(2分)
现有一个文件夹book,需要你归档压缩为book.tar.bz2的文件,请写出压缩及解压的步骤。
1)tar -jcvf book.tar.bz2 book(3分)
2)tar -jxvf book.tar.bz2(2分)
请简述进程与线程的区别。
1.进程有自己独立的地址空间;而线程共享进程的地址空间;
2.一个程序至少有一个进程,一个进程至少有一个线程;
3.线程是处理器调度的基本单位,但进程不是;
4.二者均可并发执行
5.多线程比多进程成本低,但性能更低。
按下列要求请你写出步骤完成题目(注意请把命令格式写完整) (10分)
A.建立组hello
B.建立用户Bill,该用户属于hello组
C.设置Bill密码为123
D.建立一个新的组bye
E.把Bill改到新建的bye组中
groupadd hello (1分)
useradd -d /home/Bill –g hello -s /bin/bash Bill(1分)
passwd Bill 输入123回车 再次输入123回车(1分)
groupadd bye(1分)
usermod -g bye Bill(1分)
请详细说明什么是shell,以及它的作用。
shell就是命令解释器,它提供了用户与操作系统之间基于命令行的交互界面,(2分)用户命令行输入命令,由shell对它们进行解释,并将其送往操作系统执行。(3分)
在Linux系统中,以文件的方式访问设备
静态路由设定后,若网络拓扑结构发生变化,需由__系统管理员___修改路由的设置。
编写的Shell程序运行前必须赋予该脚本文件执行权限。
cd / 切换到根目录
cd ~ 切换到主目录
cd - 切换到之前工作目录
请简述Linux操作系统有什么优点?
答:Linux的主要优点包括:
提供了先进的网络支持:内置TCP/IP协议;
真正意义上的多任务、多用户作系统;
与UNIX系统在源代码级兼容,符合IEEE POSIX标准;
支持数十种文件系统格式;
开放源代码,用户可以自己对系统进行改进;
采用先进的内存管理机制,更加有效地利用物理内存。
Init进程是系统启动之后的第一个用户进程,所以它的pid(进程编号)始终为1。init进程上来首先做的事是去读取/etc/目录下inittab文件中initdefault id值,这个值称为运行级别(run-level)。它决定了系统启动之后运行于什么级别。运行级别决定了系统启动的绝大部分行为和目的。这个级别从0到6 ,具有不同的功能。不同的运行级定义如下:
0 - 停机(千万别把initdefault设置为0,否则系统永远无法启动)
1 - 单用户模式
2 - 多用户,没有 NFS
3 - 完全多用户模式(标准的运行级)
4 – 系统保留的
5 - X11 (x window)
6 - 重新启动 (千万不要把initdefault 设置为6,否则将一直在重启 )
交换分区一般是内存乘以1.5或者2