词性标注与命名实体识别
词性标注与命名实体识别
一 词性标注
-
- 简介
词性是词汇基本的语法属性,通常也称为词类。词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。例如,表示人、地点、事物以及其他抽象概念的名称即为名词,表示动作或状态变化的词为动词,描述或修饰名词属性、状态的词为形容词。如给定一个句子:“这儿是个非常漂亮的公园”,对其的标注结果应如下:“这儿/代词 是/动词 个/量词 非常/副词 漂亮/形容词 的/结构助词 公园/名词”。
在中文中,一个词的词性很多时候都不是固定的,一般表现为同音同形的词在不同场景下,其表示的语法属性截然不同,这就为词性标注带来很大的困难;但是另外一方面,从整体上看,大多数词语,尤其是实词,一般只有一到两个词性,且其中一个词性的使用频次远远大于另一个,即使每次都将高频词性作为词性选择进行标注,也能实现80%以上的准确率。如此,若我们对常用词的词性能够进行很好地识别,那么就能够覆盖绝大多数场景,满足基本的准确度要求。
词性标注最简单的方法是从语料库中统计每个词所对应的高频词性,将其作为默认词性,但这样显然还有提升空间。目前较为主流的方法是如同分词一样,将句子的词性标注作为一个序列标注问题来解决,那么分词中常用的手段,如隐含马尔可夫模型、条件随机场模型等皆可在词性标注任务中使用。本本继续介绍如何使用Jieba分词来完成词性标注任务。
-
- 词性标注规范
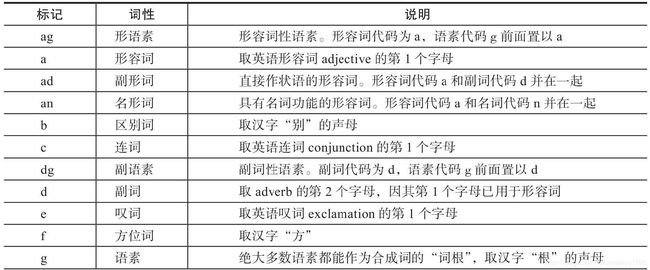
词性标注需要有一定的标注规范,如将词分为名词、形容词、动词,然后用“n”“adj”“v”等来进行表示。中文领域中尚无统一的标注标准,较为主流的主要为北大的词性标注集和宾州词性标注集两大类。两类标注方式各有千秋,一般我们任选一种方式即可。本书中采用北大词性标注集作为标准,其部分标注的词性如表4-1所示。

-
- jieba分词中的词性标注
这里将介绍其词性标注功能。类似Jieba分词的分词流程,Jieba的词性标注同样是结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和HMM共同作用。词性标注流程如下。
- 首先基于正则表达式进行汉字判断,正则表达式如下:

- 若符合上面的正则表达式,则判定为汉字,然后基于前缀词典构建有向无环图,再基于有向无环图计算最大概率路径,同时在前缀词典中找出它所分出的词性,若在词典中未找到,则赋予词性为“x”(代表未知)。当然,若在这个过程中,设置使用HMM,且待标注词为未登录词,则会通过HMM方式进行词性标注。
- 若不符合上面的正则表达式,那么将继续通过正则表达式进行类型判断,分别赋予“x”“m”(数词)和“eng”(英文)。
二 命名实体识别
2.1 命名实体识别简介
与自动分词、词性标注一样,命名实体识别也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。由于这些命名实体数量不断增加,通常不可能在词典中穷尽列出,且其构成方法具有各自的规律性,因此,通常把对这些词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别(Named Entities Recognition,NER)。NER研究的命名实体一般分为3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。由于数量、时间、日期、货币等实体识别通常可以采用模式匹配的方式获得较好的识别效果,相比之下人名、地名、机构名较复杂,因此近年来的研究主要以这几种实体为主。
命名实体识别当前并不是一个大热的研究课题,因为学术界部分认为这是一个已经解决了的问题,但是也有学者认为这个问题还没有得到很好地解决,原因主要有:命名实体识别只是在有限的文本类型(主要是新闻语料)和实体类别(主要是人名、地名)中取得了效果;与其他信息检索领域相比,实体命名评测语料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性很差。
同时,中文的命名实体识别与英文的相比,挑战更大,目前未解决的难题更多。命名实体识别效果的评判主要看实体的边界是否划分正确以及实体的类型是否标注正确。在英文中,命名实体一般具有较为明显的形式标志(如英文实体中的每个词的首字母要大写),因此其实体边界识别相对容易很多,主要重点是在对实体类型的确定。而在汉语中,相较于实体类别标注子任务,实体边界的识别更加困难。
中文命名实体识别主要有以下难点:
●各类命名实体的数量众多。根据对人民日报1998年1月的语料库(共计2305896字)进行的统计,共有人名19965个,而这些人名大多属于未登录词。
●命名实体的构成规律复杂。例如由于人名的构成规则各异,中文人名识别又可以细分为中国人名识别、日本人名识别和音译人名识别等;此外机构名的组成方式也最为复杂,机构名的种类繁多,各有独特的命名方式,用词也相当广泛,只有结尾用词相对集中。
●嵌套情况复杂。一个命名实体经常和一些词组合成一个嵌套的命名实体,人名中嵌套着地名,地名中也经常嵌套着人名。嵌套的现象在机构名中最为明显,机构名不仅嵌套了大量的地名,而且还嵌套了相当数量的机构名。互相嵌套的现象大大制约了复杂命名实体的识别,也注定了各类命名实体的识别并不是孤立的,而是互相交织在一起的。
●长度不确定。与其他类型的命名实体相比,长度和边界难以确定使得机构名更难识别。中国人名一般二至四字,常用地名也多为二至四字。但是机构名长度变化范围极大,少到只有两个字的简称,多达几十字的全称。在实际语料中,由十个以上词构成的机构名占了相当一部分比例。
在分词章节,我们介绍了分词主要有三种方式,主要有基于规则的方法、基于统计的方法以及二者的混合方法。这在整个NLP的各个子任务基本上也多是同样的划分方式,命名实体识别也不例外:
1)基于规则的命名实体识别:规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。当提取的规则能够较好反映语言现象时,该方法能明显优于其他方法。但在大多数场景下,规则往往依赖于具体语言、领域和文本风格,其编制过程耗时且难以涵盖所有的语言现象,存在可移植性差、更新维护困难等问题。
2)基于统计的命名实体识别:与分词类似,目前主流的基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
3)混合方法:自然语言处理并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统,在很多情况下是使用混合方法,结合规则和统计方法。
序列标注方式是目前命名实体识别中的主流方法,鉴于HMM在之前的章节已有介绍,本节重点介绍基于条件随机场的方法。
2.2 基于条件随机场的命名实体识别
在进入条件随机场的命名实体识别之前,我们先温习下分词章节中介绍到的HMM。HMM将分词作为字标注问题来解决,其中有两条非常经典的独立性假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关(一阶马尔可夫模型)。通过这两条假设,使得HMM的计算成为可能,模型的计算也简单许多。但多数场景下,尤其在大量真实语料中,观察序列更多的是以一种多重的交互特征形式表现出来,观察元素之间广泛存在长程相关性。这样,HMM的效果就受到了制约。
基于此,在2001年,Lafferty等学者们提出了条件随机场,其主要思想来源于HMM,也是一种用来标记和切分序列化数据的统计模型。不同的是,条件随机场是在给定观察的标记序列下,计算整个标记序列的联合概率,而HMM是在给定当前状态下,定义下一个状态的分布。
条件随机场的定义为:
设X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Ym)是联合随机变量,若随机变量Y构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y|X)称为条件随机场(Conditional Random Field,CRF),即
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v) (4.1)
其中w~v表示图G=(V,E)中与结点v有边连接的所有节点,w≠v表示结点v以外的所有节点。
这里简单举例说明随机场的概念:现有若干个位置组成的整体,当给某一个位置按照某种分布随机赋予一个值后,该整体就被称为随机场。以地名识别为例,假设我们定义了如表4-2所示规则。
表4-2 地理命名实体标记
现有个由n个字符构成的NER的句子,每个字符的标签都在我们已知的标签集合(“B”“M”“E”“S”和“O”)中选择,当我们为每个字符选定标签后,就形成了一个随机场。若在其中加一些约束,如所有字符的标签只与相邻的字符的标签相关,那么就转化成马尔可夫随机场问题。从马尔可夫随机场到条件随机场就好理解很多,其假设马尔可夫随机场中有X和Y两种变量,X一般是给定的,Y是在给定X条件下的输出。在前面的例子中,X是字符,Y为标签,P(X|Y)就是条件随机场。
在条件随机场的定义中,我们并没有要求变量X与Y具有相同的结构。实际在自然语言处理中,多假设其结构相同,即
X=(X1,X2,X3,…,Xn),Y=(Y1,Y2,Y3,…,Yn) (4.2)
结构如图4-1所示。
图4-1 线性链条件随机场
一般将这种结构称为线性链条件随机场(linear-chain Conditional Random Fields,linear-chain CRF)。其定义如下:
设X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Yn)均为线性链表示的随机变量序列,若在给定的随机变量序列X的条件下,随机变量序列Y的条件概率分布P(Y|X)构成条件随机场,且满足马尔可夫性:
P(Yi|X,Y1,Y2,…,Yn)=P(Yi|X,Yi-1,Yi+1) (4.3)
则称P(Y|X)为线性链的条件随机场。(注意,本书中如非特别声明,所说的CRF指的就是线性链CRF。)
细心的读者会发现,相较于HMM,这里的线性链CRF不仅考虑了上一状态Yi-1,还考虑后续的状态结果Yi+1。我们在图4-2中对HMM和CRF做一个对比。

图4-2 HMM和线性链CRF联系图
在图4-2中,可以看到HMM是一个有向图,而线性链CRF是一个无向图。因此,HMM处理时,每个状态依赖上一个状态,而线性链CRF依赖于当前状态的周围结点状态。
对于线性链CRF的算法思想已经介绍不少,接下来讲解如何将其应用于命名实体识别过程中。
仍以地名识别为例,对句子“我来到牛家村”进行标注,正确标注后的结果应为“我/O来/O到/O牛/B家/M村/E”。采用线性链CRF来进行解决,那么(O,O,O,B,M,E)是其一种标注序列,(O,O,O,B,B,E)也是一种标注选择,类似的可选标注序列有很多,在NER任务中就是在如此多的可选标注序列中,找出最靠谱的作为句子的标注。
判断标注序列靠谱与否就是我们要解决的问题。就上面的两种分法,显然第二种没有第一种准确,因为其将“牛”和“家”都作为地名首字标成了“B”,一个地名两个首字符,显然不合理。假如给每个标注序列打分,分值代表标注序列的靠谱程度,越高代表越靠谱,那么可以定一个规则,若在标注中出现连续两个“B”结构的标注序列,则给它低分(如负分、零分等)。
上面说的连续“B”结构打低分就对应一条特征函数。在CRF中,定义一个特征函数集合,然后使用这个特征集合为标注序列进行打分,据此选出最靠谱的标注序列。该序列的分值是通过综合考虑特征集合中的函数得出的。
在CRF中有两种特征函数,分别为转移函数tk(yi-1,yi,i)和状态函数sl(yi,X,i)。tk(yi-1,yi,i)依赖于当前和前一个位置,表示从标注序列中位置i-1的标记yi-1转移到位置i上的标记yi的概率。sl(yi,X,i)依赖当前位置,表示标记序列在位置i上为标记yi的概率。通常特征函数取值为1或0,表示符不符合该条规则约束。完整的线性链CRF的参数化形式如下:

其中

Z(x)是规范化因子,其求和操作是在所有可能的输出序列上做的;λk和μl为转移函数和状态函数对应的权值。
通常为了方便计算,将式(4.5)简化为下式:

对应的Z(x)表示如下:
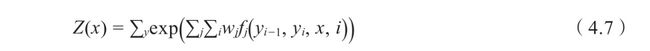
其中,fj(yi-1,yi,x,i)为式(4.4)中tk(yi-1,yi,i)和sl(yi,X,i)的统一符号表示。
三 总结
主要讲解了词性标注和命名实体识别技术。对于词性标注,在给出基础概念和技术后,简单讲解了标注的规范,然后介绍了其在Jieba分词中的使用方法。对于命名实体识别,在介绍完基础概念和常用方法后,重点介绍了另一种基于序列标注的模型——条件随机场。