网易MySQL数据库工程师微专业学习笔记(九)
一、数据库备份相关的基本知识
1. 数据库备份的用途
数据库备份的用途主要有两个,第一是数据灾备的用途,即应对由于硬件故障、程序bug或认为误操作导致的数据丢失情况;第二是制作镜像库的用途,即应对需要将数据迁移至统计用数据库或其他情况需要一个镜像的数据库。
2. 数据库备份的内容
数据库备份的内容除了数据文件或文本格式的数据以外还需要备份操作日志,在mysql中就是指binlog文件。备份操作日志的目的是让数据能够恢复到一个准确的时间点,因为两个数据备份数据备份之间一定是有时间间隔的,如果不保存操作日志,则在两个数据备份的时间间隔内丢失的数据将无法恢复,如下图所示。
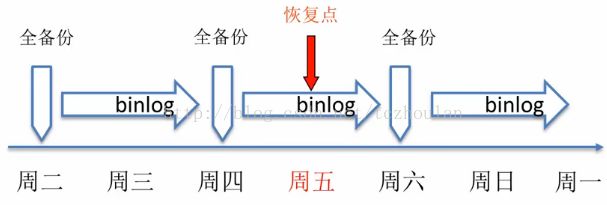
假设某个数据库每两天备份一次,那么如果在这两天的中间(即图中周五的时候)由于误操作误删除了数据,如果没有操作日志文件则只能恢复出周四备份时的数据,备份后到误操作中间新增的数据将无法找回。
3. 冷备份与热备份
冷备份是指在数据库服务关闭的情况下对数据文件的直接拷贝 ,这是基于文件系统的拷贝,这种备份非常简单同时也非常的快,但是问题在于需要关停数据库服务,这对于高可用要求的数据库往往是不能接受的。热备份就是通过专门的备份工具来备份数据,而不需要关停数据库服务。
4. 物理备份与逻辑备份
物理备份是指将数据库的数据以数据页的形式拷贝走,这种方式拷贝数据比较快,但是根据不同的存储引擎需要不同的备份工具来进行备份。逻辑备份是指将数据导出为裸数据(如导出csv)或sql语句,这种方式导出数据不需要考虑存储引擎的差异,比较方便,但是数据的恢复比较慢,只适用于数据量比较小的情况。
5. 本地备份与远程备份
本地备份就是将数据备份到数据库服务器上,这种备份对于数据库服务器的磁盘空间有一定的要求,但是备份速度相对于远程备份较快,因为远程备份的速度往往还会收到网络带宽的影响。远程备份就是通过远程连接连接到数据库,然后备份,当数据库服务器磁盘空间不足的时候可以选择远程备份。
6. 全量备份与增量备份
全量备份就是指将数据库完整的备份,适合备份数据量不是非常大的库。增量备份是指只备份上次备份以来发生修改的数据,如果数据量非常大,完整备份时间非常长,就可以用增量备份来结合全量备份的方法来备份。如一周做一次全量备份,一周做一次增量备份。相对于用binlog来恢复数据用增量备份来恢复数据会更快。
7. 备份周期
备份周期的设定主要考虑三个方面。第一,考虑数据库的大小,数据库越大备份的周期就应该越长,因为数据库越大备份所需要的时间就越长;第二,对于恢复速度的要求,如果需要能够快速恢复数据那就需要频繁的备份,这样当要恢复数据时可以用最靠近的备份来恢复;第三,考虑备份的方式,如果时全量备份则备份周期应该长一些,而如果是增量备份则可以备份的频繁一些。
8. 常用的备份工具
mysql常用的备份工具一般有两个,一个是mysqldump,这个工具是mysql自带的备份工具,实现的是逻辑备份,并且支持热备份,适合备份一些数据量比较小的库;另一个是xtrabackup,这个工具是由percona公司提供,实现的是物理备份,也支持热备份。此外还有一些备份工具如:mydumper、Lvm等。
二、mysqldump使用方法
mysqldump是mysql自带的备份工具,只要安装了mysql就可以使用mysqldump。mysqldump完成的是逻辑备份,因此其备份对于所有的存储引擎都是可用的,其备份文件的格式有.sql和.csv两种,默认为.sql格式。下面介绍mysqldump的具体使用方法。
1. 备份所有数据库
在命令行模式下使用如下命令。
mysqldump -h127.0.0.1 -P3306 -uroot -p --all-databases > D:/all_db.sql2. 备份指定数据库
在命令行模式下使用如下命令。
mysqldump -h127.0.0.1 -P3306 -uroot -p --databases gz > D:/gz_db.sql3. 备份指定的表
在命令行模式下使用如下命令。
mysqldump -h127.0.0.1 -P3306 -uroot -p myblog account article > D:/myblog_db.sql4. 一致性备份
一致性备份就是只备份某个时间点下的数据。一般情况下数据备份需要一段时间,而在这段时间内如果数据发生了变更且当前该数据还没有被备份则备份工具就会将当前变更的数据备份。而一致性备份在备份前开启一个事务并在这个事务内进行备份,则可以保证备份的数据都是处在当前备份开始的这个时刻的,这就是一致性备份。此外,一般的备份当备份到一个表的时候都会锁表,而在一致性备份模式下不会锁表,所以一般推荐使用一致性备份。在命令模式下执行如下命令,就可以完成一致性备份。
mysqldump --single-transaction -h127.0.0.1 -P3306 -uroot -p --all-databases > D:/all_db.sql5. 远程备份
mysqldump远程备份就是将命令中-h后面的ip地址改为远程服务器的ip地址即可,这里不再赘述。
6. 备份txt格式文件
在命令行模式下使用如下命令。
mysqldump --single-transaction -h127.0.0.1 -P3306 -uroot -p --fields-terminated-by=, myblog -T D:/tmp参数--fields-terminated-by后面跟的是数据间的分隔符,-T后面跟的是数据备份到的目录。备份成功后会在制定的目录下生成以数据库中的表命名的多个.sql和.txt文件,.sql中保存的是表结构的创建语句,.txt中保存的是以制定的分隔符分隔的数据,当然可以将.txt变为.csv格式然后用excel打开。转为csv并用excel打开的时候要注意一下当前txt的编码格式,否则可能会出现乱码。另外,需要去my.ini文件中修改一下secure-file-priv这个参数的值,将其修改为-T后面的路径,否则会提示没有权限的错误。
三、xtrabackup
xtrabackup是由percona公司开发的一款开源的备份工具,其优点有支持限速备份、支持流备份、支持增量备份、支持备份文件的压缩与加密、支持并行备份与恢复。xtrabackup的备份原理如下图所示。

当xtrabackup开始备份时,xtrabackup会开启两个线程,一个将innodb中的数据文件备份到备份目录,一个监听innodb的redo log文件,如果redo log文件被修改就将redo log中修改的信息也备份走,从而让备份期间修改的数据也能被完整的保存下来的,因此xtraback完成的必然是一致性备份。
xtrabackup是为innodb引擎的备份而开发的,因此对于其他引擎的备份是无法实现的,为此percona在xtrabackup中添加了一个脚本innobackupex,这样就可以对innodb和其他的引擎进行备份了。其备份的流程如下。
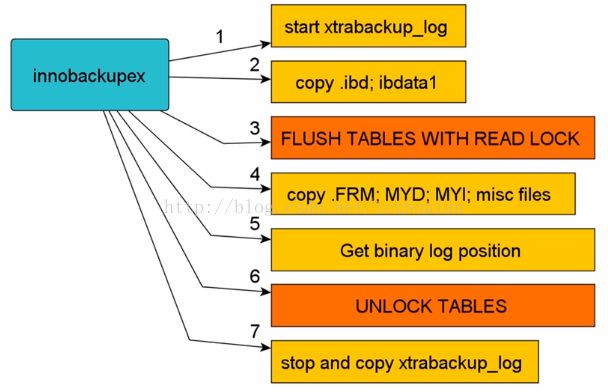
首先innobackupex通过原有的xtrabackup脚本对innodb的表完成备份,然后执行一个flush tables with read lock,就是给数据库中的表加一个读锁,这样就不会有新数据进来了,因为像myisam这样的存储引擎是不支持事务的,所以没有redo,因此要保证一致性就要给表加锁。接着备份数据,再记录备份所处的binlog的位置。最后释放锁并结束备份。因为当备份非innodb中的表需要锁表,所以推荐数据库中尽量都是用innodb表,这样可以减少备份过程中的锁表时间。
下面介绍如何使用xtrabackup,首先需要去percona的官网上下载xtrabackup,注意下载的时候下载Linux - Generic这个版本,这个版本中的是二进制文件,可以拿来直接使用而与具体是什么版本的linux系统无关,也不需要具体安装十分的方便。下载后解压文件,然后将文件夹下的bin文件路径加入系统参数中,命令如下。
export PATH=/usr/xtrabackup-2.4.6/bin:$PATHinnobackupex --help1. 全备份
备份所有的数据命令十分简单,如下。
innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 /dbbackup命令中--defaults-file参数后面给定的是mysql配置文件的路径,--user给定的时用户名,--password给定的是密码,最后的/dbbackup是备份文件存储的路径,备份完成后会再备份路径下生成一个已备份时间命名的文件夹,如下图所示。

而这个文件夹里就是备份的数据,如何使用将在下面数据恢复中介绍。
2. 增量备份
做增量备份前首先执行如下sql命令,修改一下数据。
create database gz;
use gz;
create table bin(a int);
insert into bin values(1);
insert into bin values(2);
insert into bin values(3);innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 --incremental --incremental-dir /dbbackup/2017-03-05_22-25-58 /dbbackup/
3. 流备份
流备份就是将备份和压缩同时完成的一种备份,这种方式相对于先备份,再将备份文件压缩减少了IO的次数,所以更快。执行如下命令完成流备份。
innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 --stream=xbstream /dbbackup/ > /dbbackup/stream.bak4. 并行备份
并行备份就是用多线程来备份数据,命令如下。
innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 --parallel=4 /dbbackup/5. 限速备份
执行如下代码进行限速备份。
innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 --throttle=1 /dbbackup/
6. 压缩备份
执行如下代码实现压缩备份。
innobackupex --defaults-file=/etc/mysql/my.cnf --user=root --password=01491696 --compress --compress-thread=4 /dbbackup/
7. 其他参数说明
xtrabackup还有许多的参数可以设置,这里再记录几个常用的。首先是--kill-long-queries-timeout,这个参数是设定当xtrabackup被一些sql阻塞时等待多久后杀死这些查询线程,默认为0表示不去杀死这些线程,永远等待。--kill-long-query-type表示等待一段时间后可以杀死哪些类型的sql操作,默认为all表示可以杀死所有类型的sql操作,也可以设为update、delete等。还有--slave-info,当备份是用于从库的时候可以添加这个参数,这样就会记录当前备份所到的binlog的位置。
四、如何制订备份策略
备份策略的制定需要根据具体情况和系统环境来制定,通常需要考虑以下几个因素。
1. 数据库是不是都是innodb表,如果是那么可以使用热备份,如果是像myisam的表,备份时会造成锁表,就需要考虑其他的备份方式了。
2. 数据量大小
数据量比较小的时候可以使用mysqldump来进行逻辑备份,数据量比较大的时候可以使用xtrabackup来进行物理备份。当数据量非常庞大的时候可以使用全量备份结合增量备份的方式来进行备份。
3. 数据库服务器本地磁盘空间是否充足
如果数据库服务器本地磁盘空间充足可以将数据库备份到本地,如果空间不足就只能备份到远程机器。
4. 需要多块恢复数据库
需要多块恢复数据库,决定了备份的频率。如果是重要的数据库,要求异常后能够快速恢复数据库,那么可以将备份的频繁一些,例如几个小时或者每个小时备份一次。如果不需要很快的恢复数据库,则可以每天或者每周备份一次,其他时候使用binlog来保证数据不丢失。
五、数据恢复
数据恢复基本都是基于良好的数据备份的,如果没有良好的数据备份那么数据恢复也就无从谈起了。一般在运维过程中需要进行数据恢复的场景有如下几个。
1. 硬件故障
当线上服务器长时间运行后就可能出现硬件故障,例如磁盘损坏。
2. 人为删除
有时候因为数据库管理人员的失误或者系统被入侵导致数据被删除,例如之前携程网的前员工侵入携程系统删除数据。
3. 业务回滚
例如一些线上游戏中常常出现由于游戏的bug需要回档。
4. 正常需求
例如有时候需要查看某个历史时刻的数据,或者创建一个镜像库来模拟线上的具体情况等。
要能够顺利的恢复数据就需要保证有有效备份和完整的binlog,此外针对不同的情况也要设计采用不同的恢复方法,让恢复尽可能的简单快速。例如下图中的情况。

要将数据恢复到上面的故障时间点,最常见的恢复手段就是用备份4加上备份4到故障时间前的binlog来恢复数据,但是这未必就是最好的恢复方法。因为这种恢复比较慢,如果故障指示执行错了几条命令,例如误删了几条数据,那么直接查看binlog并根据执行的错误命令生成对应的反转命令并执行就可以恢复数据了,不过这种恢复方法只有在binlog为row模式下才有效。
六、mysqldump恢复数据
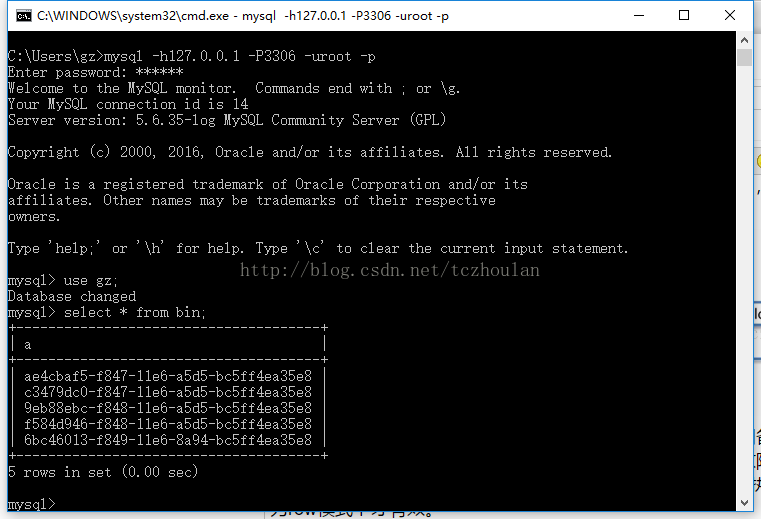
首先我在我创建了一个gz数据库,里面有一张bin表,表内有几行数据,如下图所示。
然后用drop删除gz数据库,结果如下,可以看到gz库已经被删除。
然后在mysql中执行如下命令恢复数据。
source D:/gz_db.sql;
七、xtrabackup恢复数据
1. 全量备份恢复
全量备份的恢复非常简单,只要执行如下命令即可。
innobackupex --apply-log /dbbackup/2017-03-08_16-01-26恢复完成后需要,关闭mysql服务,然后将恢复的备份文件复制到mysql的数据存储路径下,最后重启mysql服务才能让恢复生效。
具体如下,定位到/dbbackup/2017-03-08_16-01-26路径下,将以下几个文件复制到mysql的数据路径下。
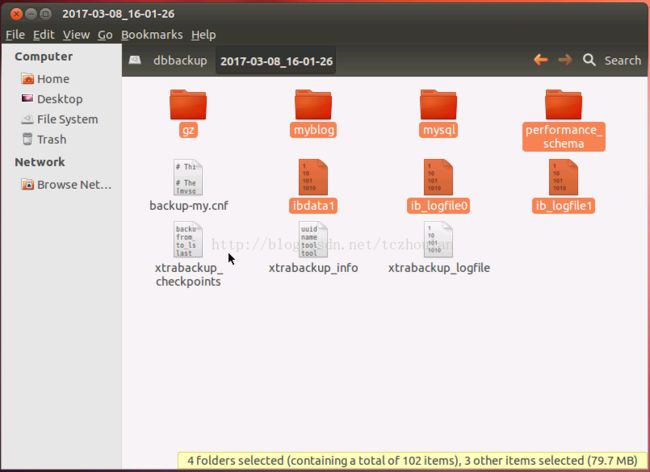
选中的文件中文件夹代表的是具体的数据库,ibdata1、ib_logfile0和ib_logfile0是innodb的事务日志文件。所有基于innobackupex备份(包括增量备份、流备份、压缩备份)的文件恢复后都需要执行这样的操作来实际恢复数据,后面就不再赘述了。
2. 增量备份恢复
首先增量备份的恢复必然是基于一个全量备份的,因此首先要恢复这个基础的全量备份,命令如下。
innobackupex --apply-log --redo-only /dbbackup/2017-03-09_16-42-56然后在全量备份的基础上恢复增量备份,如果有多个增量备份则最后一个增量备份的恢复命令如下。
innobackupex --apply-log /dbbackup/2017-03-09_16-42-56 --incrementa-dir=/dbbackup/2017-03-09_17-18-24如果这个增量备份不是最后一个增量备份,则恢复命令如下。
innobackupex --apply-log --redo-only /dbbackup/2017-03-09_16-42-56 --incrementa-dir=/dbbackup/2017-03-09_17-18-24然后将恢复的全量备份文件夹中的数据复制到mysql的数据路径下就完成了恢复。
3. 压缩备份恢复
首先执行如下命令解压压缩备份文件。
--innobackupex --decompress /dbbackup/2017-03-09_21-58-00然后再执行恢复命令恢复解压后的数据,命令如下。
innobackupex --apply-log /dbbackup/2017-03-09_21-58-004. 流备份恢复
首先也是要解压流备份文件,之前我使用xbstream这个工具进行流备的,所以需要用xbstream命令解压,命令如下。
xbstream -C stream -x < stream.bak解压后同样用apply命令恢复解压后的文件。命令如下。
innobackupex --apply-log /dbbackup/stream恢复备份可以通过并行备份来加快恢复的速度,命令如下。
--innobackupex --parallel=4 --apply-log --use-memory=200MB /dbbackup/stream命令中参数--parallel指定的是并行恢复所用的线程数,这里指定的是4。--use-memory指定的是恢复时的数据缓冲池大小,这里指定的是200MB。
八、binlog恢复数据
使用binlog恢复数据不需要安装什么软件,直接用mysql自带的mysqlbinlog工具即可。具体使用方法如下。
首先创建一张测试用的测试表t1,代码如下。
create table t1(id int);
show master status;
从结果中可以看出当前binlog的文件名是mysql-bin.000002,position记录的位置到1411。下面向t1表中插入一些数据,代码如下;
insert into t1 values(1);
insert into t1 values(2);
insert into t1 values(3);
下面清空t1中的数据,命令如下。
truncate t1;mysqlbinlog --start-position=1411 --stop-position=1963 C:/tmp/mylog/mysql-bin.000002|mysql -h127.0.0.1 -P3306 -uroot -p