知识图谱(二)——知识推理
知识推理是知识图谱中很重要的一部分,主要用于推理暗含的知识(丰富知识图谱),检查知识库的不一致(知识清洗)
知识推理分类
演绎推理
从一般到特殊的过程.从一般性的前提出发,通过推导,得到具体描述或个别结论(三段论),结论已经蕴含一般性知识中,只是通过演绎推理揭示出来,不能得到新知识.
归纳推理
从特殊到一般的推理过程.从一类事物的大量特殊事例出发,去推出该类事物的一般性结论(数学归纳法),推出的结论没有包含在已有内容中,增加了新知识.
确定性推理&不确定推理
数值推理&符号推理
基于表示学习的推理
归纳推理
归纳逻辑程序设计(Inductive Logic Programming, ILP)使用一阶谓词逻辑来进行知识表示,通过修改和扩充逻辑表达式来完成对数据的归纳

FOIL(First Order Inductive Learner)算法
利用序贯覆盖实现规则学习
Algorithm
1. 从空规则开始,将目标谓词作为规则头
2. 逐一将其他谓词加入规则提进行考察,按预定标准评估规则的优劣并选取最优规则
3. 将该规则覆盖的训练样例去除,以剩下的训练样例组成训练集重复上述过程评估准则
其中, m^+/m^− m ^ + / m ^ − 为增加候选文字后新规则覆盖的正反例数目, m+/m− m + / m − 表示原规则所覆盖的曾凡丽数目.(类似于决策树的信息增益)
上述的归纳逻辑程序设计(ILP)具有以下缺点:需要目标谓词的正例和反例,同时暗含封闭世界假设(即所有未声明是正例的样本都是反例)
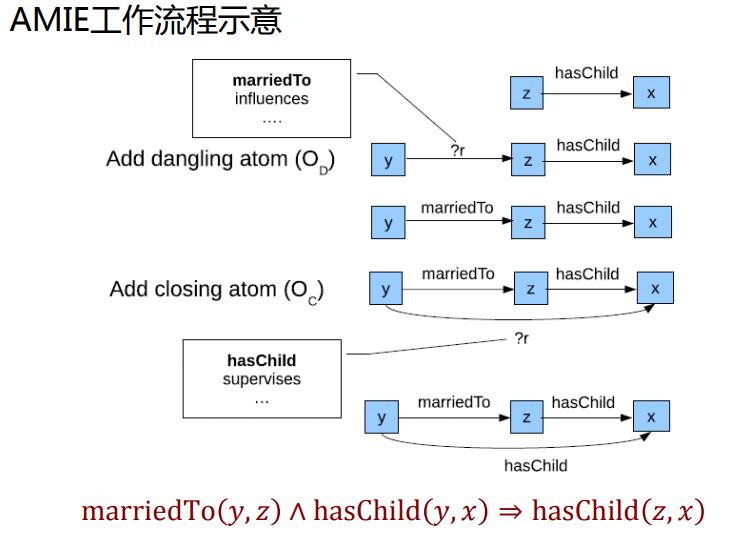
AMIE算法
不完备知识库的关联规则挖掘(Association Rule Mining under Incomplete Evidence,AMIE)支持从不完备知识库中,挖掘闭式规则
AMIE依次学习预测每种关系的规则。对于每种关系,从规则体为空的规则开始,通过三种操作扩展规则体部分,保留支持度大于阈值的候选(闭式)规则。
- 添加悬挂边:悬挂边是指边的一端是一个未出现过的变量,而另一端(变量或常量)是在规则中出现过的
- 添加实例边:实例边与悬挂边类似,边的一端也是在规则中出现过的变量或常量,但另一端是未出现过的常量,也就是知识库中的实体
- 添加闭合边 :闭合边则是连接两个已经存在于规则中的元素(变量或常量)的边。
评估准则
- 支持度:同时符合规则体和规则头的实例数目
- 置信度:支持度除以仅符合规则体的实例数目
- PCA置信度
路径排序算法
路径排序算法(Path Ranking Algorithm),PRA),以两个实体间的路径作为特征,来判断它们之间可能存在的关系
Algorithm
1. 特征抽取(生成并选择路径特征集合)
方法:随机游走,广度优先搜索,深度优先搜索
2. 特征计算(计算每个训练样例的特征值)
方法:随机游走概率,布尔值(出现/不出现),出现频次/概率
3. 分类器训练(根据训练样例,为每个目标关系训练一个分类器)
方法:单任务学习(为每个关系单独训练二分类器);多任务学习(不同关系联合学习)演绎推理
原始方法:直接通过一阶谓词逻辑进行推理
马尔科夫逻辑网
将概率图模型与一阶谓词逻辑结合,核心思想是为规则绑定权重(规则概率化),软化一阶谓词逻辑的硬约束.
形式化定义

马尔科夫逻辑网的优势:
- 当规则及其权重已知时:推断知识图谱中任意未知事实成立的概率(马尔可夫随机场的推断问题)证据变量为知识图谱中的已知事实,问题变量为未知事实
- 当规则已知但其权重未知时:自动学习每条规则的权重(马尔可夫随机场的参数学习)
- 当规则及其权重均未知时:自动学习规则及其权重(马尔可夫随机场的结构学习),属于上述归纳推理的范畴
概率软逻辑
马尔科夫逻辑网的进一步延伸,最大优点是允许原子事实(节点)的真值可以在连续的[0,1]区间取任意值(事实概率化),而不是像马尔科夫逻辑网取{0,1}离散值.
数值推理
基于表示学习
见《知识图谱(一)——知识表示》,通过将符号表示映射到向量空间进行数值表示,能够减少维数灾难问题,同时能够捕捉实体和关系之间的隐式关联,重点是可以直接计算且计算速度快.(Trans E,Trans R,Trans H)
基于张量分解
通过张量分解,将知识图谱表示成张量的形式,主要应用于链接预测(判断两个实体之间是否存在某种特定关系),实体分类(判断实体所属语义类别),实体解析(指代消解)
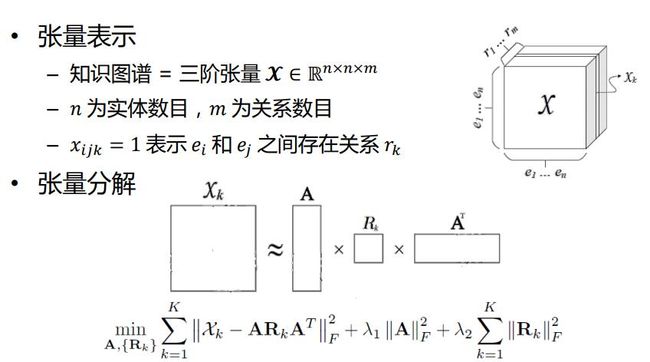
TRESCAL模型(解决输入张量高度稀疏所带来的过拟合问题)
面临挑战
- 大规模知识图谱中知识推理的可扩展性
- 大数据流处理中的推理效率(Flink、Spark 并行化流处理)
- 时空推理
- 自动或半自动的规则推理实现
资料来源:
[1]. 《第13章 知识图谱与知识推理》王泉
[2]. 《第10章 知识推理》王泉
[3]. 《知识图谱中推理技 术进展及应用》漆桂林

本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可。