《Hadoop 2.X HDFS源码剖析》读书笔记(DataNode)
1. Datanode逻辑结构
1.1 HDFS Federation
Federation的HDFS集群可以定义多个Namenode/Namespace,这些Namenode之间是互相独立的,它们各自分工管理着自己的命名空间。而Datanode则提供数据块的共享存储功能,每个Datanode都会向集群中所有Namenode注册,且周期性地向所有Namenode发送心跳和块汇报,然后执行Namenode通过响应发回的指令。
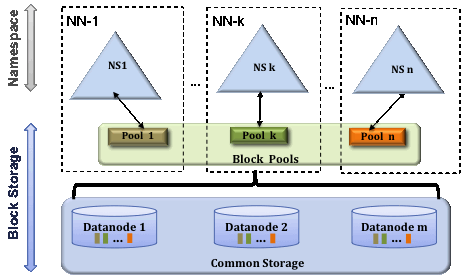
块池(BlockPool)
一个块池由属于同一个命名空间的所有数据块组成,这个块池中的数据块可以存储在集群中的所有Datanode上,而每个Datanode都可以存储集群中所有块池的数据块。
命名空间卷(NamespaceVolume)
一个Namenode管理的命名空间以及它对应的块池一起被称为命名空间卷,当一个Namenode/Namespace被删除后,对应的块池也会被删除。集群升级时,命名空间卷是基本的升级单元
1.2 Datanode逻辑结构

1.2.1 数据层
- 数据存储(DataStorage):负责管理与组织Datanode的磁盘存储空间,同时也负责管理存储空间的生命周期(包括升级、回滚、提交等操作)。BlockPoolSliceStorage类管理Datanode上单个块池的存储空间。DataStorage类会持有所有BlockPoolSliceStorage对象的引用,并通过这些引用管理所有块池。
- 文件系统数据集(FsDataset):抽象了Datanode管理数据块的所有操作,例如创建数据块文件、维护数据块文件和校验和文件的对应关系等。
1.2.2 逻辑层
- BlockPoolManager:管理所有块池的接口类。BlockPoolManager对象持有多个BPOfferService,每个BPOfferService对象都管理这个Datanode的一个块池。每个BPOfferService持有两个BPServiceActor对象,每个BPServiceActor对应HA机制中的一个Namenode,该对象负责向这个Namenode发送心跳、块汇报、缓存汇报以及增量快汇报,并执行Namenode返回的名字节点指令(DatanodeCommand)。
- DataBlockScanner:一个独立线程,周期性扫描每个数据块并检查数据块的校验和是否正常
- DirectoryScanner:独立线程,定时发起对磁盘数据块的扫描,对比内存中元数据与实际磁盘存储数据块的差异,然后更新内存中的元数据,使之与磁盘保存的数据块信息一致。
1.2.3 服务层
- HttpServer:对外提供HTTP服务,可用于展示Datanode内部状态。
- IPCServer:RPC服务端,响应来自于Client、Namenode以及其他Datanode的RPC请求。
- DataXceiverServer:数据传输服务端,响应来自Client以及其他Datanode的流式接口请求。
2. Datanode存储
2.1 升级机制
升级重点考虑以下几个问题:
- 兼容性:HDFS支持节点版本的向上升级,但不支持向下降版本。
- 回滚:HDFS回滚机制主要是通过备份旧版本数据实现的,回滚时将旧版本数据复制到原有目录中即可。HDFS仅保留前一版本数据,同时引入升级提交机制,当管理员提交了一次升级(hadoop dfsadmin -finalizeUpgrade)时,HDFS将会删除之前的版本,也就升级后无法回滚。
- 磁盘空间:使用了Linux硬链接的方式,把新旧版本的数据块文件的引用指向磁盘中的同一数据块,来节省空间。
2.1.1 升级
主要涉及以下目录:
- current:保存当前版本数据的目录。
- previous.tmp:在升级过程中,保存当前版本数据的目录。
- previous:升级后,保存上一版本数据的目录。
步骤:
- current改名为previous.tmp;
- 重建current目录;
- 建立current和previous.tmp中数据块文件和校验和文件之间的硬链接;
- previous.tmp改名为previous。
2.1.2 回滚
主要涉及的目录:
- previous:升级后,保存上一版本数据的目录。
- removed.tmp:在回滚过程中,保存当前版本数据的目录。
- current:回滚后,保存当前版本数据的目录。
步骤:
- current改名为removed.tmp;
- previous改名为current;
- 删除removed.tmp;
2.1.3 提交
主要涉及的目录:
- previous:升级后,保存上一版本数据的目录。
- finalized.tmp:在提交过程中,保存前一版本数据的目录。
步骤:
- previous改名为finalized.tmp;
- 删除finalized.tmp
2.2 磁盘存储结构
Datanode可以定义多个存储目录保存数据块。
<property>
<name>dfs.data.dirname>
<value>/dfs/data,/dfs/data2value>
property>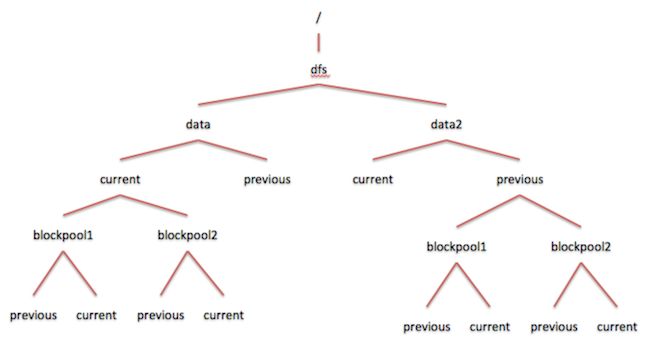
上图是当前Datanode的磁盘目录结构,无论是在存储目录中还是块池目录中都包含了current和previous文件夹。这种结构使得各个快照对应的Namenode可以独立升级(通过块池目录的升级文件夹),同时进行Datanode和Namenode的升级也可以,并且也支持Datanode级别的升级操作。
3. 文件系统数据集
Datanode最重要的功能之一管理与操作数据块功能(创建数据块文件、维护数据块文件与数据块校验文件的对应关系等)由FsDatasetImpl类实现。
Datanode可以配置多个存储目录保存数据块文件,所以Datanode将底层数据块的管理抽象为多个层次,并定义不同的类来实现。
- BlockPoolSlice:管理一个指定块池在一个指定存储目录下的所有数据块。
- FsVolumeImpl:管理Datanode一个存储目录下的所有数据块。
- FsVolumeList:Datanode可以定义多个存储目录,FsVolumeList保存Datanode上所有的FsVolumeImpl对象。
4. BlockPoolManager
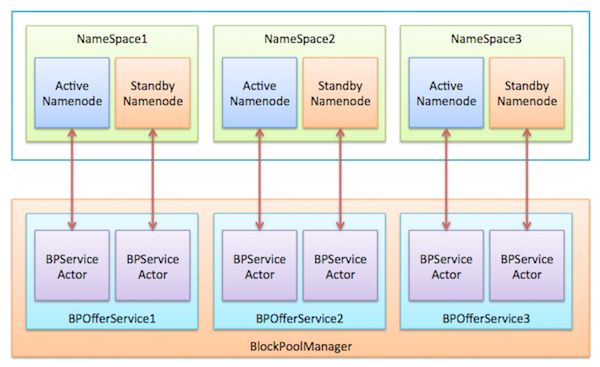
4.1 BPServiceActor
每个BPServiceActor的实例都是一个独立线程,主要实现以下功能:
- 与Namenode进行第一次握手,获取命名空间的信息;
- 向Namenode注册当前Datanode;
- 定期向Namenode发送心跳、增量块汇报、全量快汇报以及缓存块汇报;
- 执行Namenode传回的名字节点指令。
4.2 BPOfferService
每一个命名空间在Datanode上都有一个对应的块池存储这个命名空间的数据块,这个块池是由一个BPOfferService实例管理。同时BPOfferService类还需要管理当前Datanode认为是Active状态的Namenode的引用(通过bpServiceToActive字段)。
4.3 BlockPoolManager
负责管理所有BPOfferService实例,对外提供添加、删除、启动、停止、关闭BPOfferService类的接口。
5. 流式接口
5.1 DataTransferProtocol
用来描述写入与读出Datanode上数据的流式接口。
5.2 Sender和Receiver
Sender类封装了DataTransferProtocol的调用操作,用于发起流式接口请求;Receiver类封装了DataTransferProtocol的执行操作,用于响应流式接口请求。
5.3 DataXceiverServer

DataXceiverServer对象用于在Datanode上监听并接收流式接口请求,每当有Client通过Sender类发起流式接口请求时,DataXceiverServer就会监听并接收这个请求,然后创建一个DataXceiver对象用于响应这个请求并执行对应的操作。
6. 数据块扫描器
每个Datanode都会初始化一个数据块扫描器周期性地验证Datanode上存储的所有数据块的正确性,并把发现的损坏数据块报告给Namenode。DataBlockScanner类就是Datanode上数据块扫描器的实现。由于Datanode会保存多个块池的数据块,所以DataBlockScanner会持有多个BlockPoolSliceScanner对象,每个BlockPoolSliceScanner对象都负责验证一个指定块池下数据的正确性。
7. DirectoryScanner
主要任务是定期扫描磁盘上的数据块,检查磁盘上的数据块信息是否与FsDatasetImpl中保存的数据块信息一致,如果不一致则对FsDatasetImpl中的信息进行更新。只会检查内存和磁盘上FINALIZED状态的数据库是否一致。
8. DataNode类的实现
8.1 Datanode的启动
DataNode启动流程入口是main()方法,然后调用secureMain()方法,secureMain()方法通过调用createDataNode()创建并启动一个DataNode实例,然后在这个DataNode实例上调用join()方法等待DataNode停止运行。
8.2 Datanode的关闭
shutdown()方法用于关闭DataNode实例的运行:
- 首先将DataNode.shouldRun字段设置为false,这样所有的BPServiceActor线程、DataXceiverServer线程、PacketResponder以及DataBlockScanner线程就会自动退出运行。
- 如果这个关闭操作是用于重启,且当前Datanode正处于写数据流管道中,则向上游数据节点发送OOB消息通知客户端,之后调用DataXceiverServer.kill()方法强制关闭流式接口底层的套接字连接。
- 接下来shutdown()方法会关闭DataBlockScanner以及DirectoryScanner,关闭WebServer,然后在DataXceiverServer对象上调用join方法,等待DataXceiverServer线程成功退出。
- 最后依次关闭IPCServer、BlockPoolManager对象、DataStorage对象以及FSDatasetImpl对象。
- shutdown()方法运行结束后,secureMain()方法的join()调用返回,然后执行finally语句,结束数据节点的运行并退出。