使用Requests库和BeautifulSoup库来爬取网页上需要的文字与图片
Pythone现在已经成为全球最火爆的语言了,它的强大之处想必不需要我多说吧。接下来我就Python网络爬虫来谈一谈本渣渣的见解。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(以上都是废话,下面开始进入正题)
以下内容基于Python3
网络爬虫根据爬取的工作量可以分成页面级的网络爬虫与网站级的网络爬虫,两种差别解决的方法也不相同,下面是爬虫的基本思路:
一.页面级的网络爬虫
1.requests 库获得一个请求回应2.BeautifulSoup 库解析html文件
3.对解析的soup进行查找:
(1)RE正则表达式
(2)find_all(“xx”)定位标签内容
4.对爬取的内容进行操作(字符串的加减)
二.网站级的页面爬虫
scrapy框架
(一)首先安装Python3,具体流程xx
Python官网
(二)在CMD界面下 使用pip 命令下载Requests库与BeautifulSoup库
pip install requests
pip install beautifulsoup4
完成后Requests库与BeautifulSoup库就下载完成啦!!
下面来两个小实例:
一.标签查找类爬虫(简单实例) (eg:http://news.sina.com.cn/photo/rel/csjsy07/399/)
爬取淮安日报图片精选的图片

用浏览器打开该网页,右击查看该网页的源码;
形如如下图的html代码形式:会发现图片的源地址在标签内,于是我们只要定位到这个标签取出地址就可以了。

思路如下:
首先导入requests库向网页发送请求接收请求回应。
然后抛出异常,判断网页是否成功接收到请求
其次判断编码类型,修改编码
再次生成一个Soup,将html文件进行解释
最后查找标签,获取内容并且对内容进行一系列操作
代码如下:
import requests
from bs4 import BeautifulSoup
import urllib
r=requests.get("http://news.sina.com.cn/photo/rel/csjsy07/399/")
r.encoding=r.apparent_encoding
text=r.text
soup=BeautifulSoup(text,"html.parser")
a=soup.find_all('img',{'class':'b1'})
for i in a:
print(i['src'])

没错就是这么简单。
二.正则表达式类爬虫(简单实例) (eg:https://s.taobao.com/search?q=iphone)
目标:爬取淘宝搜索iPhone的标题与价格

形如如下图的html代码形式,内容是以键值对的方式进行存放的(raw_title:xxxxxxx)不像上面的标签内取值,于是我们就用到了正则表达式。
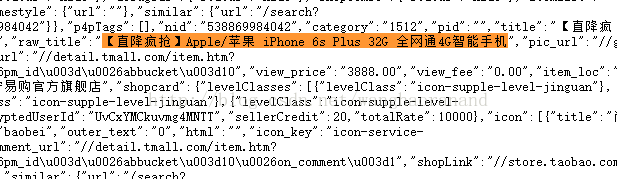
思路如下:
首先导入requests库向网页发送请求接收请求回应。
然后导入RE库
其次抛出异常,判断网页是否成功接收到请求
再次判断编码类型,修改编码
最后用正则表达式获取内容并且对内容进行一系列操作
代码如下:
import requests
import re
from bs4 import BeautifulSoup
r=requests.get("https://s.taobao.com/search?q=iphone")
html=r.text
j=1
title =re.findall(r'\"raw_title\"\:\".*?\"', html)
price= re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
for i in range(len(price)):
print("标题为:{:50};价格为:{}".format(eval(title[i].split(':')[1]),eval(price[i].split(':')[1])))
运行结果如图:到最后其实就是简单的字符串加减等运算

拓展延伸:
实现多页面的爬虫只需要改变url的地址就好了,比如页面 往往都是在url中含有page=x的字段,运用字符串的加法能够很容易的实现多页面的爬取。
查找比较复杂的内容时,可以结合正则表达式和find_all函数来进行深层次筛选。
对于一些网站防止爬虫,只需要在获得的request的头添加上想伪装的浏览器的内核,如有时间限制,也可以模拟出时间,道高一尺魔高一丈。