关于前程无忧以‘数据分析’为关键词的招聘信息的数据分析
背景:作为个数据分析小菜鸟,深知知行合一的重要性。基于本人目前要在杭州寻找一份数据分析的初阶工作的现实考量,故决定采用前程无忧上关键词‘数据分析’和地点设置在杭州上的招聘信息作为此次数据分析的数据来源来进行实操,同时也为了能让自己更好的了解目前杭州关于数据分析岗位的招聘市场以及岗位的成长性作一个简单的前瞻和展望。
方法:首先通过爬虫的request和BeatifulSoup库来进行所需数据的抓取(此次主要借鉴网上的源代码进行适当修改爬取杭州的数据)。然后爬取的数据进行适当的清洗和整理,进行可视化和分析操作,主要用到numpy,pandas以及matpotlib和wordcloud等python库。最后对所获的图表进行合理的分析和适当的展望。此次分析采集数据时间为8月6日,样本数为2372.
具体代码实现:
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #首先还是我们的老三样
df = pd.read_csv(r'/Users/herenyi/Downloads/前程无忧招聘信息.csv', encoding = 'UTF-8') #读取文件
df.info() #快速浏览文件
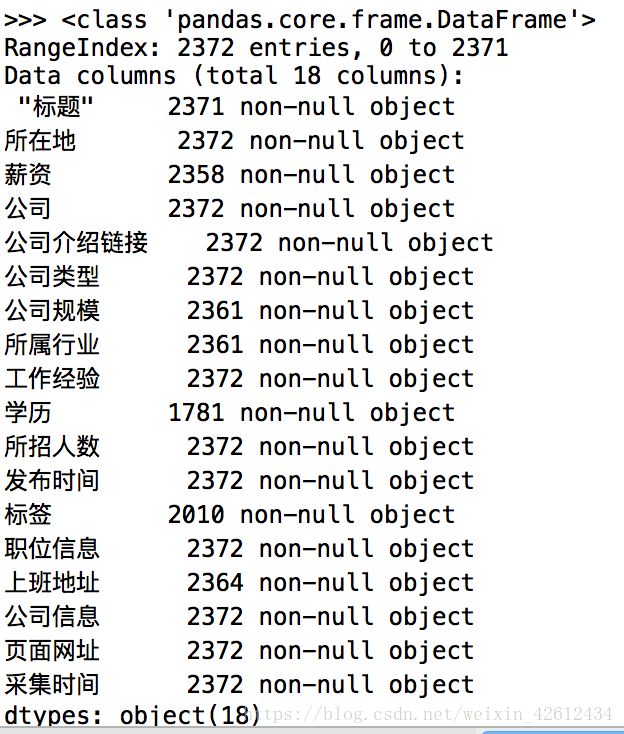
这就是大致数据全览,数据类型各项标签都为字符串格式。不过这里要提醒下,自己把列名换成英文比较好,不然等下引用列可能会出现不必要的麻烦。接下来就是选取我们想要的列,以及数据是否有重复值和缺失值了,我们继续下一步。
df_norepeat = df.drop_duplicates(subset =[ '公司'], keep = 'first' )
df_norepeat.info() #我们通过drop_duplicates函数去除重复值,并且新建一列以便后面操作。并用info函数加以个数确认。

接下来我们处理缺失值,本次报告我们需要的主要数据方面的就是工资这列,所以我们需要处理工资这列的缺失值。而工资这列只有2325个值,相对于公司数字2338来说,是有缺失的,我们去掉没有工资记录的行。
df_clean = df_norepeat.dropna(subset = ['薪资']) #去掉没有工资的空值,并传递到df_clean中。
df_clean.info()

这时候每个工资和公司都一一标定了,很舒服了。接下来我们要进行薪资里的字符串进行处理,这也是最复杂的部分,因为里面有各种格式。
df_clean[‘薪资’] # 让我们来看看薪资的构成。

我们可以看到,单位有以千/月,万/月,万/年主要这三种格式,我们需要把他们全部转化为。由于还不怎么熟悉正则表达,我们可以尝试分割-来分隔最高和最低工资,以及如何区分单位的差别,我们需要定义个函数。
def cut_word(word, method): #传入两个参数,一个是数据集,一个是方法
position1 = word.find('年')
position2 = word.find('万')
position3 = word.find('-') #定位到三个地方
if position1 != -1:
bottom = float(word[:position3]) * 10 / 12
top = float(word[position3 + 1:position2]) * 10 / 12 #首先如果找得到年,那单位即为为万/年,此时的最低和最高薪水就可以转化单位了。
elif position2 != -1 & position1 == -1:
bottom = float(word[:position3]) * 10
top = float(word[position3 + 1:position2]) * 10 #如果找不到年且找得到万,那单位即为万/月,计算最低最高薪水。
else:
bottom = float(word[:position3])
top = float(word[position3 + 1:position3 + 2]) #接下来就是千/月了,常规处理。
if method == 'bottom':
return bottom
else:
return top
df_clean['topsalary']= df_clean.薪资.apply(cut_word, method = 'top')
df_clean['bottomsalary']= df_clean.薪资.apply(cut_word, method = 'bottom') #求出最高和最低工资

然后我们发现这么一个错误,貌似我们看到的前二十项里面不包含这样的格式,从截取的片段来看260元应该是个实习生之类的日结岗位,我们需要再优化下我们的函数来删除这些不规范的数据。
def cut_word(word, method): #传入两个参数,一个是数据集,一个是方法
position1 = word.find('年')
position2 = word.find('万')
position3 = word.find('-')
position4 = word.find('千')
if position1 != -1:
bottom = float(word[:position3]) * 10 / 12
top = float(word[position3 + 1:position2]) * 10 / 12 #首先如果找得到年,那单位即为为万/年,此时的最低和最高薪水就可以转化单位了。
elif position2 != -1 & position1 == -1:
bottom = float(word[:position3]) * 10
top = float(word[position3 + 1:position2]) * 10 #如果找不到年且找得到万,那单位即为万/月,计算最低最高薪水。
elif position4 != -1:
bottom = float(word[:position3])
top = float(word[position3 + 1:position3 + 2]) #接下来就是千/月了,常规处理。
else:
import numpy as np
bottom = np.nan
top = np.nan #**我们想把不符合的数据全变为空值,以便后面删除这些行**
if method == 'bottom':
return bottom
else:
return top

然后神奇的又来了,居然还有2万以下/年的字符段,这就是不会正则精确匹配的坏处,但是土归土,我们这样查找字段也还是能解决的。我们再加个查找就好了。
def cut_word(word, method): #传入两个参数,一个是数据集,一个是方法
position1 = word.find('年')
position2 = word.find('万')
position3 = word.find('-')
position4 = word.find('千')
position5 = word.find('以') #定位到五个地方
if position1 != -1 & position5 == -1:
bottom = float(word[:position3]) * 10 / 12
top = float(word[position3 + 1:position2]) * 10 / 12 #首先如果找得到年,且找不到以下字段,那单位即为为万/年,此时的最低和最高薪水就可以转化单位了。
elif position2 != -1 & position1 == -1:
bottom = float(word[:position3]) * 10
top = float(word[position3 + 1:position2]) * 10 #如果找不到年且找得到万,那单位即为万/月,计算最低最高薪水。
elif position4 != -1:
bottom = float(word[:position3])
top = float(word[position3 + 1:position3 + 2]) #接下来就是千/月了,常规处理。
else:
import numpy as np
bottom = np.nan
top = np.nan #**我们想把不符合的数据全变为空值,以便后面删除这些行**
if method == 'bottom':
return bottom
else:
return top

居然还有10万以上/月的数据,我真是***了,所以说处理脏数据这块是真心最烦的。我觉得要精确匹配,不然接下来鬼知道还有什么奇奇怪怪的数据在。
def cut_word(word, method): #传入两个参数,一个是数据集,一个是方法
position1 = word.find('万/年')
position2 = word.find('万/月')
position3 = word.find('-')
position4 = word.find('千/月')
if position1 != -1 :
bottom = float(word[:position3]) * 10 / 12
top = float(word[position3 + 1:position1]) * 10 / 12
elif position2 != -1:
bottom = float(word[:position3]) * 10
top = float(word[position3 + 1:position2]) * 10
elif position4 != -1:
bottom = float(word[:position3])
top = float(word[position3 + 1:position4])
else:
import numpy as np
bottom = np.nan
top = np.nan
if method == 'bottom':
return bottom
else:
return top
df_clean['topsalary']= df_clean.薪资.apply(cut_word, method = 'top')
df_clean['bottomsalary']= df_clean.薪资.apply(cut_word, method = 'bottom')
df_clean = df_clean.dropna(subset = ['topsalary']) #删除我们之前的空值行
终于处理好这些数据了,也没运行bug。继续下一步,这里引入新的知识点,匿名函数lambda。很多时候我们并不需要复杂地使用def定义函数,而用lamdba作为一次性函数。lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。
df_clean[‘avgsalary’] = df_clean.apply(lambda x: (x.topsalary+x.bottomsalary)/2, axis = 1)
df_clean = df_clean.rename(columns={'所在地':'location', '公司类型':'type', '工作经验':'exp', '学历':'education', '公司规模': 'scale'}) #不想再不断切换输入法了,把列名替换下。
df_need = df_clean [['location', 'type', 'exp', 'education', 'scale', 'avgsalary']] #筛选出所需的列。
df_need.head() #至此数据部分清理基本结束,接下来进行可视化操作。
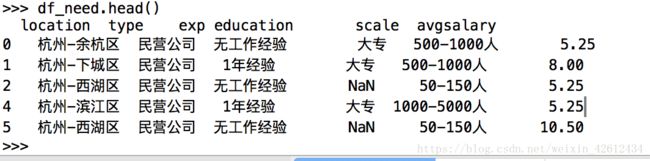
现在的数据就很清爽整洁了。
df_need.location.value_counts() #对字符串用value_counts方法去分类。
df_need.avgsalary.describe() #对数值列我们用describe方法看下大概。
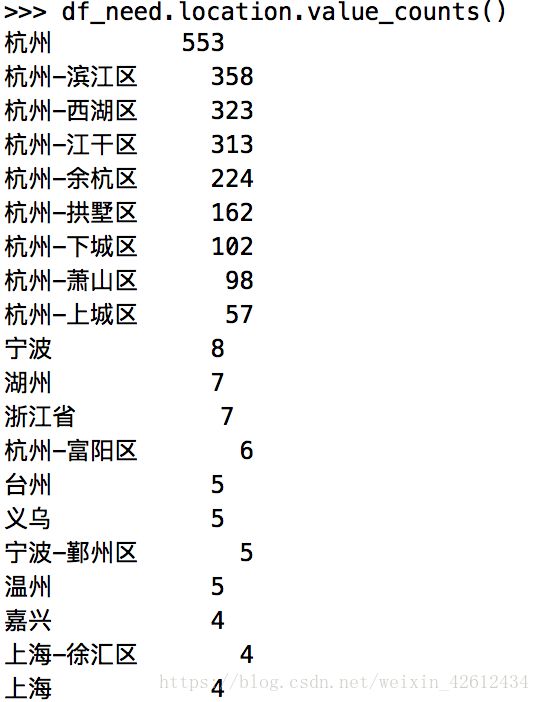
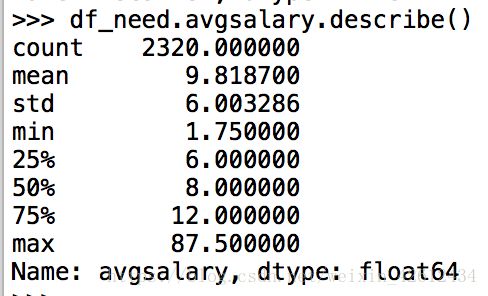
貌似还有很多异地招聘,为了更加准确的获得杭州市场的数据,我们决定删除异地的数据。接下来开始画图。好激动有木有!可以参考本人的matplotlib实战来照葫芦画瓢。
location = ['杭州',
'杭州-滨江区',
'杭州-西湖区',
'杭州-江干区',
'杭州-余杭区',
'杭州-拱墅区',
'杭州-下城区',
'杭州-萧山区',
'杭州-上城区']
df_need = df_need.loc[df_clean['location'].isin(location)] #我们又一步精简数据到只剩杭州地区。
plt.style.use('ggplot') #使用ggplot配色,可以使图片美观,当然还有很多其他风格,大家自行百度
fig, ax = plt.subplots()
ax.hist(df_need['avgsalary'], bins = 20) #分成15组
ax.set_xlim(0, 40) #把x轴刻度缩小点
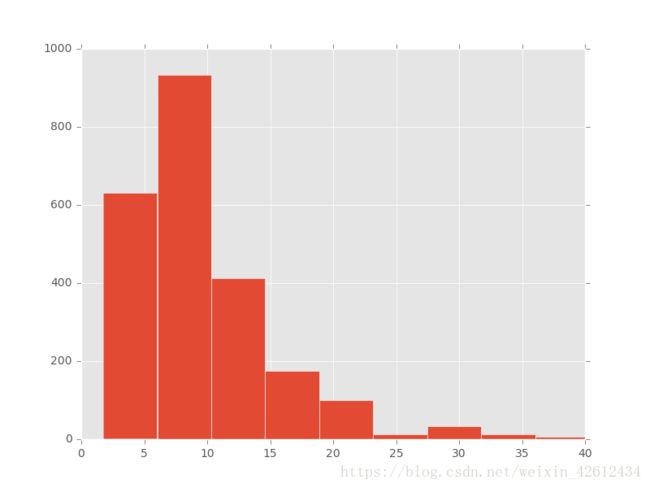
数据大体呈现个单峰状,其中大部分聚集在5k到10k区间,越往后逐渐下降,基本符合现实。接下来我们进行分组,进行细分分析。首先是单因素条件下的分析。
ax = df_need.boxplot(column = 'avgsalary', by = 'location', figsize = (9,7))
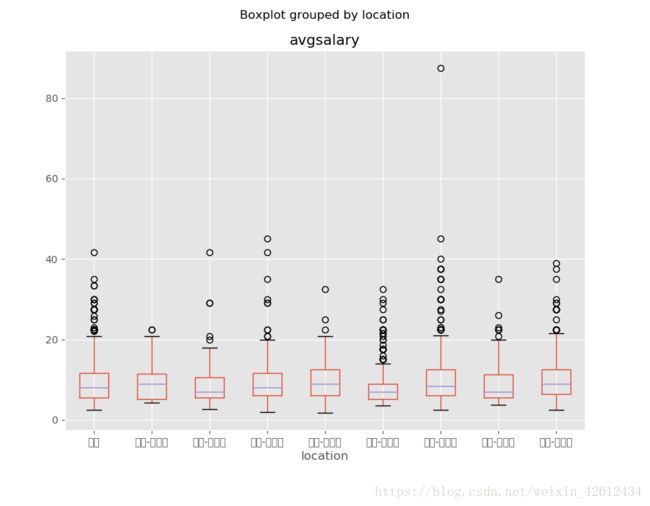
这时候我们发现x轴刻度标签显示错误了,这时候需要我们导入中文字体。网上的方法有很多,这里我们采用用FontProperties方法。
#导入中文,我电脑里面随便找了个ttf文件,貌似是堡垒之夜里面自带的中文字体,哈哈。
from matplotlib.font_manager import FontProperties
chinese = FontProperties(fname = r'/Users/Shared/Epic Games/Fortnite/Engine/Content/Slate/Fonts/DroidSansFallback.ttf')
ax = df_need.boxplot(column = 'avgsalary', by = 'location', figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(chinese)
ax.set_ylim(0,50)
ax.set_xlabel('区域', fontproperties=chinese)
ax.set_ylabel('平均工资(千/月)', fontproperties=chinese)
ax.set_title('不同行政区域之间平均工资的箱体图', fontproperties=chinese)

具体的图表分析请参见结尾的PDF报告,这边主要介绍代码实现,以下同理。
ax = df_need.boxplot(column = 'avgsalary', by = 'exp', figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(chinese)
ax.set_ylim(0,50)
ax.set_xlabel('工作经验', fontproperties=chinese)
ax.set_ylabel('平均工资(千/月)', fontproperties=chinese)
ax.set_title('不同工作经验之间平均工资的箱体图', fontproperties=chinese)

以及之后的公司规模,学历背景以及企业性质对平均工资的影响,就直接放图了。
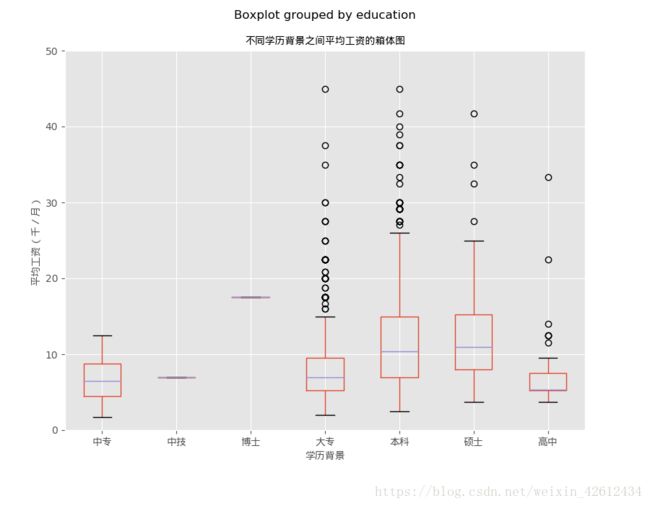
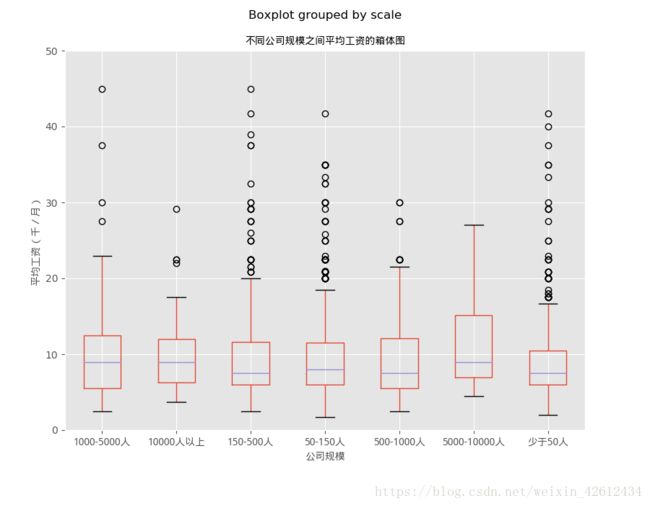

上面就是单因素分析的过程了,接下来我们想多因素角度下分析对平均薪资的影响。主要用到groupby。
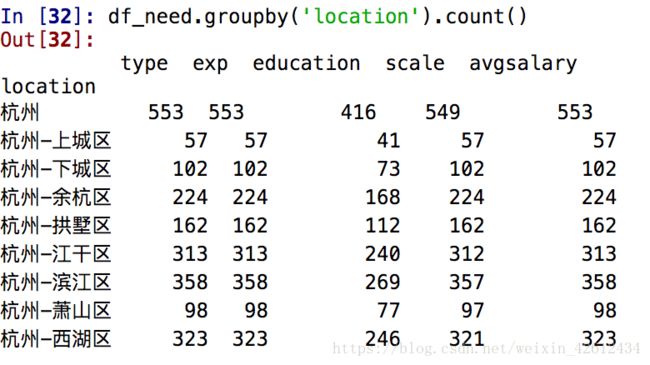
df_need.groupby('location').count() #等价于之前的value.counts(),不过这是全列在按区域分组的数据
df_need.groupby(['location','education']).mean()
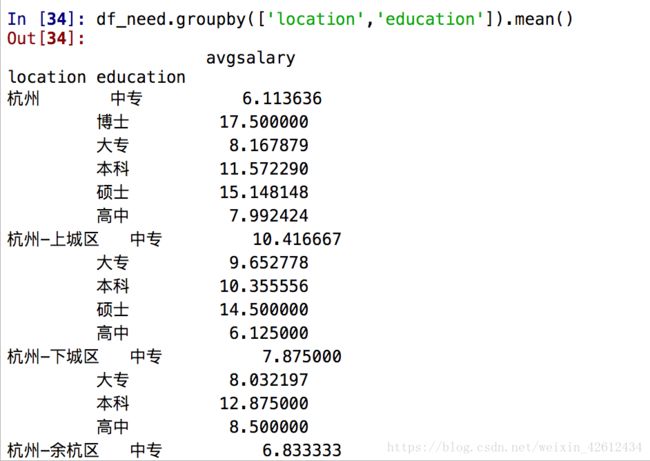
我们看到当在groupby里传入一个列表示,得到一组层次化的Series,这时候已经有初步的多因素分析基础了,我们以此可以进行数据可视化操作。
ax = df_need.groupby('location').mean().plot.bar(figsize = (9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(chinese)
label.set_rotation(30)
ax.set_xlabel('区域', fontproperties=chinese)
ax.set_ylabel('平均工资(千/月)', fontproperties=chinese)
ax.set_title('不同行政区域之间平均工资的条形图', fontproperties=chinese)

ax = df_need.groupby(['education', 'exp']).avgsalary.mean().unstack().plot.bar(figsize = (14,6))
for lable in ax.get_xticklabels():
lable.set_fontproperties(chinese)
lable.set_rotation(360)
ax.legend(prop=chinese)
ax.set_xlabel('学历', fontproperties=chinese)
ax.set_ylabel('平均工资(千/月)', fontproperties=chinese)
ax.set_title(u'不同教育背景下平均工资与工作经验的关系', fontproperties=chinese)

这是多因素下的条形图,这边就举个例子,大家可以把groupby中的参数调换下,形成新的因素分析。这里自己有个一直困惑的小知识点,可能会影响图形选择,我这里夹带点私货,就是条形图和直方图的区别,貌似网上是这样说的(条形图主要用于展示分类数据,而直方图则主要用于展示数据型数据)。我们接下来用下直方图来展示下数据型数据,也就是我们这里的平均工资这列。
fig, ax = plt.subplots()
ax.hist(x = df_need[df_need.education == '本科'].avgsalary, bins = 20, normed = 1,
facecolor = 'blue', alpha = 0.5, range=(0, 40))
ax.hist(x = df_need[df_need.education == '大专'].avgsalary, bins = 20, normed = 1,
facecolor = 'red', alpha = 0.5, range=(0, 40)) #alpha为透明度,normed=1表示显示百分比。
ax.legend(['本科', '大专'], prop=chinese) #修改图例名称
ax.set_xlabel('平均工资(千/月)', fontproperties=chinese)
ax.set_title('本科与大专之间各平均工资段百分比人数', fontproperties=chinese)
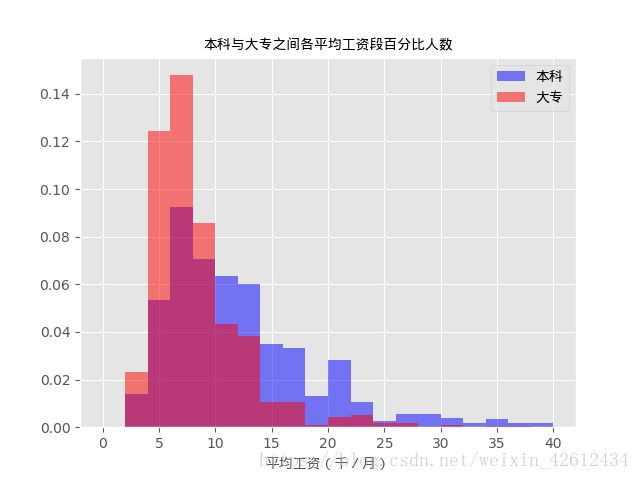
通过直方图,我们可以很清晰的看到本科与大专间的各薪资段百分人数。说明直方图适合显示数据型数据,比箱线图更加清晰明了。最后我想用分桶的方法划分薪资来看下各行政区内的薪资段百分比。
bins = [0, 5, 10, 20, 100]
df_need['level'] = pd.cut(df_need['avgsalary'], bins=bins) #我们以此分组为初,中,高,顶级数据分析师。

bins = [0, 5, 10, 20, 100]
df_need['level'] = pd.cut(df_need['avgsalary'], bins=bins) #我们以此分组为初,中,高,顶级数据分析师。
df_level = df_need.groupby(['location', 'level']).avgsalary.count().unstack()
df_level_percent = df_level.apply(lambda x: x/x.sum(), axis = 1)
ax = df_level_percent.plot.bar(stacked = True, figsize = (14,6))
for label in ax.get_xticklabels():
label.set_fontproperties(chinese)
label.set_rotation(30)
legends = ['0-5k','5k-10k','10k-20k','30k-100k']
ax.legend(legends, loc = 'upper right')
ax.set_xlabel('行政区', fontproperties=chinese)
ax.set_title('不同行政区内各薪资段百分比组成', fontproperties=chinese)
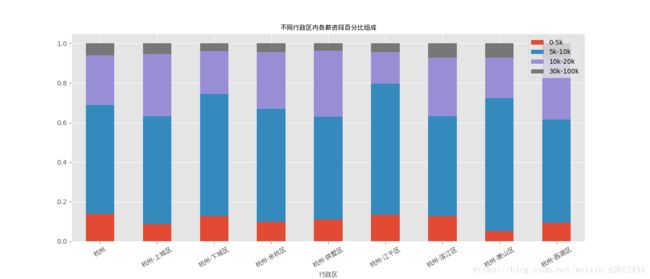
大家可以自己换换参数试一下,可能会发现其他有趣的结论哦。接下来我们就做一下关键字词云吧,看看这些企业到底有什么福利!
df_clean['labels'] = df_clean.标签 #先把列名改为英文
df_clean['labels']

word = df_clean.labels.str.split('|')
df_word = word.dropna().apply(pd.value_counts)
clean_word = df_word.unstack().dropna().reset_index()
把数据格式处理成这样,在进行词云操作。
from wordcloud import WordCloud
df_word_counts = clean_word.groupby('level_0').count()
df_word_counts.index = df_word_counts.index.str.replace("'", "")
wordcloud = WordCloud(font_path=r'/Users/Shared/Epic Games/Fortnite/Engine/Content/Slate/Fonts/DroidSansFallback.ttf',
width=900, height=400, background_color='white')
f, axs = plt.subplots(figsize=(15, 15))
wordcloud.fit_words(df_word_counts.level_1)
axs = plt.imshow(wordcloud)
plt.axis('off')

这次实战主要侧重一般的数据清理,以及多维和可视化的建立,通过此次项目大概基本代码都过了一遍,并且提升了自身解决问题能力。关于图表的分析请参见链接: https://pan.baidu.com/s/1hpjkO2_HwwlJt2utMf2ANw 提取码: ihg6。由于是个人第一个项目,图表的分析还很稚嫩,主要关注点还是在实战上,分析的话要结合更多的数理知识比如各因素的比重距离算出来显得更加专业点,后续慢慢完善。