LeetCode小白入门——简单题目八题合集,每题两解
本文共包括八个题目,来源于LeetCode简单难度,每个问题会给出两种解法,第一种偏暴力、易理解一些,第二种会更加高效一些,尽可能会避免利用Python的内置函数,便于真正理解算法原理。
来源:LeetCode(力扣)
链接:https://leetcode-cn.com/problemset/all/?difficulty=%E7%AE%80%E5%8D%95
1.两数之和
题目描述:给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:给定 nums = [2, 7, 11, 15], target = 9。因为 nums[0] + nums[1] = 2 + 7 = 9,所以返回 [0, 1]。
这道题的总体上思路是num[i]一定位于数组中,所以只要找出target-num[i]在数组中的位置即可。
第一种方法是遍历数组,但每一次循环都会利用切片将i之前的元素转化成一个新的数组,这样做是为了应对数组中出现类似于[2,3,3,5]相邻数字相等的状况。如果找到了符合的值就赋给j,由于j总是位于i之前,所以返回[j,i]。
def twoSum(nums, target):
j = -1
for i in range(1,len(nums)):
new_nums = nums[:i]
if target-nums[i] in new_nums:
j = new_nums.index(target-nums[i])
break
if j>=0:
return [j,i]
第二种方法是利用哈希表,首先初始化一个空字典,遍历数组,如果target-num[i]在字典中,就返回该值的索引和i;如果未出现在字典中,就将该值作为key,该索引作为value传入字典中,等下次循环再判断。
def twoSum(nums, target):
dict_ = {}
for i in range(len(nums)):
if target-nums[i] in dict_:
return [dict_[target-nums[i]],i]
else:
dict_[nums[i]] = i
- 方法一用时548ms,内存消耗14.8MB
- 方法二用时68ms,内存消耗14.9MB
7.整数反转
题目描述:题目描述给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
示例:输入: 123输出: 32、输入: -123输出: -321、输入: 120输出: 21
注意:假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
第一种方法是利用字符串,首先对字符串反转,这一步可以利用切片或者内置函数reverse。如果输入数字 x ≥ 0 x\geq0 x≥0,直接将反转后的字符串转为整型赋值给num;如果 x < 0 x<0 x<0,需要先在字符串前加上"-"再转为整型赋值给num。若num处于范围之内直接返回,否则返回0。
def reverse(x):
str1 = str(abs(x))
str2 = str1[::-1]
if x>=0:
num = int(str2)
else:
str3 = '-'+str2
num = int(str3)
if num < (-2) ** 31 or num > 2 ** 31 - 1:
return 0
else:
return num
第二种方法是利用数学方法,利用整数除以10取余可以得到该整数的最后一位、整数地板除可以去除该整数的最后一位两个性质相结合就可以得到反转后的数字,之后的判断与上述方法同理。
def reverse(x):
temp = abs(x)
i = len(str(temp))
num = 0
while i>0:
num = num * 10 + temp % 10
temp = temp // 10
i -= 1
if x<0:
num = -num
if num<(-2)**31 or num>2**31-1:
return 0
else:
return num
- 方法一用时52ms,内存消耗13.7MB
- 方法二用时52ms,内存消耗13.4MB
13. 罗马数字转整数
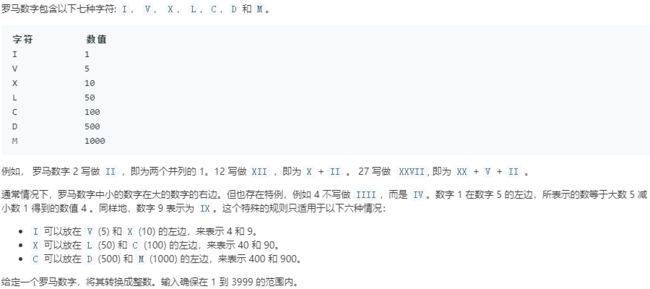
示例:输入: "III"输出: 3、输入: "IV"输出: 4、输入: "MCMXCIV"输出: 1994(解释: M = 1000, CM = 900, XC = 90, IV = 4)。
第一种方法是利用字典(哈希表)暴力破解,将所有可能出现的组合按照罗马数字作为key、阿拉伯数字作为value的格式存入字典中,对于输入的字符串,如果一个字符对应值小于其右边的值,那么这个组合必定是IV、IX、XL、XC、CD、CM其中一个。
那么就可以利用切片在字符串中截取两位,在字典中查询这个组合的对应值,并且下标也需后移两位;否则只需在字典中查询该字符对应值,下标后移一位即可。
def romanToInt(self, s: str) -> int:
dict_ = {"I": 1, "IV":4,"V": 5,"IX":9, "X": 10, "XL":40,"L": 50,
"XC":90,"C": 100,"CD":400,"D": 500, "CM":900,"M": 1000}
sum = 0
i = 0
while i< len(s) - 1:
if dict_[s[i]] < dict_[s[i + 1]]:
sum += dict_[s[i:i + 2]]
i += 2
else:
sum += dict_[s[i]]
i += 1
if i >= len(s):
return sum
else:
return sum + dict_[s[-1]]
最后为什么又会增加一个判断呢?是因为i的范围是(0,len(s)-1),所以最后需要查询的可能是一个组合,也可能是单个字符,需要区分这两种可能性。
第二种方法也是利用哈希表,这种方法也是遍历整个字符串,如果一个字符小于它右边的字符,那么在和的基础上减去这个字符对应值,比如IV不就是-1+5=4嘛;否则就直接在和的基础上加上该字符对应值即可,由于每次只判断一个字符,所以也无需对结果进行上面的区分。
def romanToInt(self, s: str) -> int:
dict_ = {"I":1,"V":5,"X":10,"L":50,"C":100,"D":500,"M":1000}
sum = 0
for i in range(len(s)-1):
if dict_[s[i]]<dict_[s[i+1]]:
sum -= dict_[s[i]]
else:
sum += dict_[s[i]]
return sum + dict_[s[-1]]
- 方法一用时76ms,内存消耗13.6MB
- 方法二用时64ms,内存消耗13.7MB
14. 最长公共前缀
题目描述:编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 “”。
示例:输入: [“flower”,“flow”,“flight”]输出: “fl”、输入: [“dog”,“racecar”,“car”]输出: “”。
前缀是指字符串最后一个字符之前所有字符
第一种方法是利用两层循环嵌套,因为公共前缀的长度一定是小于等于数组中最短字符长度的,所以第一层循环用来切分字符串,利用第一个字符串str0与其余字符串做比较,如果str0更长,则其切分后的长度需要与其相比较的字符串相等。
第二层循环是在str0长度范围内,依次比较str0和其他字符串每个对应位置上的字符是否相等,如果不相等则更新str0并利用break退出该层循环,再比较下一个字符串。
def longestCommonPrefix(strs):
if len(strs) == 0:
return ""
str0 = strs[0]
for i in strs:
if len(str0) > len(i):
str0 = str0[:len(i)]
for j in range(len(str0)):
if str0[j] != i[j]:
str0 = str0[:j]
break
return str0
第二种方法利用了zip和set两个方法相结合,下面结合程序一些断点运行截图进行讲解。
def longestCommonPrefix(strs):
words = list(zip(*strs))
str_ = ''
for i in words:
word = list(set(i))
if len(word) == 1:
str_ += word[0]
else:
break
return str_

可以看到zip(*strs)会将每个字符串相应位置上的字符存入一个元组中,元祖的个数就是输入中字符串最小长度。然后遍历words这个列表,对每个元祖利用set方法去重,如果去重后得到新列表的长度为1,那么证明这个字符是三者共有的,就可以将其加入到定义的空字符串str_中;否则就跳出循环返回字符串str_。
- 方法一用时48ms,内存消耗13.6MB
- 方法二用时36ms,内存消耗13.7MB
20.有效的括号
题目描述:给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。有效字符串需满足:左括号必须用相同类型的右括号闭合;左括号必须以正确的顺序闭合。注意空字符串可被认为是有效字符串。
示例:输入: "()[]{}"输出: true、输入: "(]"输出: false、输入: "([)]"输出: false、输入: "{[]}"输出: true。
第一种方法利用了内置方法replace,根据示例可以看到每组括号都需要左右括号对应才能消除,只要字符串中含有可以消除的括号,就可以将其替换成空字符串,利用循环无脑替换,最后字符串如果为空就返回True,反之则返回False。
def isValid(s):
if len(s)%2 != 0:
return False
while '()' in s or '[]' in s or '{}'in s:
s = s.replace('()','').replace('[]','').replace('{}','')
return s==''
第二种方法利用栈的思想,首先按照右括号为key,左括号为value的格式传入字典中,然后遍历整个字符串,如果是左括号就存入栈中,然后如果是右括号则比较其对应的左括号是否与栈顶位置的左括号相同,相同的话从栈中移除,不同的话就将其存入栈中,循环过后的栈如果和最初的栈相同返回True,反之则返回False。
这里需要注意的是在新定义栈时,需要向其中加入一个元素,防止在比较的时候列表下标溢出的现象发生。
def isValid(s):
if s == '':
return True
dict = {')':'(',']':'[','}':'{'}
stack = [0]
for i in s:
if i in ['(','[','{']:
stack.append(i)
elif dict[i] == stack[-1]:
stack.pop()
else:
stack.append(i)
return stack == [0]
- 方法一用时56ms,内存消耗13.7MB
- 方法二用时44ms,内存消耗13.7MB
26. 删除排序数组中的重复项
题目描述:给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例:给定 nums = [0,0,1,1,1,2,2,3,3,4],函数应该返回新的长度5,并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4,不需要考虑数组中超出新长度后面的元素。
在编写程序的时候一定要注意题目中两个关键的要求,一个是不要使用额外的空间,所以这里不能定义新的数组;另一个是不需要考虑数组中超出新长度后面的元素,在需要满足示例中的要求的基础上可以选择删除、覆盖、交换多种方式。
第一种方法利用双指针,分别初始化为0和1,遍历输入数组,如果两个指针对应元素值相等,则移除后面指针对应元素;否则就将两个指针分别加一,继续排查数组中剩下的元素。
def removeDuplicates(nums):
market1,market2 = 0, 1
while market2<len(nums):
if nums[market1]==nums[market2]:
nums.pop(market2)
else:
market1 += 1
market2 += 1
return len(nums)
第二种方法是将数组自后向前遍历,如果从前向后遍历的话,每当删除一个元素时,它后面所有元素的下标都会变,而且也容易有下溢出的情况。而自后向前很好的解决了这个问题,因为输入数组总是有序数组嘛,所以值相等的永远相邻,只需要比较两个相邻元素是否相等,若相等则删去后面的元素。
def removeDuplicates(nums):
for i in range(len(nums)-1,0,-1):
if nums[i] == nums[i-1]:
nums.pop(i)
return len(nums)
这里在介绍一下第三种方法(官方解法),这种方法也是利用双指针,但它体现的是覆盖而不是是删除,首先定义第一个指针i=0,然后利用第二个指针j遍历数组,如果j与i对应元素值不相等,则将j的值赋给i+1,随之指针i也后移一位,这样i+1就是新数组的长度,并且每个元素都不重复。
def removeDuplicates(nums) int:
i = 0
for j in range(len(nums)):
if nums[j]!=nums[i]:
nums[i+1] = nums[j]
i += 1
return i+1
- 方法一用时72ms,内存消耗14.8MB
- 方法二用时56ms,内存消耗14.7MB
- 方法三用时44ms,内存消耗14.7MB
28. 实现 strStr()
题目描述:给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回-1。
示例:输入: haystack = “hello”, needle = "ll"输出: 2、输入: haystack = “aaaaa”, needle = "bba"输出: -1。
第一种方法就是暴力破解,问题是在haystack中找到needle出现的第一个位置,这个位置一定是在0到len(haystack)-len(needle)+1之间,因为剩下的字符串也要匹配嘛。在haystack中利用切片方法搜寻与needle相同的字符串,找到返回第一个位置对应下标,反之返回-1。
def strStr(haystack,needle):
m,n = len(haystack),len(needle)
for i in range(0,m-n+1):
if needle == haystack[i:i+n]:
return i
return -1
第二种方法是利用双指针方法,利用两个指针遍历两个数组,比较对应位置字符是否相同,相同的话两个指针分别加一。不相同的话,如果needle数组中的指针移动过了,则需要将其重置,haystack数组指针则回到二者匹配开始的下一位重新匹配;如果needle数组中的指针未移动,只需将haystack数组指针后移一位即可。
例如haystack=“ababd”,needle=“abd”,二个数组下标为3时,即a和d不匹配,那么haystack数组的指针要指向第一个b的位置,而needle数组的指针则指向a。
def strStr(haystack,needle):
m,n = len(haystack),len(needle)
mar1,mar2=0,0
while mar1<m and mar2<n:
if haystack[mar1] == needle[mar2]:
mar1 += 1
mar2 += 1
else:
if mar2>0:
mar1 = mar1-mar2+1 #回到匹配的下一位
mar2 = 0
else:
mar1 += 1
return mar1-n if mar2==n else -1
- 方法一用时28ms,内存消耗14.8MB
- 方法二用时60ms,内存消耗14.7MB
35. 搜索插入位置
题目描述:给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。
示例:输入: [1,3,5,6], 5输出: 2、输入: [1,3,5,6], 2、输出: 1、输入: [1,3,5,6], 7输出: 4。
第一种方法利用单层循环查找,因为输入数组是排序数组,所以只需要找到数组中第一个大于等于target元素的下标即可,如果等于那么该位置就是target在数组中的位置,如果是大于那么该位置正好是target需要插入的位置;若没有符合条件的元素,则证明target最大,需要插入至列表最后。
def searchInsert(nums,target):
mar = 0
while mar<len(nums):
if nums[mar] >= target:
return mar
mar += 1
return len(nums)
第二种方法是二分查找法,首先初始化一个左指针left和右指针right,并在二者之间找到处于中间位置的下标mid。如果该位置元素小于target,下次查找位于mid+1与right之间的元素;如果该位置元素大于target,则下次查找位于left与mid-1之间的元素;如果两者相等(target在数组中),则直接返回mid,反之返回左指针left。
def searchInsert(nums,target):
left = 0
right = len(nums) - 1
while (left <= right):
mid = (right + left) // 2
if nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
else:
return mid
return left
- 方法一用时44ms,内存消耗14.1MB
- 方法二用时36ms,内存消耗14.4MB