电信商用户流失预警案例(二分类)
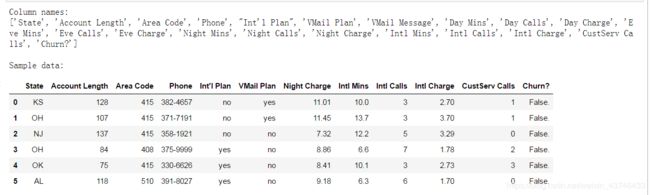
1.查看数据
import pandas as pd
import numpy as np
churn_df = pd.read_csv('churn.csv')
col_names = churn_df.columns.tolist()
print "Column names:"
print col_names
to_show = col_names[:6] + col_names[-6:]
print "\nSample data:"
churn_df[to_show].head(6)
2.清洗数据,转换数据格式
churn_result = churn_df['Churn?']
y = np.where(churn_result == 'True.',1,0)
# We don't need these columns
to_drop = ['State','Area Code','Phone','Churn?']
churn_feat_space = churn_df.drop(to_drop,axis=1)
# 'yes'/'no' has to be converted to boolean values
# NumPy converts these from boolean to 1. and 0. later
yes_no_cols = ["Int'l Plan","VMail Plan"]
churn_feat_space[yes_no_cols] = churn_feat_space[yes_no_cols] == 'yes'
# Pull out features for future use
features = churn_feat_space.columns
X = churn_feat_space.as_matrix().astype(np.float)
# This is important
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
print "Feature space holds %d observations and %d features" % X.shape
print "Unique target labels:", np.unique(y)
print X[0]
print len(y[y == 0])

3.使用SVM,RF,KNN模型用K折验证得到预测值
from sklearn.model_selection import KFold
def run_cv(X,y,clf_class,**kwargs):
# Construct a kfolds object
kf = KFold(n_folds=5,shuffle=True)
y_pred = y.copy()
# Iterate through folds
for train_index, test_index in kf:
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
# Initialize a classifier with key word arguments
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
y_pred[test_index] = clf.predict(X_test)
return y_pred
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.neighbors import KNeighborsClassifier as KNN
#得到预测的结果
def accuracy(y_true,y_pred):
#numpy将“真”和“假”解释为1。和0。
return np.mean(y_true == y_pred)#真实值与预测值
print "Support vector machines:"
print "%.3f" % accuracy(y, run_cv(X,y,SVC))
print "Random forest:"
print "%.3f" % accuracy(y, run_cv(X,y,RF))
print "K-nearest-neighbors:"
print "%.3f" % accuracy(y, run_cv(X,y,KNN))
输出各个模型的K折验证后的准确率

4.预测的流失的概率
- predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
def run_prob_cv(X, y, clf_class, **kwargs):
kf = KFold(n_folds=5, shuffle=True)
y_prob = np.zeros((len(y),2))##[[0,0],[0,0]]
for train_index, test_index in kf:
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
# Predict probabilities, not classes
y_prob[test_index] = clf.predict_proba(X_test)##[[0,0],[1,1]]
# [2 3 2]
# [[0.56651809 0.43348191]
# [0.15598162 0.84401838]
# [0.86852502 0.13147498]]
return y_prob
import warnings
warnings.filterwarnings('ignore')
# Use 10 estimators so predictions are all multiples of 0.1
pred_prob = run_prob_cv(X, y, RF, n_estimators=10)
#print pred_prob[0]
pred_churn = pred_prob[:,1] #预测结果为真实流失的概率
is_churn = y == 1 #[True,Flase,...]
# Number of times a predicted probability is assigned to an observation
counts = pd.value_counts(pred_churn) #预测流失概率的值的计数
#print counts
# calculate true probabilities
true_prob = {}
for prob in counts.index:
true_prob[prob] = np.mean(is_churn[pred_churn == prob])#判断预测的概率值=pred_prob列的值 是否真实流失
true_prob = pd.Series(true_prob) #真实流失率
counts = pd.concat([counts,true_prob], axis=1).reset_index()
counts.columns = ['pred_prob', 'count', 'true_prob']
counts
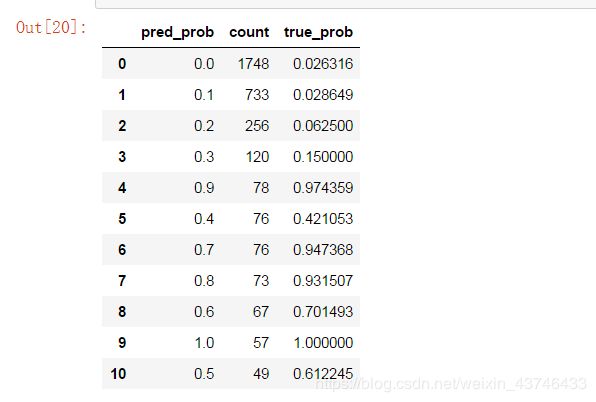
当预测的概率达到流失0.7时,它的实际预测流失值准确率达到了0.94以上!