Python绕过验证码,直接登录爬数据
小编今天准备爬取一个网站的数据,但是被登录的验证码挡住了
小编很不服

于是小编就想着怎么绕过验证码去爬取网站的数据。

虽说图形验证码最简单,但是对于我这等新手,还是要苦学一番。首先寻找测试网站,网站选的是如云阁小说网,小网站不怕被封。他们的验证码一般如下:

可以看出有微弱的干扰线和较强的干扰点,验证码是没有边框的,这里为了排版好看,我加上去的...
1.灰度处理 把彩色验证码图片转为灰色的图片。

importcv2
image = cv2.imread('1.jpeg',0)
cv2.imwrite('1.jpg', image)
2. 二值化处理 将图片处理为只有黑白两色的图片,这里发现干扰线没有了,这就意味着我们只需要处理干扰点即可。

importcv2
image = cv2.imread('1.jpeg',0)
ret, image = cv2.threshold(image,100,255,1)
height, width = image.shape
new_image = image[0:height,0:150]
cv2.imwrite('1.jpg', new_image)
3. 降噪处理 去除小黑点,也就是孤立的黑色像素点。

点降噪原理就是检测黑色点相邻的8个点,判断8个点的颜色情况。如果全是白点,那么就认为这个点是白色的,做黑点变白点处理。如⑤点处,以田字格来看,相邻共有8个区域。
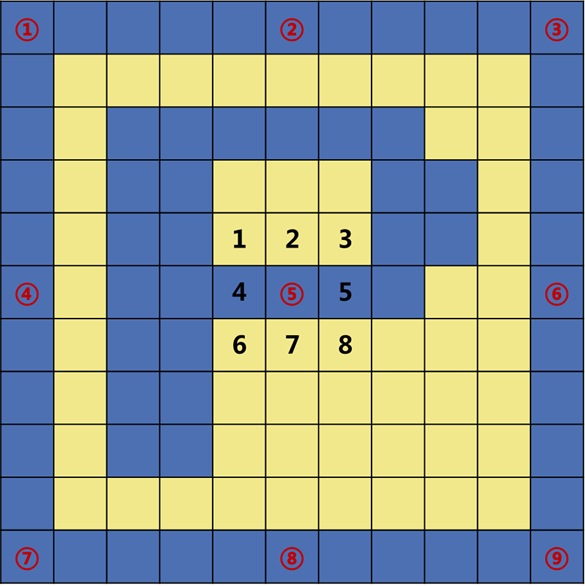
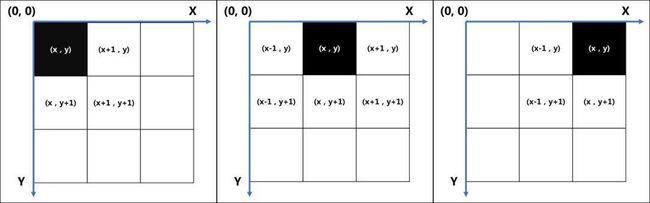
①②③点坐标如下图,同理可知④⑤⑥⑦⑧⑨点坐标情况
降噪代码如下:
importcv2
importnumpyasnp
fromPILimportImage
definverse_color(image, col_range):
# 读取图片,0意味着图片变为灰度图
image = cv2.imread(image,0)
# 图片二值化,100为设置阀值,255为最大阀值,1为阀值类型,当前点值大于阀值,设置为0,否则设置为255。ret是return value缩写,代表当前的阀值
ret, image = cv2.threshold(image,110,255,1)
# 图片的高度和宽度
height, width = image.shape
# 图片反色处理,原因:上面的处理只能生成白字黑底的图片,而我们需要的是黑字白底的图片
img2 = image.copy()
foriinrange(height):
forjinrange(width):
img2[i, j] = (255- image[i, j])
img = np.array(img2)
# 对处理后的图片做截取
height, width = img.shape
new_image = img[0:height, col_range[0]:col_range[1]]
cv2.imwrite('handle_one.png', new_image)
image = Image.open('handle_one.png')
returnimage
defclear_noise(img):
# 图片降噪处理
x, y = img.width, img.height
foriinrange(x):
forjinrange(y):
ifsum_9_region(img, i, j) <2:
# 改变像素点颜色,白色
img.putpixel((i, j),255)
img = np.array(img)
cv2.imwrite('handle_two.png', img)
img = Image.open('handle_two.png')
returnimg
defsum_9_region(img, x, y):
"""
田字格
"""
# 获取当前像素点的颜色值
cur_pixel = img.getpixel((x, y))
width = img.width
height = img.height
ifcur_pixel ==255:# 如果当前点为白色区域,则不统计邻域值
return10
ify ==0:# 第一行
ifx ==0:# 左上顶点,4邻域
# 中心点旁边3个点
sum_1 = cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x +1, y)) + img.getpixel((x +1, y +1))
return4- sum_1 /255
elifx == width -1:# 右上顶点
sum_2 = cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x -1, y)) + img.getpixel((x -1, y +1))
return4- sum_2 /255
else:# 最上非顶点,6邻域
sum_3 = img.getpixel((x -1, y)) + img.getpixel((x -1, y +1)) + cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x +1, y)) + img.getpixel((x +1, y +1))
return6- sum_3 /255
elify == height -1:# 最下面一行
ifx ==0:# 左下顶点
# 中心点旁边3个点
sum_4 = cur_pixel + img.getpixel((x +1, y)) + img.getpixel((x +1, y -1)) + img.getpixel((x, y -1))
return4- sum_4 /255
elifx == width -1:# 右下顶点
sum_5 = cur_pixel + img.getpixel((x, y -1)) + img.getpixel((x -1, y)) + img.getpixel((x -1, y -1))
return4- sum_5 /255
else:# 最下非顶点,6邻域
sum_6 = cur_pixel + img.getpixel((x -1, y)) + img.getpixel((x +1, y)) + img.getpixel((x, y -1)) + img.getpixel((x -1, y -1)) + img.getpixel((x +1, y -1))
return6- sum_6 /255
else:# y不在边界
ifx ==0:# 左边非顶点
sum_7 = img.getpixel((x, y -1)) + cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x +1, y -1)) + img.getpixel((x +1, y)) + img.getpixel((x +1, y +1))
return6- sum_7 /255
elifx == width -1:# 右边非顶点
sum_8 = img.getpixel((x, y -1)) + cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x -1, y -1)) + img.getpixel((x -1, y)) + img.getpixel((x -1, y +1))
return6- sum_8 /255
else:# 具备9领域条件的
sum_9 = img.getpixel((x -1, y -1)) + img.getpixel((x -1, y)) + img.getpixel((x -1, y +1)) + img.getpixel((x, y -1)) + cur_pixel + img.getpixel((x, y +1)) + img.getpixel((x +1, y -1)) + img.getpixel((x +1, y)) + img.getpixel((x +1, y +1))
return9- sum_9 /255
defmain():
img ='1.jpeg'
img = inverse_color(img, (0,160))
clear_noise(img)
if__name__ =='__main__':
main()
解决最大的问题后,接下来就是实现自动登陆。首先使用selenium自动点击登陆按钮。

到登陆界面后,利用selenium自动输入用户名,密码,对验证码区域进行截图。而后对验证码截图进行处理,最后成功获取验证码。
这里为什么是截图呢,原因是验证码图片一直在变化。比如说我现在复制这个8863验证码的图片链接,在新的标签页打开,会发现验证码改变了,不是8863,而是另外一张验证码图片。那么我们通过获取当前页面的验证码链接,从而来获取验证码图片,这种方法肯定是不可行的。
通过查阅相关资料,知道了带cookies访问验证码链接页面,能够成功解决这个问题。不过由于相关的库没导入成功,也就放弃了。等下回做验证码机器学习的时候,再给予解决。

登陆成功

自动登陆代码如下:
importre
importcv2
importtime
importnumpyasnp
importpytesseract
fromPILimportImage
fromseleniumimportwebdriver
fromselenium.webdriver.common.byimportBy
fromselenium.webdriver.support.uiimportWebDriverWait
fromselenium.webdriver.supportimportexpected_conditionsasEC
USER ='你的用户名'
PASSWORD ='你的密码'
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)
definverse_color(image, col_range):...
defclear_noise(img):...
defsum_9_region(img, x, y):...
defauto_login():
"""
实现网页自动登陆
"""
url ='http://www.quanben9.com/'
browser.get(url)
# 查找登陆按钮并点击
button = browser.find_element_by_css_selector('#top1 > div > a:nth-child(3)')
button.click()
# 查找用户名输入框并输入用户名
input_first = browser.find_element_by_name('username')
input_first.send_keys(USER)
# 查找密码输入框并输入密码
input_second = browser.find_element_by_name('password')
input_second.send_keys(PASSWORD)
# 获取浏览器截图后,手动定位验证码位置,获得验证码截图
browser.save_screenshot('Login_page.png')
photo = Image.open('login_page.png')
box = (1210,710,1360,755)
photo.crop(box).save('Verification.png')
# 对验证码进行灰度,二值化处理,而后降噪处理
handle_verification_code('Verification.png')
# 对处理后的验证码图片进行识别
image = Image.open('handle_two.png')
image.show()
result = pytesseract.image_to_string(image)
# 毕竟提供的库识别能力有限,不一定能完整得到结果,需要对结果进行筛选
result = re.sub('[a-zA-Z’!"#$%&'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\]^_`{|}~]+','', result.replace(' ',''), re.S)
print(result)
# 判断识别是否成功
iflen(result) ==4:
# 获得验证码输入框并输入验证码信息
input_third = browser.find_element_by_name('code')
input_third.send_keys(result)
time.sleep(2)
# 获得登陆按钮并点击
button_2 = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div.main > div > form > ul > li:nth-child(5) > input[type="submit"]')))
button_2.click()
time.sleep(5)
else:
returnauto_login()
defhandle_verification_code(img):
img = inverse_color(img, (0,160))
img = clear_noise(img)
returnimg
defmain():
auto_login()
if__name__ =='__main__':
main()
# 结束程序
exit()
这里用会声会影给视频加了个BGM,不过结尾的时候不是很搭,水平有限呐!还是得好好多学习。
文章就到这里啦~