R语言爬虫:豆瓣电影Top250(一)
时间:2018年十一假期(学习) 2018-10-8(记录)
参考:【译文】R语言网络爬虫初学者指南(使用rvest包)
爬取内容:豆瓣电影Top250:排名、片名、评论、评分、评论人数、上映时间、国家以及影片类型
R语言爬虫:豆瓣电影Top250(一)
前期准备
- SelectorGadget:是一个很好用的开源插件,我们可以通过该软件获得所需数据的标签。
- 各种包:rvest、RCurl、stringr以及XML
- 确定爬取内容
豆瓣电影Top250页面如下:
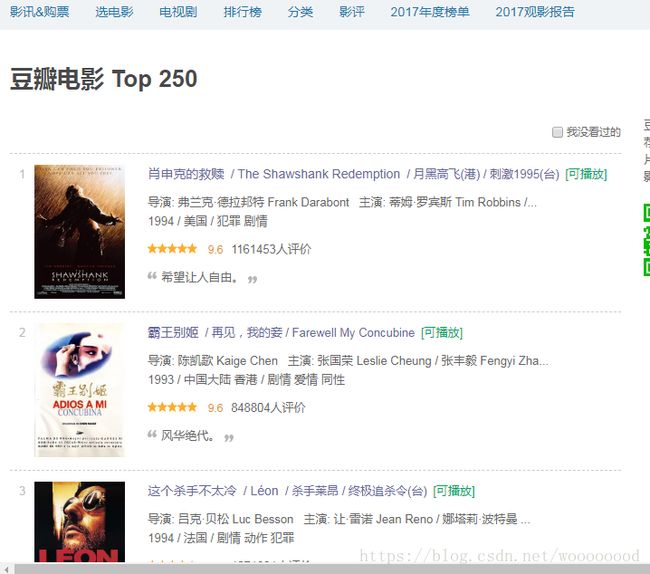
在排行页面显示了电影名称、观看人数、评分、评价人数等。
打开某一电影页面:

确定爬取内容为:
| 变量名 | 内容 | 变量名 | 内容 |
|---|---|---|---|
| rank | 排行 | title | 片名 |
| actor | 主演 | director | 导演 |
| comment | 评价 | rate | 评分 |
| num | 评论人数 | date | 上映时间 |
| nation | 国家 | type | 类型 |
| web | 影片网址 |
爬取数据
> library(rvest)
载入需要的程辑包:xml2
> library(RCurl)
载入需要的程辑包:bitops
> library(XML)
载入程辑包:‘XML’
The following object is masked from ‘package:rvest’:
xml
> library(stringr)
以第一页为例,从网页读取html代码:
> url <- "https://movie.douban.com/top250?start=0&filter="
> webpage <- read_html(url) # 排行榜的网址(10页,每页25个影片)
我们通过影片排名的网页直接获取影片的排名、片名、评价(下图引号内的话)、评价人数以及包含主演、导演等在内的其他信息。
打开网页以及SelectorGadget,使用 selector gadget获得片名的CSS选择器:
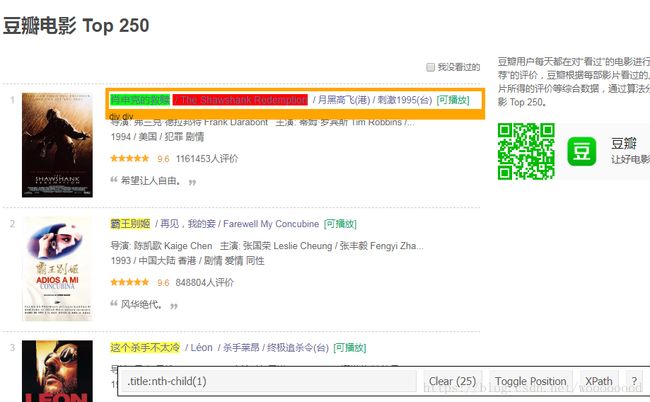
可以看到SelectorGadget的窗口显示相应的CSS选择器为:.title:nth-child(1)。
使用html_nodes函数获取片名部分,然后使用html_text函数将该部分转换为文本:
> # title
> title_data_html <- html_nodes(webpage, ".title:nth-child(1)")
> title_data <- html_text(title_data_html)
> head(title_data)
[1] "肖申克的救赎" "霸王别姬" "这个杀手不太冷" "阿甘正传" "美丽人生"
[6] "泰坦尼克号"
使用SelectorGadget可知排名、评价、评价人数以及其他信息的CSS选择器分别为:“em”、".inq"、".rating_num"、".rating_num~ span"和".bd p:nth-child(1)"。
> # rank
> rank_data_html <- html_nodes(webpage, "em")
> rank_data <- html_text(rank_data_html)
> rank_data <-as.numeric(rank_data)
> # comment
> comment_data_html <- html_nodes(webpage, ".inq")
> comment_data <- html_text(comment_data_html)
> # rate
> rate_data_html <- html_nodes(webpage, ".rating_num")
> rate_data <- html_text(rate_data_html)
> rate_data <- as.numeric(rate_data)
使用上述方法获得了排名,评论以及评分的数据。其中由于爬取的数据均为字符串格式,因此对排名和评分数据使用as.numeric函数将其转化为了数值型。
评价人数的数据爬取与其他几个数据相比较为复杂。
> # number
> num_data_html <- html_nodes(webpage, ".rating_num~ span")
> num_data <- html_text(num_data_html)
> head(num_data)
[1] "" "1161453人评价" "" "848804人评价" ""
[6] "1071831人评价"
可以看出,直接爬取得到的数据包含空字符串以及文字。
使用str_match及正则表达式将其中的数字提取出来:
> num_data <- str_match(num_data, "[0-9]*")
> head(num_data)
[,1]
[1,] ""
[2,] "1161453"
[3,] ""
[4,] "848804"
[5,] ""
[6,] "1071831"
将其转为数值型,并提取非空元素获得评价人数的数据:
> num_data <- as.numeric(num_data)
> num_data <- num_data0[!is.na(num_data)]
> head(num_data)
[1] 1161453 848804 1071831 916553 534936 852450
获取其他信息:
> # information
> information_html <- html_nodes(webpage, ".bd p:nth-child(1)")
> information <- html_text(information_html)
> > head(information, 3)
[1] "豆瓣"
[2] "\n 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...\n 1994 / 美国 / 犯罪 剧情\n "
[3] "\n 导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...\n 1993 / 中国大陆 香港 / 剧情 爱情 同性\n "
可以看出information的第一个元素不是我们想要的,因此我们选择从第二个开始为information。
> information0 <- information0[2:length(information0)]
> information0[1]
[1] "\n 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...\n 1994 / 美国 / 犯罪 剧情\n "
豆瓣电影Top250共10页,每页25个影片,网址分别为:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
……
https://movie.douban.com/top250?start=225&filter=
观察发现该10个网址只有“start=”后的数字不同,为公差为25的等差数列,可以将网址分为4部分,使用paste函数进行连接,并使用循环语句对10页的影片信息进行爬取。
代码如下:
a <- seq(0, 225, by = 25)
information <- list() # 其他信息
rank_data <- list() # 排名
title_data <- list() # 片名
comment_data <- list() # 评论
rate_data <- list() # 评分
num_data <- list() # 观看人数
# 提取排行页面显示的有用信息: 排名、片名、评论、评分、观看人数、其他信息
for(i in 1:10){
url1 <- "https://movie.douban.com/top250"
url2 <- "?start="
url3 <- "&filter="
url<-paste0(url1, url2, a[i], url3)
webpage <- read_html(url) # 排行榜的网址(10页,每页25个影片)
# rank
rank_data_html <- html_nodes(webpage, 'em')
rank_data0 <- html_text(rank_data_html)
rank_data0 <-as.numeric(rank_data0)
rank_data <- c(rank_data, rank_data0)
#title
title_data_html <- html_nodes(webpage, ".title:nth-child(1)")
title_data0 <- html_text(title_data_html)
title_data <- c(title_data, title_data0)
# comment
comment_data_html <- html_nodes(webpage, ".inq")
comment_data0 <- html_text(comment_data_html)
comment_data <- c(comment_data, comment_data0)
# rate
rate_data_html <- html_nodes(webpage, ".rating_num")
rate_data0 <- html_text(rate_data_html)
rate_data0 <- as.numeric(rate_data0)
rate_data <- c(rate_data, rate_data0)
# number
num_data_html <- html_nodes(webpage, ".rating_num~ span")
num_data0 <- html_text(num_data_html)
num_data0 <- str_match(num_data0, "[0-9]*")
num_data0 <- as.numeric(num_data0)
num_data0 <- num_data0[!is.na(num_data0)]
num_data <- c(num_data, num_data0)
# information
information_html <- html_nodes(webpage, ".bd p:nth-child(1)")
information0 <- html_text(information_html)
information0 <- gsub("\n", "", information0)
information <- c(information, information0[2:length(information0)])
}
至此,所需的数据除主演以及导演以外已爬取完成,对于其他信息的处理以及剩下两项数据的爬取见 R语言爬虫:豆瓣电影Top250(二)。