集五福,我用 Python

作者 | Crossin先生
编辑 | Jane
来源 | Crossin的编程教室(ID:crossincode)
【导读】你的五福集齐了吗?作为一名技术人,我们是不是可以用技术方法快速实现呢?今天,我们就为大家推荐四种新鲜的方法,生成风格不同又数量庞大的「福」字,让大家不用满世界找福字,动动手指即可。
作为一个没有寒假、不用回老家也没有年终奖的人,让我发现马上就要过年的现象是:各个群里面又开始集五福了!

五福卡我是没法帮你搞出来。这种 APP 的计算都是放在后端(服务器上),哪怕你完全破解了自己手机上支付宝,该还花呗也还是得还。
不过,我倒是可以帮你生成一些福字,直接拿去扫一扫,省得满世界地找了。没准也能扫出个全家福呢!
以下这些福字,作者 Crossin 都介绍过相关的方法,并且全部都是通过 Python 语言及相关库所生成。好了,不多说了,接下来,我们就赶紧来看看这些方法吧。
一、头像福
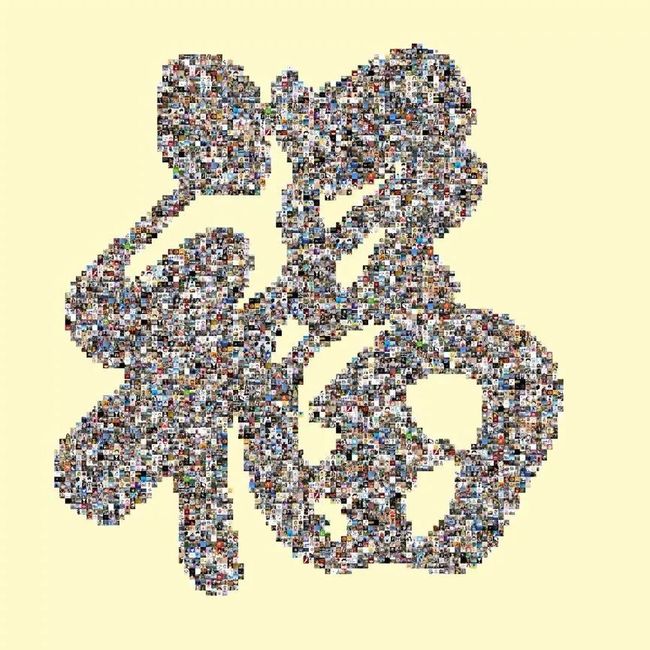
这个福字是用微信好友的头像所组成。之前元宵节的时候用这个方法第一次做了尝试,涉及的原理并不复杂,使用 itchat 和 PIL 库,详细方法和代码:
【第一步】
首先是点阵字的概念:点阵字体是把每一个字符都分成 n * n 个点,然后用每个点的虚实来表示字符的轮廓。点阵字体也叫位图字体,其中每个字形都以一组二维像素信息表示。
汉字那么多,总不能每个字都去自己设计点阵吧?别担心,有现成的点阵字库可以直接使用:HZK16字库。HZK即汉字库的首字母缩写,HZK16字库是符合GB2312标准的16×16点阵字库,支持的汉字有6763个(但可惜不支持英文和数字),每个汉字模型需要16×16一共需要256个点来显示。
这样思路就出来了:我们自己输入汉字,根据字符串中汉字字符编码,去HZK16字库中获取点阵信息,拿到信息后根据16*16点阵每个点的数据,print 出不同字符。
#初始化16*16的点阵位置,每个汉字需要16*16=256个点来表示
rect_list = [] * 16
for i in range(16):
rect_list.append([] * 16)
#拿“赞”字来演示
text = "赞"
#获取中文的编码
gb2312 = text.encode('gb2312')
hex_str = binascii.b2a_hex(gb2312)
result = str(hex_str, encoding='utf-8')
#根据编码计算“赞”在汉字库中的位置
area = eval('0x' + result[:2]) - 0xA0
index = eval('0x' + result[2:]) - 0xA0
offset = (94 * (area-1) + (index-1)) * 32
font_rect = None
#读取HZK16汉字库文件中“赞”字数据
with open("HZK16", "rb") as f:
f.seek(offset)
font_rect = f.read(32)
#根据读取到HZK中数据给我们的16*16点阵赋值
for k in range(len(font_rect) // 2):
row_list = rect_list[k]
for j in range(2):
for i in range(8):
asc = font_rect[k * 2 + j]
flag = asc & KEYS[i]
row_list.append(flag)
#根据获取到的16*16点阵信息,打印到控制台
for row in rect_list:
for i in row:
if i:
#前景字符(即用来表示汉字笔画的输出字符)
print('0', end=' ')
else:
#背景字符(即用来表示背景的输出字符)
print('.', end=' ')
print()
【第二步】
解决了输出字符的问题,接下来就考虑,如何把这些点换成微信好友头像呢?
我们通过 itchat 这个开源的微信个人号接口来获取微信好友头像图片。
#通过二维码登录微信网页版
itchat.auto_login()
#获取微信好友信息列表
friendList = itchat.get_friends(update=True)
#读取好友头像
for friend in friendList:
friend['head_img'] = itchat.get_head_img(userName=friend['UserName'])
friend['head_img_name'] = "%s.jpg" % friend['UserName']
#写入文件
with open(friend['head_img_name'],'wb') as f:
f.write(friend['head_img'])
【第三步】
有了头像之后,我们通过 PIL (Python Image Library,python的第三方图像处理库) 根据汉字点阵信息拼接头像图片。核心代码片段:
#新建画布,16*16点阵,每个图片边长100
canvas = Image.new('RGB', (1600, 1600), '#FFFFFF')
n = 0
for i in range(16*16):
#点阵信息为1,即代表此处要显示头像来组字
if item[i] == "1":
# 打开图片
img = Image.open(imgList[n])
# 缩小图片
img = img.resize((100, 100), Image.ANTIALIAS)
# 拼接图片
canvas.paste(img, ((i % 16) * 100, (i // 16) * 100))
n += 1
综合以上三个步骤,即可用微信好友头像组成你想要的文字了。
如果你嫌弃这 16x16 的字库效果,也可以通过对图片进行二值化处理,以获取更精致的点阵信息来成字符图。比如上面的“福”字,其点阵信息就是我对福字图片处理得到的,最终展示的效果也更美观大方,就像上面的图那样。
二、文字福

这个福字是将福字图片转成文字符号显示而组成,使用 opencv-python 库,详细方法及代码:
# coding: utf8
import cv2 as cv
import os
import time
# 替换字符列表
ascii_char = list(r"$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. ")
char_len = len(ascii_char)
# 加载视频
cap = cv.VideoCapture('video.mp4')
while True:
# 读取视频每一帧
hasFrame, frame = cap.read()
if not hasFrame:
break
# 视频长宽
width = frame.shape[0]
height = frame.shape[1]
# 转灰度图
img_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 缩小图片并调整长宽比
img_resize = cv.resize(img_gray, (int(width / 10), int(height / 10)))
text = ''
# 遍历图片中的像素
for row in img_resize:
for pixel in row:
# 根据像素值,选取对应的字符
text += ascii_char[int(pixel / 256 * char_len)]
text += '\n'
# 清屏
os.system('cls') # mac是'clear'
# 输出生成的字符方阵
print(text)
# 适当暂停一下
time.sleep(0.03)
代码不长,稍微解释下其中几处:
1、ascii_char 这个字符序列并不是必须这样,只要大致上满足其中的字符看起来从深到浅即可,字符越多越准确,效果就越好。
2、读取视频使用了 opencv-python,并直接用它提供的方法转了灰度图。
3、resize 这一步比较重要,因为有的视频分辨率很高,直接一个像素转一个字符的话量太大,所以先缩小图片。另一个原因是字符一般都不是正方形,所以在图片长宽比上要做一定的调整,这样最终效果比较好。(实际中要根据你自己控制台中的字体效果来调整缩放比例)
4、ascii_char[int(pixel / 256 * char_len)] 是整个转换的核心,因为一个像素的颜色范围是 0~255,通过 pixel / 256 * char_len 可以将一个像素值对应于字符序列中灰度相当的字符。
5、关于输出,有几个值得注意的点:输出一帧前需要清屏,不同平台命令有区别;时间间隔、控制台的字体大小、缩放比例都要根据实际情况作调整;如果计算时间过长、刷新太慢而屏幕闪烁,可以考虑进一步缩小图片,或者先将所以帧转换完毕后再统一输出。
这段代码,看起来没啥实际用处,而且有些反潮流,因为现如今大家看视频都追求更高分辨率的超清画质,而我们这个,是一个“超不清”的视频播放器:在控制台里播放视频,用字符来表示画面。
不过我觉得它至少可以有三个作用:1.用来练习视频和图像处理的编程开发;2.在没有图形界面的服务器上播放视频(虽然效果不咋地);3.作为一种独特的艺术风格化处理
程序的原理其实很简单,关键是你要理解计算机中一张图像的组成:一堆像素点。我们平常说的 1920*1080 之类的分辨率,也就是指这个像素点的多少。我们想做成字符画,也就是考虑如何用不同的字符来表示一个像素。
通常一个像素点由3个0~255的值表示,分别表示红、绿、蓝三种颜色值,值越大表示颜色越深。但字符画是没有颜色的,所以需要将图像转成灰度图,这样就可以跟一组从深到浅的字符形成一种对应关系。比如深的点就是 @,浅色的点就是 .。
一幅图像全部转成字符序列后,就可以直接在控制台输出了。对于一个视频来说,只需要将每一帧都转换后输出,并按照一定的时间间隔清屏、输出下一帧,即可达到我们的需要的效果。
转换后的效果:
三、名画福

如果左边跟着梵高画个福,再跟着毕加索右边画个福,会是什么样的效果?这两个福字分别通过梵高的《星空》和毕加索的《缪斯》风格生成,这里我们选择使用 opencv-python 中的 DNN(深度神经网络)。
这种功能叫做“图像风格迁移”,几乎都是基于 CVPR 2015 的论文《A Neural Algorithm of Artistic Style》和 ECCV 2016 的论文《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》中提出的算法,以及后续相关研究的基础上开发出来的。
通俗来讲,就是借助于神经网络,预先将名画中的风格训练成出模型,在将其应用在不同的照片上,生成新的风格化图像。

来自《A Neural Algorithm of Artistic Style》
而因为神经网络在计算机视觉方面的应用越来越广,著名的视觉开发库 OpenCV 在 3.3 版本中正式引入 DNN(深度神经网络),支持 Caffe、TensorFlow、Torch/PyTorch 等主流框架的模型,可用以实现图像的识别、检测、分类、分割、着色等功能。
在 OpenCV 的 Sample 代码中就有图像风格迁移的 Python 示例,是基于 ECCV 2016 论文中的网络模型实现。所以,即使作为人工智能的菜鸟,也可以拿别人训练好的模型来玩一玩,体会下神经网络的奇妙。
OpenCV 官方代码地址:
https://github.com/opencv/opencv/blob/3.4.0/samples/dnn/fast_neural_style.py
目录下通过执行命令运行代码:
python fast_neural_style.py --model starry_night.t7
model 参数是提供预先训练好的模型文件路径,OpenCV 没有提供下载,但给出的参考项目 https://github.com/jcjohnson/fast-neural-style 中可以找到
其他可设置参数有:
input 可以指定原始图片/视频,如果不提供就默认使用摄像头实时采集。
width、height,调整处理图像的大小,设置小一点可以提高计算速度。在我自己的电脑上,300x200 的转换视频可以达到 15 帧/秒。
median_filter 中值滤波的窗口大小,用来对结果图像进行平滑处理,这个对结果影响不大。
执行后的效果(取自 jcjohnson/fast-neural-style):

原始图像

ECCV16 models

instance_norm models
核心代码其实很短,就是 加载模型 -> 读取图片 -> 进行计算 -> 输出图片,我在官方示例基础上进一步简化了一下:
import cv2
# 加载模型
net = cv2.dnn.readNetFromTorch('the_scream.t7')
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV);
# 读取图片
image = cv2.imread('test.jpg')
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (w, h), (103.939, 116.779, 123.680), swapRB=False, crop=False)
# 进行计算
net.setInput(blob)
out = net.forward()
out = out.reshape(3, out.shape[2], out.shape[3])
out[0] += 103.939
out[1] += 116.779
out[2] += 123.68
out /= 255
out = out.transpose(1, 2, 0)
# 输出图片
cv2.imshow('Styled image', out)
cv2.waitKey(0)
四、变形福

如何用 python 的图像处理功能,把一幅“福”字图片转出 5 种不同的效果?在接下来使用 opencv-python的几个方法教程中,总有一款适合你,方法及代码:
【第1步】
读取图片及展示代码:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('fu.png')
# 转换颜色模式,显示原图
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
因为 OpenCV 和 matplotlib 的颜色模式不一样,所以需要做一次转换,如果是直接通过 cv2 展示和保存图片则不需要。
【第2步】
上面的效果分别用到了以下功能:
1、灰度福
这里没有选择直接将图片转出灰度图,因为这样会导致福字不明显。而是通过将红、绿、蓝三通道分离后,选择色差最大的红色通道。
r,g,b = cv2.split(img)
2、轮廓福
使用了 OpenCV 自带的图像轮廓提取功能。为了更好的效果,这里对红色通道进行二值化后,再查找轮廓。
_, img_bin = cv2.threshold(r, 50, 255, cv2.THRESH_BINARY)
_, contours, _ = cv2.findContours(img_bin, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
img_cont = np.zeros(img_bin.shape, np.uint8)
cv2.drawContours(img_cont, contours, -1, 255, 3)
3、反色福
发色的实现是将每个像素值 x 转成 255-x。如果遍历像素计算会比较慢,于是用了一个小技巧:转成 numpy 的 ndarray 再进行矩阵运算。
img_i = np.asarray(img)
img_i = 255 - img_i
4、膨胀福
这里其实是“图像腐蚀”操作(与“图像膨胀”操作相反)。因为在我们选取的红色通道中,白色是背景,黑色才是福字,所以对白色的“腐蚀”也就是对黑色的“膨胀”。这也是 OpenCV 的内置功能。做完这一步,又对图像进行了切割,直接通过列表的切片操作实现。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(25, 25))
eroded = cv2.erode(r, kernel)
size = img.shape
eroded = eroded[int(size[1]*0.15):int(size[1]*0.7),int(size[0]*0.2):int(size[0]*0.85)]
5、福到了
OpenCV 提供了翻转操作,第二个参数是旋转轴的选取,你可以试试 0 和 1 的效果。
img_r = cv2.flip(img, -1)
经验证,以上福字皆可扫。本人已集齐

最后,再送上一张阿里某马姓员工写的福字,据说扫它能抽到稀有福!

◆
精彩推荐
◆
2020年,由 CSDN 主办的「Python开发者日」活动(Python Day)正式启动。我们将与 PyCon 官方授权的 PyCon中国社区合作,联手顶尖企业、行业与技术专家,通过精彩的技术干货内容、有趣多元化的活动等诸多体验,共同为中国 IT 技术开发者搭建专业、开放的技术交流与成长的家园。未来,我们和中国万千开发者一起分享技术、践行技术,铸就中国原创技术力量。
【Python Day——北京站】现已正式启动,「新春早鸟票」火热开抢!2020年,我们还将在全国多个城市举办巡回活动,敬请期待!
活动咨询,可扫描下方二维码加入官方交流群~
CSDN「Python Day」咨询群 ????
来~一起聊聊Python

如果群满100人,无法自动进入,可添加会议小助手微信:婷婷,151 0101 4297(电话同微信)
推荐阅读
好扑科技技术副总裁戎朋:从海豚浏览器技术负责人到区块链,揭秘区块链技术之路
区块链第一,情商上榜,2020找工作需要哪些技能?
以太坊2.0发布最终规范:将IETF BLS标准集成到eth2的规范中、部分测试网现已升级到主网配置……
2019全年盘点之一:公链生死战场
BSV魔幻爆拉背后:CSW称拿到自证中本聪的关键证据
掌握 8 种语言、被阿里点赞,这名德国程序员简直开挂了!
K8s 实践 | 如何解决多租户集群的安全隔离问题?
为什么 k8s 在阿里能成功?| 问底中国 IT 技术演进
170个新项目,579个活跃代码仓库,Facebook开源年度回顾
春节加班,老铁们求在看!????