爬取51job可视化分析(一)——数据清洗
数据分析岗位
数据分析是当下每个互联网人不可或缺的技能,我是去年才开始入坑的大四计算机专业学生,现在面临春招,我现在还是有点楞逼的,继续做点项目充实一下自己空闲的心吧!爬虫分析一波51job有关数据分析的岗位吧。(个人学习项目,思维不严谨的地方,望和大家交流交流。)
需求分析
1.应届毕业生找数据分析岗位的薪资如何?不同城市的薪资的影响?学历对薪资的影响?
2.哪些城市对数据分析岗位的需求大?哪些行业对数据分析岗位的需求量大?
3.初级的数据分析都该掌握哪些技能?
数据获取
1.先来看看我的搜索条件吧,只是对于应届生而言的数据分析师岗位。
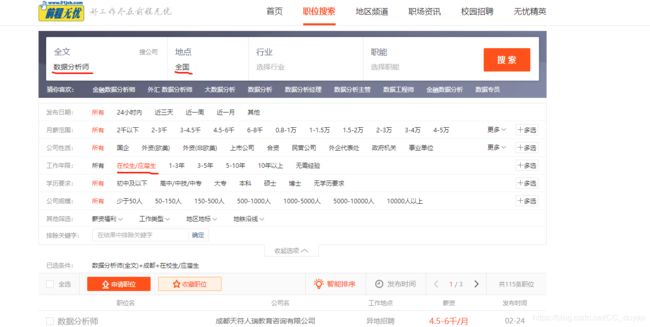
2.爬虫部分这里就自动跳过了,重点是数据分析。这里直接把爬下来的csv文件分析给大家:
链接:https://pan.baidu.com/s/1SSW9sOn_u3_oC-9IJ4ksnA
提取码:5oxg
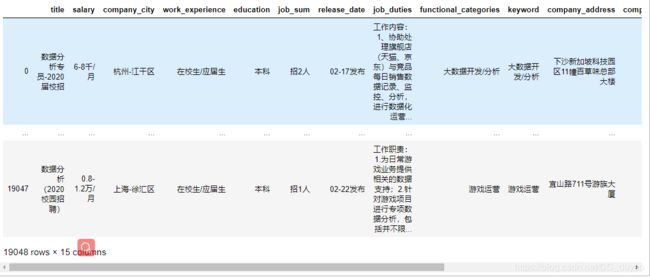
用Pandas打开如下,一共有1.9w条数据
数据清洗
1.删除职业名称与数据分析无关的信息。
import pandas as pd
import re
data = pd.read_csv('shujufenxi.csv')
b = u'数据'
a = u'分析'
number = 1
li = data['title']
for i in range(0,len(li)):
try:
if a in li[i] or b in li[i]:
#print(number,li[i])
number+=1
else:
data = data.drop(i,axis=0)
except:
pass
代码我是用Jupyter Notebook 写的,这一步直接删除了1.7w条数据。(这一刻感觉爬虫都白爬了,需求这么少的吗?没事,下次爬大数据的)
2.查看重复值,并删除
#查看重复值,这里每个数据没有唯一标识,所以用全查重。
print((data.duplicated()).sum())
#删除重复值,保留第一个
data.drop_duplicates(keep='first',inplace=True)
3.查看缺失值,并处理
#查看缺失值的分布情况,会发现工资,公司规模等字段会有缺失。
print((data.isnull()).sum())
#删除工资为NAN的行
data.dropna(axis = 0,subset = ['company_industry','company_categories'],inplace=True)
#由于数据量有点少,这里不删除,用上面一个值填充缺失值。
data.fillna(method='ffill',axis=0,inplace=True)
4.salary单位转换
a.先来看看单位构成吧,6-9千/月,我当时头也是有点疼的。那就一步一步来吧。

b.先看看是不是所有salary都是一个范围(包含符号‘-’)
#对数据观察,查看工资的格式是否都是'xx-xx千/月'
data[~data.salary.str.contains('-')]
#删除这一部分数据,对data重新赋值
data = data[data.salary.str.contains('-')]

会发现这种xx元/天的都是实习岗位,我们要找的是正式工作,删除这一部分数据。
c.再来看看现在工资的单位。
#查看salary这一行所有字段的后三位,并统计
data.salary.str[-3:]).value_counts()
输出:千/月 983 万/月 633 万/年 43
d.单位转换(以千/月作为基本单位),并转为float型
#将最低工资和最高工资分开
salary_list = data.salary.str.split('-')
#求出最高工资
data['max_salary'] = salary_list.str.get(1)
#lambda x: 语句1 if 条件1 else 语句2 if 条件2 else 语句3 实际上是下面这样表达 lambda x: 语句1 if 条件1 else ( 语句2 if 条件2 else 语句3 )
data['max_salary'] = data['max_salary'].map(lambda x: float(x.strip('万/月'))*10 if ('万/月' in x)
else float(x.strip('万/年'))*10/12 if ('万/年' in x)
else float(x.strip('千/月')))
#得出最低工资
data['min_salary']= data['salary'].map(lambda x: float(x.split('-')[0])*10 if ('万/月' in x)
else float(x.split('-')[0])*10/12 if ('万/年' in x)
else float(x.split('-')[0]))
5.整理公司所在城市的信息
如图:company_city的部分包含了所在区域,就全国范围来看,我们只需将公司位置精确到每个市就好了。

#整理城市信息
data['company_city'] = data['company_city'].map(lambda x: x.split('-')[0] if ('-') in x else x)
6.异常值处理
查看最低工资的分布:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("poster")
plt.figure(figsize=(30,10))
sns.boxplot(y="min_salary",data=data);

#为了准确性,把月薪大于15K的离群点
data = data[data.min_salary <15.0]
max_salary同理把大于20K的数据祛除掉。
7.祛除频次较低的数据
这一步是为了避免一些较少的数据影响整体的分析结果;如:各城市平均薪资对比图,北京市的所有该岗位平均薪资是8000,而成都市只有一个岗位,但是薪资为12000,把12000当作成都市的该岗位平均工资,对于分析有很大的影响。
先来祛除岗位较少的城市
#按照company_city进行分组,并统计每个company_city有多少个岗位
count_city = data.groupby(by='company_city')['company_city'].count()
dic = count_city.to_dict()
#赋值到data['count_city']中
data['count_city'] = data['company_city'].map(dic)
#把频次小于10 的删除掉
data = data[data.count_city > 10]
对于祛除频次较低的数据我多少还是有点疑惑。该不该祛除?或者怎样处理?有没有更简便的方法?求大神指点。
后续祛除了‘education’,‘company_categories’等字段频次较少的数据。
总结
经过以上的数据清洗,总算得到了这样1214条数据:
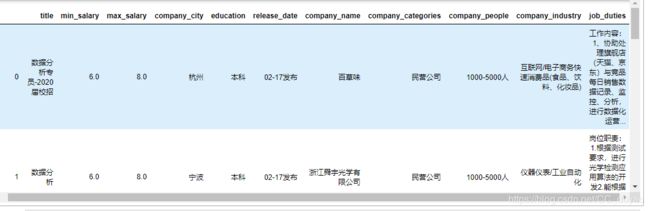
1.数据量从1.9w条到0.12w条,缩水了十倍之多,主要还是数据获取方面出现了问题,以后在学习生活中一定要注意数据获取的准确性,减少无用功。
2.刚开始想学数据分析的时候,就想着怎么获取数据是最重要的(爬虫),觉得数据分析没什么难的,现在觉得思维限制了自己,希望大家以后少走弯路吧,锻炼分析思维最重要,怎样从数据中发现问题,解决问题。
3.本篇文章就是想给大家分享分享,顺便请教一下大家,特别是关于处理频次较少数据的那个问题,望高人之路。
处理完后的数据我放在下篇文章。