java数据结构简述
数据结构是计算机存储,组织数据的方式。它们之间存在一种或多种特定关系的元数据集合
常见的数据结构有:
- 数组(Array),
- 链表(Linked List),
- 栈(stack),
- 队列(queue),
- 图(graph),
- 树(tree),
- 哈希表(hash),
- 堆(heap)
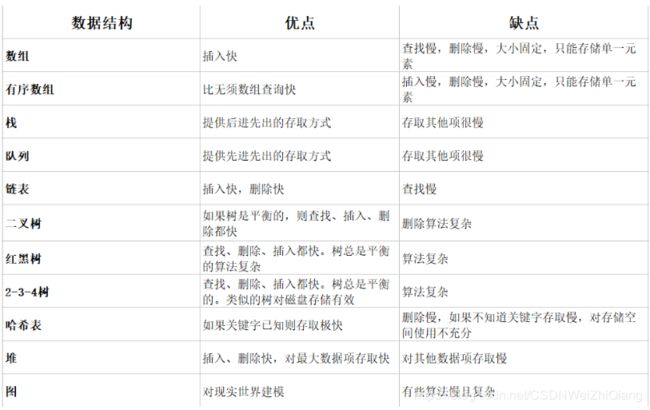
数组的局限性分析:
①、插入快,对于无序数组,上面我们实现的数组就是无序的,即元素没有按照从大到小或者某个特定的顺序排列,只是按照插入的顺序排列。无序数组增加一个元素很简单,只需要在数组末尾添加元素即可,但是有序数组却不一定了,它需要在指定的位置插入。
②、查找慢,当然如果根据下标来查找是很快的。但是通常我们都是根据元素值来查找,给定一个元素值,对于无序数组,我们需要从数组第一个元素开始遍历,直到找到那个元素。有序数组通过特定的算法查找的速度会比无需数组快,后面我们会讲各种排序算法。
③、删除慢,根据元素值删除,我们要先找到该元素所处的位置,然后将元素后面的值整体向前面移动一个位置。也需要比较多的时间。
④、数组一旦创建后,大小就固定了,不能动态扩展数组的元素个数。如果初始化你给一个很大的数组大小,那会白白浪费内存空间,如果给小了,后面数据个数增加了又添加不进去了。
很显然,数组虽然插入快,但是查找和删除都比较慢,而且扩展性差,所以我们一般不会用数组来存储数据,那有没有什么数据结构插入、查找、删除都很快,而且还能动态扩展存储个数大小呢,答案是有的,但是这是建立在很复杂的算法基础上,后面我们也会详细讲解。
栈
栈(英语:stack)又称为堆栈或堆叠,栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。
栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。
由于堆叠数据结构只允许在一端进行操作,因而按照后进先出(LIFO, Last In First Out)的原理运作。栈也称为后进先出表。
这里以羽毛球筒为例,羽毛球筒就是一个栈,刚开始羽毛球筒是空的,也就是空栈,然后我们一个一个放入羽毛球,也就是一个一个push进栈,当我们需要使用羽毛球的时候,从筒里面拿,也就是pop出栈,但是第一个拿到的羽毛球是我们最后放进去的。
队列
队列(queue)是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表。
比如我们去电影院排队买票,第一个进入排队序列的都是第一个买到票离开队列的人,而最后进入排队序列排队的都是最后买到票的。
在比如在计算机操作系统中,有各种队列在安静的工作着,比如打印机在打印列队中等待打印。
队列分为:
①、单向队列(Queue):只能在一端插入数据,另一端删除数据。
②、双向队列(Deque):每一端都可以进行插入数据和删除数据操作。
这里我们还会介绍一种队列——优先级队列,优先级队列是比栈和队列更专用的数据结构,在优先级队列中,数据项按照关键字进行排序,关键字最小(或者最大)的数据项往往在队列的最前面,而数据项在插入的时候都会插入到合适的位置以确保队列的有序。
栈和队列的总结
我们介绍了队列的三种形式,分别是单向队列、双向队列以及优先级队列。其实大家听名字也可以听得出来他们之间的区别,单向队列遵循先进先出的原则,而且一端只能插入,另一端只能删除。双向队列则两端都可插入和删除,如果限制双向队列的某一段的方法,则可以达到和单向队列同样的功能。最后优先级队列,则是在插入元素的时候进行了优先级别排序,在实际应用中单项队列和优先级队列使用的比较多。后面讲解了堆这种数据结构,我们会用堆来实现优先级队列,改善优先级队列插入元素的时间。
通过前面讲的栈以及本篇讲的队列这两种数据结构,我们稍微总结一下:
①、栈、队列(单向队列)、优先级队列通常是用来简化某些程序操作的数据结构,而不是主要作为存储数据的。
②、在这些数据结构中,只有一个数据项可以被访问。
③、栈允许在栈顶压入(插入)数据,在栈顶弹出(移除)数据,但是只能访问最后一个插入的数据项,也就是栈顶元素。
④、队列(单向队列)只能在队尾插入数据,对头删除数据,并且只能访问对头的数据。而且队列还可以实现循环队列,它基于数组,数组下标可以从数组末端绕回到数组的开始位置。
⑤、优先级队列是有序的插入数据,并且只能访问当前元素中优先级别最大(或最小)的元素。
⑥、这些数据结构都能由数组实现,但是可以用别的机制(后面讲的链表、堆等数据结构)实现。
前缀、中缀、后缀表达式
对于表达式 3+4-5,我们人是有思维能力的,能根据操作符的位置,以及操作符的优先级别能算出该表达式的结果。但是计算机怎么算?
计算机必须要向前(从左到右)来读取操作数和操作符,等到读取足够的信息来执行一个运算时,找到两个操作数和一个操作符进行运算,有时候如果后面是更高级别的操作符或者括号时,就必须推迟运算,必须要解析到后面级别高的运算,然后回头来执行前面的运算。我们发现这个过程是极其繁琐的,而计算机是一个机器,只认识高低电平,想要完成一个简单表达式的计算,我们可能要设计出很复杂的逻辑电路来控制计算过程,那更不用说很复杂的算术表达式,所以这样来解析算术表达式是不合理的,那么我们应该采取什么办法呢?
请大家先看看什么是前缀表达式,中缀表达式,后缀表达式:这三种表达式其实就是算术表达式的三种写法,以 3+4-5为例
①、前缀表达式:操作符在操作数的前面,比如 ±543
②、中缀表达式:操作符在操作数的中间,这也是人类最容易识别的算术表达式 3+4-5
③、后缀表达式:操作符在操作数的后面,比如 34+5-
上面我们讲的人是如何解析算术表达式的,也就是解析中缀表达式,这是人最容易识别的,但是计算机不容易识别,计算机容易识别的是前缀表达式和后缀表达式,将中缀表达式转换为前缀表达式或者后缀表达式之后,计算机能很快计算出表达式的值,那么中缀表达式是如何转换为前缀表达式和后缀表达式,以及计算机是如何解析前缀表达式和后缀表达式来得到结果的呢?(请参考:https://www.cnblogs.com/ysocean/p/7910432.html)
链表
前面我们在讲解数组中,知道数组作为数据存储结构有一定的缺陷。在无序数组中,搜索性能差,在有序数组中,插入效率又很低,而且这两种数组的删除效率都很低,并且数组在创建后,其大小是固定了,设置的过大会造成内存的浪费,过小又不能满足数据量的存储。
这里我们将讲解一种新型的数据结构——链表。我们知道数组是一种通用的数据结构,能用来实现栈、队列等很多数据结构。而链表也是一种使用广泛的通用数据结构,它也可以用来作为实现栈、队列等数据结构的基础,基本上除非需要频繁的通过下标来随机访问各个数据,否则很多使用数组的地方都可以用链表来代替。
但是我们需要说明的是,链表是不能解决数据存储的所有问题的,它也有它的优点和缺点。使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
递归,就是在运行的过程中调用自己。
递归必须要有三个要素:
①、边界条件
②、递归前进段
③、递归返回段
当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
没个递归方法每次都是用不同的参数值反复调用自己,当某种参数值使得递归的方法返回,而不再调用自身,这种情况称为边界值,也叫基值。当递归方法返回时,递归过程通过逐渐完成各层方法实例的未执行部分,而从最内层返回到最外层的原始调用处。
阶乘、汉诺塔、归并排序等都可以用递归来实现,但是要注意任何可以用递归完成的算法用栈都能实现。当我们发现递归的方法效率比较低时,可以考虑用循环或者栈来代替它。
还有树,堆,高级排序在这篇博客中有详细的讲解
https://www.cnblogs.com/ysocean/category/1120217.html