Python数据分析神器——pandas(进阶教程)
文章目录
- 合并数据集
- 索引的合并
- 轴向连接
- 合并重叠数据
- 重塑和轴向旋转
- 重塑层次化索引
- 将“长格式”旋转为“宽格式”
- 数据转换
- 移除重复数据
- 利用函数或映射进行数据转换
- 替换值
- 重命名轴索引
- 离散化和面元划分
合并数据集
pandas对象中的数据可以通过一些内置的方式进行合并:
- pandas.merge 可以根据一个或多个键将不同DataFrame中的行连接起来
- pandas.concat 可以沿着一条轴将多个对象堆叠到一起
- 实例方法 combine_first 可以将重复数据连接在一起,用一个对象中的值填充另一个对象中的缺失值
默认情况下,merge做的是“inner”连接,结果中的键是交集。其他方式还有“left”、“right”以及“outer”。外连接求取的是键的并集,组合了左连接和右连接的效果
多对多连接产生的是行的笛卡尔积
在进行列——列连接时,DataFrame对象中的索引会被丢弃

索引的合并
有时候,DataFrame中的连接键位于其索引中。在这种情况下,可以传入left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键。
对于层次化索引的数据,必须以列表的形式指明用作合并键的多个列
DataFrame还有一个join实例方法,它能更为方便地实现按索引合并。它还可用于合并多个带有相同或相似索引的DataFrame对象,而不管它们之间有没有重叠的列
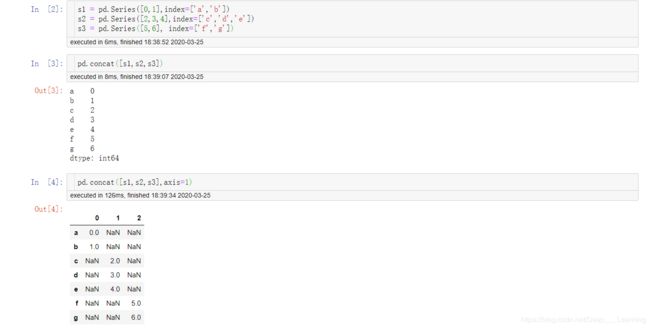
轴向连接
pandas的concat函数提供了轻松完成轴向连接的可靠方式
默认情况下,concat是在axis=0上进行合并,当然,我们也可以令axis=1

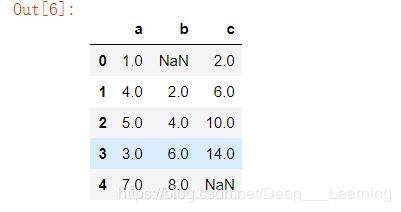
合并重叠数据
combine_first方法可以实现合并重叠数据,并且会进行数据对齐
df1 = pd.DataFrame({'a':[1.,np.nan,5.,np.nan],'b':[np.nan,2.,np.nan,6.],'c':range(2,18,4)})
df2 = pd.DataFrame({'a':[5.,4.,np.nan,3.,7.],'b':[np.nan,3.,4.,6.,8.]})
df1.combine_first(df2)
重塑和轴向旋转
有许多用于重新排列表格型数据的基础运算,这些函数也称作重塑或轴向旋转运算。
重塑层次化索引
- stack:将数据的列“旋转”为行
- unstack:将数据的行“旋转”为列
默认情况下,unstack操作的是最内层(stack也是如此)。传入分层级别的编号或名称即可对其他级别进行unstack操作
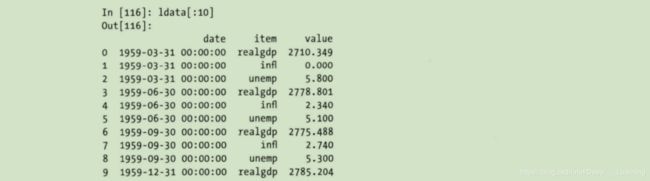
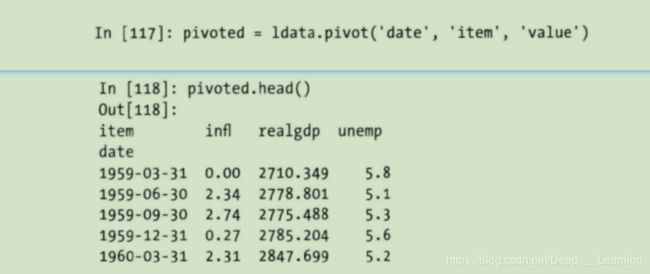
将“长格式”旋转为“宽格式”
DataFrame的pivot方法可以实现这个转换
数据转换
移除重复数据
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行
drop_duplicates方法用于返回一个移除了重复行的DataFrame
duplicated和drop_duplicates默认保留的是第一个出现的值组合,我们可以通过传入take_last=True来保留最后一个
利用函数或映射进行数据转换
使用map可以实现元素级转换以及其他数据清理工作的便捷方式
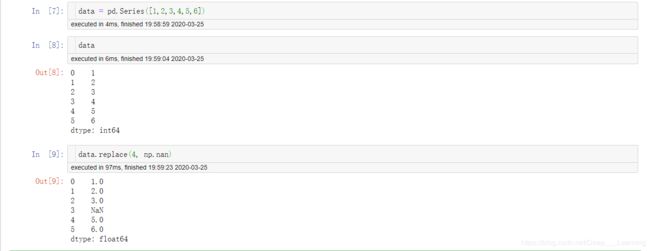
替换值
replace提供了一种实现该功能的更简单、更灵活的方式
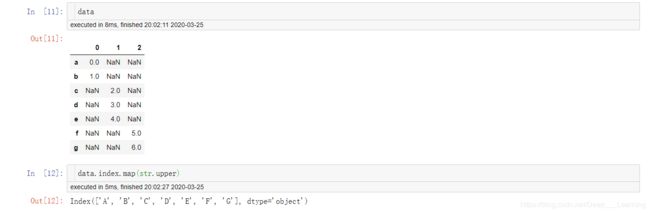
重命名轴索引
可以通过轴标签的map方法来操作轴标签
同样,rename也可以实现上述操作,特别地,rename可以结合字典型对象实现对部分轴标签的更新
rename 帮我们实现了: 复制DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据,传入inplace=True即可实现
离散化和面元划分


qcut 是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。
根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以实现此功能