【剑指offer知识点整理】第三章数据库
首先是对数据库面试中考点的梳理,包含以下几方面:
架构,索引,锁,语法,理论范式,其中索引,锁,语法应该是重点。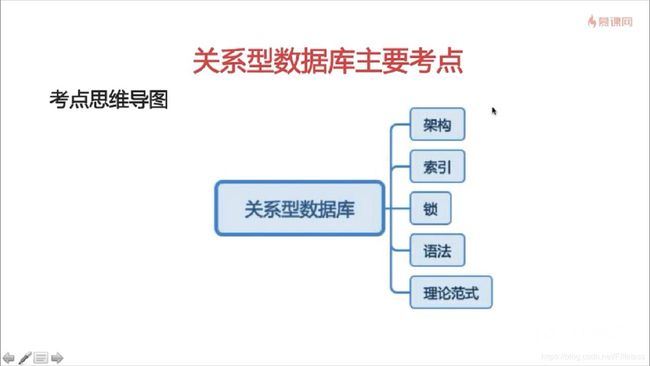
索引模块
(1)为什么要使用索引?
在数据表较大,查询操作较多的时候,建立索引可以避免查询数据时的全表扫描。全表扫描的时间复杂度为O(n),而索引缺只是O(logN)。因此,对查询效率的提升很大。
而索引的数据结构有二叉树,b数,b+树,哈希结构等。

二叉查找树中,如果树的的分支一直往左右子树的一边发展,则很容易变成线性查找。时间复杂度就会变成O(n),并且每次读入数据块都会有一次I/O查询,所有也会有n次I/O查询,这样的效率就会比全表扫描还要慢。那么要解决这些问题呢,就要引入另一种数据结构B树了。



B-Tree的结构和二叉树相比可以有多个节点,可以使树的高度减小 。如上图定义,B-Tree的这些约束都是尽可能的减小树的高度,减少I/O次数。
而B+ Tree是一种相当B-Tree更好的实现。
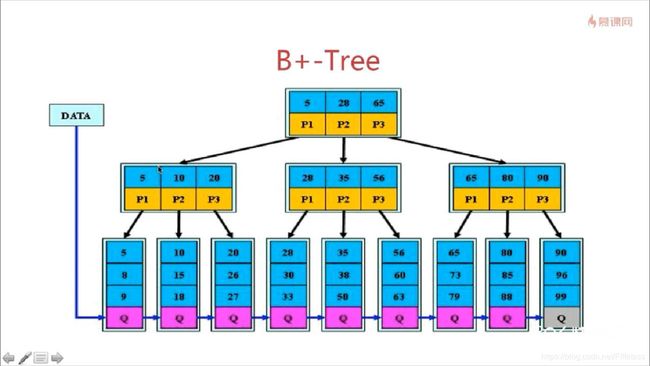


因为B+树的非叶子节点都不存储数据,只有每个非叶子节点也就更小,这样一个盘块中一次I/O可以读取的非叶子节点也就更多,相对来说也就降低了磁盘I/O次数。而且B+树的树的每个分支高度都是固定的,所有查询的效率也会更加稳定。B+树中,叶子节点的数据之间都有一个链指针指向下一个节点,所有对于范围查找就可以在一次查找到一个叶子节点之后,只需要遍历叶子节点就可以。这也是为什么现在主流数据库都采用B+树作为索引的数据结构(MYSQL,Oracle还有待考证)。
索引类型的区分
聚集索引:聚集索引是索引和表中数据的物理存储顺序一致的索引,每张表中只能存在一个,因为表中的存储顺序只能是一种。
聚集索引的使用场合为:
a.查询命令的回传结果是以该字段为排序依据的;
b.查询的结果返回一个区间的值;
c.查询的结果返回某值相同的大量结果集。
聚集索引会降低 insert,和update操作的性能,所以,是否使用聚集索引要全面衡量。
个人理解:因为索引和表中数据的存储顺序一致,所以当索引查找到之后可以读取磁盘上的数据,而因为其顺序存储,所以可以减小I/O次数。(有待考证)
非聚集索引: 索引顺序与物理存储顺序不同
非聚集索引的使用场合为:
a.查询所获数据量较少时;
b.某字段中的数据的唯一性比较高时;
非聚集索引必须是稠密索引
聚簇索引:聚簇索引不是一种具体的索引,而是索引存储的方式。类似于将一部分相同或相似的内容放在一个块中,查找时只需要在这个块中查找,相比于非聚簇索引效率高一些,但是相对来说,增删这种操作是否更慢了呢。(有待考证)
稠密索引:每个索引键都对应一个索引项,相比于稀疏索引,索引键肯定建的更多了,暂用空间也就大了,但是在查询时应该更快,插入和删除的开销也更大。
稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止。
最左匹配原则
最左匹配原则是因为建立联合索引的时候要有第一个索引进行排序,然后再根据第一个索引的排序结果排序后面的索引,所以需要第一个索引值。

索引是否建得越多越好?
答案显然是否定的。索引建立越多,维护成本越高,占用空间越大。因为当数据变更时,索引时需要维护的。一个数据量很小的表没有必要建立索引。

锁模块
锁主要有表级锁和行级锁的区别
表级锁:上了表级锁之后,会锁住整个表的数据。
行级锁:上行级锁只会锁住该行数据,不影响其他数据。
锁也有共享锁和排他锁的分别
共享锁:上共享锁之后,其他会话也可以获取共享锁查询该数据。
排他锁:上排他锁之后,其他会话不能操作该数据。
锁还有乐观锁和悲观锁的区别
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。乐观锁不能解决脏读的问题。
事务模块
事务隔离级别的设置主要是为了避免脏读,不可重复读,幻读等问题的发生。
READ_UNCOMMIT:该事务隔离级别为最低的,不能避免脏读的发生,因为可以读其他事务没有提交的数据,所以会造成脏读。因为事务没有提交的数据,可能会回滚,而当另一个事务取到了回滚前的数据也就造成了脏读。
READ_COMMIT:该事务隔离级别可以避免脏读,但是不能避免不可重复读。因为同一个事务中先读取的数据,在另一个事务修改并提交后再次读取,就会造成不可重复读,而不可重复读问题主要发生在数据修改中。
REPEATABLE_READ:该事务隔离级别可以避免不可重复读,但是不能避免幻读。
SERIALIZABLE:该隔离级别可以避免幻读,幻读是指在一个事务对全表或范围数据进行修改操作时,另一个事务新增了一条数据,而这条数据没有被修改,就像产生了幻觉一样。
语法模块
关系型数据库的关键语法有join,group by,having等
join:
inner join:意思是内连接 把匹配的信息全部查出来。
left join:左连接 意思是包含左边表所有记录,右边所有的匹配的记录,如果没有则用空补齐。
right join 右连接 意思是包括右边表所有记录,匹配左边表的记录,如果没有则以空补齐。
full join 全连接 意思是左右表所有的记录全部显示出来。
group by:

having:
