常见的五种神经网络(5)-生成对抗网络(下)之GAN、DCGAN、W-GAN
在上一篇文章中介绍了生成模型的基本结构、功能和变分自动编码器,在本篇文章中主要介绍一下生成对抗网络(Generative Adversaarial Networks,GAN)
KL散度、JS散度、Wassertein距离
KL散度
KL散度又称相对熵,信息散度,信息增益。KL散度是两个概率分布P和Q差别的非对称性的度量。在经典境况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布。
D K L ( P ∥ Q ) = ∑ i = 1 n P i l o g ( P i Q i ) D_{KL}(P \parallel Q)= \sum_{i=1}^{n}P_i log(\frac{P_i}{Q_i}) DKL(P∥Q)=i=1∑nPilog(QiPi)
JS散度
JS散度是度量两个概率分布的相似度,是基于KL散度的变体,解决了KL散度非对称的问题。
D J S ( P ∥ Q ) = 1 2 D K L ( P ∥ P + Q 2 ) + 1 2 D K L ( Q ∥ P + Q 2 ) D_{JS}(P \parallel Q)=\frac{1}{2} D_{KL}(P \parallel \frac{P+Q}{2}) + \frac{1}{2} D_{KL}(Q \parallel \frac{P+Q}{2}) DJS(P∥Q)=21DKL(P∥2P+Q)+21DKL(Q∥2P+Q)
KL散度和JS散度度量的时候都有一个问题:如果两个分布P,Q距离较远,完全没有重叠的时候,KL散度是没有意义的,在学习的时候,这就意味着在这一点的梯度为0,即梯度消失了。
Wassertrin距离
Wasserstein距离度量的是两个管理分布之间的距离。
W ( P , Q ) = i n f γ ∼ ∏ ( P , Q ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] W(P,Q) = \underset{\gamma \sim \prod (P, Q) }{inf} E_{(x,y) \sim \gamma} \left [ ||x-y|| \right ] W(P,Q)=γ∼∏(P,Q)infE(x,y)∼γ[∣∣x−y∣∣]
其中 ∏ ( P , Q ) \prod (P, Q) ∏(P,Q)是边际分布为 P P P和 Q Q Q的所有可能的联合分布集合。
显式和隐式密度模型
在上一篇文章中介绍的变分自动编码器,之前介绍的深度信念网络都是显式的构建样本的密度函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ),并通过最大似然估计来求解参数,称之为显式密度模型(Explicit Density Model)。
如果只是希望有一个模型能生成符合数据分布 p r ( x ) p_r(x) pr(x)的样本,那么可以不显式地估计出数据分布的密度函数。假设在低维空间 Z Z Z中有一个简单容易采样的分布 p ( z ) p(z) p(z), p ( z ) p(z) p(z)通常为标准多元正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。我们使用神经网络构建一个映射函数 G : Z → X G: Z \rightarrow X G:Z→X称为生成网络。利用神经网络强大的拟合能力,使得 G ( z ) G(z) G(z)服从数据分布 p r ( x ) p_r(x) pr(x)。这种模型就称为隐式密度模型(Implicit Density Model)。所谓隐式模型就是指并不显示地建模 p r ( x ) p_r(x) pr(x),而是建模生成过程。
网络分解与训练
判别网络
隐式密度模型的一个关键是如何确保生成网络产生的样本一定是服从真实的数据分布。既然我们不构建显式密度模型,就无法通过最大似然估计等方法来训练。
生成对抗网络(Generative Adversarial Networks,GAN)是通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布。在生成对抗网络中,有两个网络进行对抗训练。一个是判别网络,目标是尽量准确地判断一个样本是来自于真实数据还是生成网络产生的;另一个是生成网络,目标是尽量生成判别网络无法区分来源的样本。这两个目标相反的网络不断地进行交替训练。当最后收敛时,如果判别网络再也无法判断出一个样本的来源,那么也就等价于生成网络可以生成符合真实数据分布的样本。生成对抗网络的流程图如下图所示:
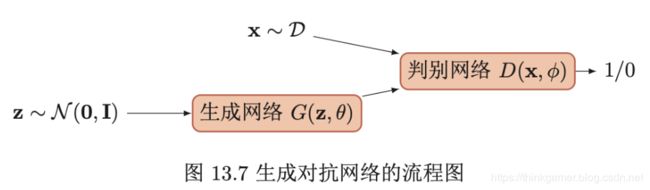
判别网络(Discriminator Network) D ( x , ϕ ) D(x,\phi) D(x,ϕ) 的目标是区分出一个样本 x x x是来自于真实分布 p r ( x ) p_r(x) pr(x)还是来自于生成模型 p θ ( x ) p_{\theta}(x) pθ(x),因此判别网络实际上一个两类分类器。用标签 y = 1 y=1 y=1来表示样本来自于真实分布, y = 0 y=0 y=0表示样本来自模型,判别网络的 D ( x , ϕ ) D(x,\phi) D(x,ϕ)的输出为 x x x属于真实数据分布的概率,即:
p ( y = 1 ∣ x ) = D ( x , ϕ ) p(y=1|x)=D(x, \phi) p(y=1∣x)=D(x,ϕ)
则样本来自模型生成的概率位 p ( y = 0 ∣ x ) = 1 − D ( x , ϕ ) p(y=0|x)=1-D(x, \phi) p(y=0∣x)=1−D(x,ϕ)
给定一个样本 ( x , y ) , y = { 1 , 0 } (x,y),y=\{1,0\} (x,y),y={1,0}表示其是来自于 p r ( x ) p_r(x) pr(x)还是 p θ ( x ) p_{\theta}(x) pθ(x),判别网络的目标函数为最小化交叉熵,即最大化对数函数(公式1-1)。
m i n ϕ = ( E x [ y l o g p ( y = 1 ∣ x ) + ( 1 − y ) l o g p ( y = 0 ∣ x ) ] ) = m a x ϕ ( E x ∼ p r ( x ) [ l o g D ( x , ϕ ) ] + E z ∼ p ( z ) [ l o g ( 1 − D ( G ( z , θ ) , ϕ ) ) ] ) \underset{\phi}{min} = \left ( E_x[y log \,\, p(y=1 | x) + (1-y) log \,\, p(y=0|x) ] \right ) \\ = \underset{\phi}{max} \left ( E_{x\sim p_r(x)} [log \,\, D(x, \phi)] + E_{z\sim p(z)}[ log (1-D(G(z,\theta), \phi))] \right ) ϕmin=(Ex[ylogp(y=1∣x)+(1−y)logp(y=0∣x)])=ϕmax(Ex∼pr(x)[logD(x,ϕ)]+Ez∼p(z)[log(1−D(G(z,θ),ϕ))])
其中 θ , ϕ \theta, \phi θ,ϕ分别是生成网络和判别网络的参数。
生成网络
生成网络(Generator Network) 的目标刚好和判别网络相反,即让判别网络将自己生成的样本判别为真实样本。其目标函数如下(公式1-2):
m a x θ ( E z ∼ p ( z ) [ l o g D ( G ( z , θ ) , ϕ ) ] ) = m i n θ ( E z ∼ p ( z ) [ l o g ( 1 − D ( G ( z , θ ) , ϕ ) ) ] ) \underset{\theta}{max} \left ( E_{z\sim p(z)} [log \,\, D(G(z , \theta), \phi)] \right ) \\ = \underset{\theta}{min} \left ( E_{z\sim p(z)} [log \,\, (1-D(G(z , \theta), \phi))] \right ) θmax(Ez∼p(z)[logD(G(z,θ),ϕ)])=θmin(Ez∼p(z)[log(1−D(G(z,θ),ϕ))])
上面的这两个目标函数是等价的。但是在实际训练时,一般使用前者,因为其梯度性质更好。我们知道,函数 l o g ( x ) , x ∈ ( 0 , 1 ) log(x), x\in (0,1) log(x),x∈(0,1)在 x x x接近1时的梯度要比接近0时的梯度小很多,接近饱和区间。这样,当判别网络 D D D以很高的概率认为生成网络 G G G产生的样本是“假”样本,即 ( 1 − D ( G ( z , θ ) , ϕ ) ) → 1 (1-D(G(z, \theta), \phi)) \rightarrow 1 (1−D(G(z,θ),ϕ))→1。这时目标函数关于 θ \theta θ的梯度反而很小,从而不利于优化。
网络训练
在生成对抗网络的训练过程中,需要平衡两个网络的能力。对于判别网络来说,一开始的判别能力不能太强,否则难以提升生成网络的能力。然后也不能太弱,否则针对他训练的生产网络也不会太好。在训练时需要使用一些技巧,使得在每次迭代中,判别网络臂生成网络的能力强一些,但又不能强太多。
生成对抗网络的训练流程如下所示,每次迭代时,判别网络更新 K K K次而生成网络更新一次,即首先要保证判别网络足够强才能开始训练生成网络。在实践中 K K K是一个超参数,其取值一般取决于具体任务。

DCGAN
DCGAN介绍
生成对抗网络是指一类采用对抗训练方式来进行学习的深度生成模型,其包含的判别网络和生成网络都可以根据不同的生成任务使用不同的网络结构。
在深度卷积生成对抗网络(Dee Convolutional Generative Adversarial Neteorks,DCGAN)中,判别网络是一个传统的深度卷积网络,但使用了带步长的卷积来实现下采样操作,不用最大汇聚(pooling)操作。生成网络使用一个特殊的深度卷积网络来实现,如下图所示,使用微步卷积来生成64x63大小的图像。
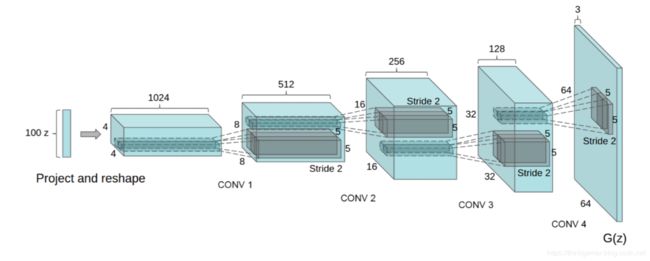
上图中,第一层是全连接层,输入是从均匀分布中随机采样的100维向量 z z z,输出是4x4x1024的向量,重塑为4x4x1024的张量,然后是四层的微步卷积,没有汇聚层。
DCGAN的主要优点是通过一些经验性的网络结构设计使得对抗训练更加稳定。比如:
- (1)使用代步长的卷积(在判别网络中)和微步卷积(在生成网络中)来代替汇聚操作,以免损失信息
- (2)使用批量归一化
- (3)去除卷积层之后的全连接层
- (4)在生成网络中,除了最后一层使用Tanh激活函数外,其余层都使用ReLU函数
- (5)在判别网络中,都适用LeakyReLU激活函数
模型分析
将判别网络和生成网络合并,整个生成对抗网络得整个目标函数看作最小最大化游戏(Minimax Game),表达式如下(1-3):
m i n θ m a x ϕ ( E x ∼ p r ( x ) [ l o g D ( x , ϕ ) ] + E x ∼ p θ ( x ) [ l o g ( 1 − D ( x , ϕ ) ) ] ) \underset{\theta}{min} \, \underset{\phi}{max}\left ( E_{x \sim p_r{(x)}} \left [ log\,\, D(x, \phi) \right ] + E_{x \sim p_{\theta}(x)} \left [ log\,\,(1- D(x, \phi)) \right ] \right ) θminϕmax(Ex∼pr(x)[logD(x,ϕ)]+Ex∼pθ(x)[log(1−D(x,ϕ))])
因为之前提到的生成网络梯度问题,这个最小化最大化形式的目标函数一般用来进行理论分析,并不是实际训练时的目标函数。
假设 p r ( x ) p_r(x) pr(x)和 p θ ( x ) p_{\theta}(x) pθ(x)已知,则最优得判别器为:
D ∗ ( x ) = p r ( x ) p r ( x ) + p θ ( x ) D^*(x) = \frac{p_r(x)}{p_r(x) + p_{\theta}(x)} D∗(x)=pr(x)+pθ(x)pr(x)
将最优得判别器 D ∗ ( x ) D^*(x) D∗(x)代入公式1-3,则目标函数变为(公式1-4):
L ( G ∣ D ∗ ) = E x ∼ p r ( x ) [ l o g D ∗ ( x ) ] + E x ∼ p r ( θ ) [ l o g ( 1 − D ∗ ( x ) ) ] = 2 D J S ( p r ∣ ∣ p θ ) − 2 l o g 2 L(G|D^*) = E_{x \sim p_r{(x)}} \left [ log\,\, D^*(x) \right ] + E_{x \sim p_r{(\theta})} \left [ log\,\,(1- D^*(x)) \right ] \\ = 2D_{JS}(p_r||p_{\theta}) - 2log2 L(G∣D∗)=Ex∼pr(x)[logD∗(x)]+Ex∼pr(θ)[log(1−D∗(x))]=2DJS(pr∣∣pθ)−2log2
其中 D J S D_{JS} DJS为JS散度。
在生成对抗网络中,当判别网络为最优时,生成网络的优化目标是最小化真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ之间得JS散度。当两个分布相同时,JS散度为0,最优生成网络 G ∗ G^* G∗对应得损失为 L ( G ∗ ∣ D ∗ ) = − 2 l o g 2 L(G^*|D^*)=-2log2 L(G∗∣D∗)=−2log2。
然而JS散度的一个问题是:当两个分布没有重叠时,他们之间得JS散度恒等于常数log2。对生成网络来说,目标函数关于参数的梯度为0。
∂ L ( G ∣ D ∗ ) ∂ θ = 0 \frac{ \partial L(G|D^*) }{ \partial \theta} =0 ∂θ∂L(G∣D∗)=0
下图给出了生成对抗网络中的梯度消失问题的示例。当真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ没有重叠,最优的判断网对对所有生成数据得输出都为0, D ∗ ( G ( z , θ ) ) = 0 , ∀ z D^*(G(z, \theta))=0, \forall z D∗(G(z,θ))=0,∀z。因此生成网络得梯度消失。
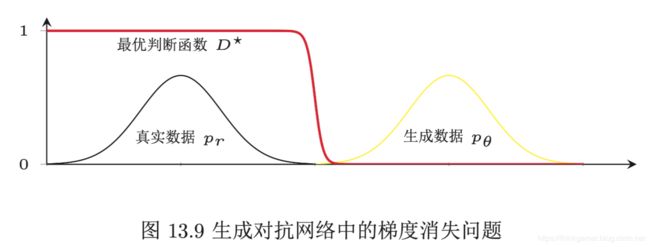
在实际训练生成对抗网络时,我们一般不会将判别网络训练到最优,只进行一步或多步梯度下降,使得生成网络的梯度依然存在。然而,判别网络也不能太差,否则生成网络的梯度为错误的梯度。如何使得判别网络在梯度消失和梯度错误之间取得平衡并不是一件容易的事。
模型坍塌
如果使用公式1-2作为生成网络的目标函数,将最优判断网络 D ∗ D^* D∗代入,得到:
L ′ ( G ∣ D ∗ ) = E x ∼ p θ ( x ) [ l o g D ∗ ( x ) ] = E x ∼ p θ ( x ) [ l o g p r ( x ) p r ( x ) + p θ ( x ) ⋅ p θ ( x ) p θ ( x ) ] = − E x ∼ p θ ( x ) [ l o g p θ ( x ) p r ( x ) ] + E x ∼ p θ ( x ) [ l o g p r ( x ) p r ( x ) + p θ ( x ) ] = − D K L ( p θ ∣ ∣ p r ) + E x ∼ p θ ( x ) [ l o g ( 1 − D ∗ ( x ) ) ] = − D K L ( p θ ∣ ∣ p r ) + 2 D J S ( p r ∣ ∣ p θ ) − 2 l o g 2 − E x ∼ p r ( x ) [ l o g D ∗ ( x ) ] L'(G|D^*) = E_{x \sim p_{\theta}(x)} \left [ log \, D^*(x) \right ] \\ = E_{x \sim p_{\theta}(x)} \left [ log \, \frac {p_r(x)}{p_r(x) + p_{\theta}(x) } \cdot \frac{p_{\theta}(x) }{p_{\theta}(x) } \right ] \\ = - E_{x \sim p_{\theta}(x)}\left [ log \, \frac{p_{\theta}(x)}{p_r(x)} \right ] + E_{x \sim p_{\theta}(x)} \left [ log \, \frac {p_r(x)}{p_r(x) + p_{\theta}(x) } \right ] \\ = -D_{KL}(p_{\theta} || p_r) + E_{x \sim p_{\theta}(x)} \left [ log (1-D^*(x)) \right ] \\ = -D_{KL}(p_{\theta} || p_r) + 2D_{JS}(p_r || p_{\theta})-2log2 - E_{x \sim p_r(x)} \left [ log \, D^* (x) \right ] L′(G∣D∗)=Ex∼pθ(x)[logD∗(x)]=Ex∼pθ(x)[logpr(x)+pθ(x)pr(x)⋅pθ(x)pθ(x)]=−Ex∼pθ(x)[logpr(x)pθ(x)]+Ex∼pθ(x)[logpr(x)+pθ(x)pr(x)]=−DKL(pθ∣∣pr)+Ex∼pθ(x)[log(1−D∗(x))]=−DKL(pθ∣∣pr)+2DJS(pr∣∣pθ)−2log2−Ex∼pr(x)[logD∗(x)]
其中后两项和生成网络无关,因此:
m a x θ L ′ ( G ∣ D ∗ ) = m i n θ D K L ( p θ ∣ ∣ p r ) − 2 D J S ( p r ∣ ∣ p θ ) \underset{ \theta }{ max } L'(G | D^*) =\underset{ \theta }{ min } D_{KL} (p_{\theta} || p_r) - 2D_{JS} (p_r || p_{\theta} ) θmaxL′(G∣D∗)=θminDKL(pθ∣∣pr)−2DJS(pr∣∣pθ)
其中JS散度和 D J S ( p θ ∣ ∣ p r ) ∈ [ 0 , l o g 2 ] D_{JS}(p_{\theta} || p_r) \in [0, log 2] DJS(pθ∣∣pr)∈[0,log2]为有界函数,因此生成网络的目标是为更多的受逆向KL散度 D K L ( p θ ∣ ∣ p r ) D_{KL}(p_{\theta} || p_r) DKL(pθ∣∣pr)影响,使得生成网络更倾向于生成一些更安全的样本,从而造成**模型坍塌(Model Collapse)**问题
前向和逆向KL散度
KL散度是一种非对称的散度,在计算真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ之间得KL散度时,按照顺序不同,有两种KL散度:前向KL散度(Forward KL divergence) D K L ( p r ∣ ∣ p θ ) D_{KL}(p_r || p_{\theta}) DKL(pr∣∣pθ) 和逆向KL散度(Reverse KL divergence) D K L ( p θ ∣ ∣ p r ) D_{KL}(p_{\theta} || p_r) DKL(pθ∣∣pr)
前向和逆向KL散度分别定义为:
D K L ( p r ∣ ∣ p θ ) = ∫ p r ( x ) l o g p r ( x ) p θ ( x ) d x D K L ( p θ ∣ ∣ p r ) = ∫ p θ ( x ) l o g p θ ( x ) p r ( x ) d x D_{KL}(p_r || p_{\theta}) = \int p_r(x) log\, \frac{p_r(x)}{p_{\theta}(x)}dx \\ D_{KL}(p_{\theta} || p_r) = \int p_{\theta}(x) log\, \frac{p_{\theta}(x)}{p_r(x)}dx DKL(pr∣∣pθ)=∫pr(x)logpθ(x)pr(x)dxDKL(pθ∣∣pr)=∫pθ(x)logpr(x)pθ(x)dx
在前向KL散度中:
- (1)当 p r ( x ) → 0 p_r(x) \rightarrow 0 pr(x)→0而 p θ ( x ) > 0 p_{\theta}(x)> 0 pθ(x)>0时, p r ( x ) l o g p r ( x ) p θ ( x ) → 0 p_r(x) log\, \frac{p_r(x)}{p_{\theta}(x)} \rightarrow 0 pr(x)logpθ(x)pr(x)→0。不管 p θ ( x ) p_{\theta}(x) pθ(x)如何取值,都对前向KL散度的计算没有贡献。
- (2)当 p r ( x ) > 0 p_r(x) > 0 pr(x)>0而 p θ ( x ) → 0 p_{\theta}(x) \rightarrow 0 pθ(x)→0时, p r ( x ) l o g p r ( x ) p θ ( x ) → ∞ p_r(x) log\, \frac{p_r(x)}{p_{\theta}(x)} \rightarrow \infty pr(x)logpθ(x)pr(x)→∞。前向KL散度会变得非常大。
因此,前向KL散度会鼓励模型分布 p θ ( x ) p_{\theta}(x) pθ(x)尽可能的覆盖所有真实分布 p r ( x ) > 0 p_r(x)>0 pr(x)>0的点,而不用回避 p r ( x ) ≈ 0 p_r(x)\approx 0 pr(x)≈0的点。
在逆向KL散度中:
- (1)当 p r ( x ) → 0 p_r(x) \rightarrow 0 pr(x)→0而 p θ ( x ) > 0 p_{\theta}(x)> 0 pθ(x)>0时, p θ ( x ) l o g p θ ( x ) p r ( x ) → ∞ p_{\theta}(x) log\, \frac{p_{\theta}(x)}{p_r(x)} \rightarrow \infty pθ(x)logpr(x)pθ(x)→∞。即当 p θ ( x ) p_{\theta}(x) pθ(x)接近于0,而 p θ ( x ) p_{\theta}(x) pθ(x)有一定的密度时,逆向KL散度会变得非常大。
- (2)当 p θ ( x ) → 0 p_{\theta}(x) \rightarrow 0 pθ(x)→0, 不管 p r ( x ) p_r(x) pr(x)如何取值, p θ ( x ) l o g p θ ( x ) p r ( x ) → 0 p_{\theta}(x) log\, \frac{p_{\theta}(x)}{p_r(x)} \rightarrow 0 pθ(x)logpr(x)pθ(x)→0。
因此逆向KL散度会鼓励模型分布 p θ ( x ) p_{\theta}(x) pθ(x)尽可能避开所有真实分布 p r ( x ) ≈ 0 p_r(x)\approx 0 pr(x)≈0的点,而不需要考虑是否覆盖所有分布为 p r ( x ) > 0 p_r(x) > 0 pr(x)>0的点。
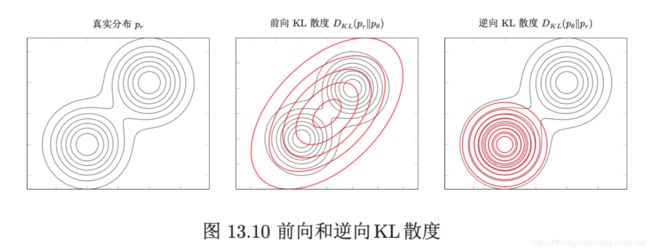
下图给出数据真实分布为一个高斯混合分布,模型分布为一个旦高斯分布时,使用前向和逆向KL散度来进行模型优化的示例,蓝色曲线为真实分布 p r p_r pr的等高线,红色曲线为模型分布 p θ p_{\theta} pθ的等高线。
W-GAN
W-GAN是一种通过使用Wassertein距离替代JS散度来优化训练的生成对抗网络。对于真实分布 p r p_r pr和模型分布 p θ p_{\theta} pθ,他们的1st-wassertein距离为:
W 1 ( p r , p θ ) = i n f γ ∼ ∏ ( P r , P g ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] W^1(p_r,p_{\theta}) = \underset{\gamma \sim \prod (P_r, P_g) }{inf} E_{(x,y) \sim \gamma} \left [ ||x-y|| \right ] W1(pr,pθ)=γ∼∏(Pr,Pg)infE(x,y)∼γ[∣∣x−y∣∣]
其中 ∏ ( P r , P g ) \prod (P_r, P_g) ∏(Pr,Pg)是边际分布为 p r p_r pr和 p θ p_{\theta} pθ的所有可能的联合分布集合。
当两个分布没有重叠或者重叠非常少时,他们之间的KL散度为 + ∞ + \infty +∞,JS散度为log2,并不随着两个分布之间的距离而变化。而1st-wassertein距离可以依然衡量两个没有重叠分布的距离。
W-GAN的目标函数为:
m a x θ E z ∼ p ( z ) [ f ( G ( z , θ ) , ϕ ) ] \underset{\theta}{ max } E_{z \sim p(z)} \left [ f(G(z, \theta), \phi) \right ] θmaxEz∼p(z)[f(G(z,θ),ϕ)]
因为 f ( x , ϕ ) f(x, \phi) f(x,ϕ)为不饱和函数,所以生成网络参数 θ \theta θ的梯度不会消失,理论上解决了原始GAN训练不稳定的问题。并且W-GAN中生成网络的目标函数不再是两个分布的比率,在一定程度上缓解了模型坍塌问题,使得生成的样本具有多样性。
下图给出了W-GAN的训练过程,和原始GAN相比,W-GAN的评价网络最后一层不使用sigmoid函数,损失函数不取对数。

总结
深度生成模型是一种有机地融合神经网络和概率图模型的生成模型,将神经网络作为一个概率分布的逼近器,可以拟合非常复杂的数据分布。
变分自编码器是一个有意义的深度生成模型,可以有效地解决含隐变量的概率模型中后验分布难以估计的问题。
生成对抗网络是一个具有开创意义的深度生成模型,突破了以往的概率模型必须通过最大似然估计来学习参数的限制。DC-GAN是一个生成对抗网络的成功实现,可以生成十分逼真的自然图像。对抗生成网络的训练不稳定问题的一种有效解决方法是W-GAN,通过用 Wassertein 距离替代 JS 散度来进行训练。
虽然深度生成模型取得巨大的成功,但是作为一种无监督模型,其主要的缺点是缺乏有效的客观评价,因此不同模型之间的比较很难客观衡量。


