爬虫基础 -- 用Flask+Redis维护代理池
因为在爬虫的时候经常经常会遇到封IP 的情况,那么使用代理就可以解决这个问题。
池子里面放一些代理,而且需要定期的检查。
互联网上公开了大量的免费代理,而且互联网上也有付费的代理。
代理池的要求:
1.多站抓取,异步检测
2.定时筛选,持续更新
3.提供接口,易于提取
代理池的架构
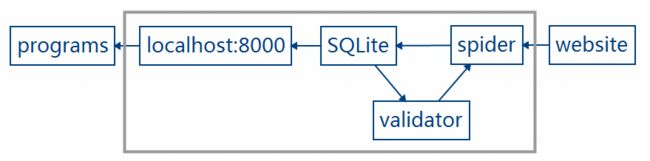
开始搭建代理池。
主要是借鉴 github上Germey的代理池的实现
https://github.com/germey/proxypool
下面看看介绍一下源码。其实我也是看作者的视频学习他的代码的。
def main():
s = Schedule()
s.run()
app.run()
代码在 run.py 中首先实例化了一个 调度器。 并且执行了run()方法。。
s.run() 是运行调度器,和检验,添加,删去代理相关。
app.run() 是启动起来flask框架。提供api接口相关的。实例化一个redisclient对象。并且可以调用redis的相关方法。
先说一下 redis的处理函数:
get() 从队列左侧拿出一个代理
put() 从队列右侧放进去一个代理
pop() 从右侧弹出一个代理
queue_len() 获得队列长度
flush() 清空队列
讲解一下Schedule调度器的实现。
下面的代码是 Schedule调度器的代码:
class Schedule(object):
@staticmethod
def valid_proxy(cycle=VALID_CHECK_CYCLE):
"""
Get half of proxies which in redis
"""
conn = RedisClient()
tester = ValidityTester()
while True:
print('Refreshing ip')
count = int(0.5 * conn.queue_len)
if count == 0:
print('Waiting for adding')
time.sleep(cycle)
continue
raw_proxies = conn.get(count)
tester.set_raw_proxies(raw_proxies)
tester.test()
time.sleep(cycle)
@staticmethod
def check_pool(lower_threshold=POOL_LOWER_THRESHOLD,
upper_threshold=POOL_UPPER_THRESHOLD,
cycle=POOL_LEN_CHECK_CYCLE):
"""
If the number of proxies less than lower_threshold, add proxy
"""
conn = RedisClient()
adder = PoolAdder(upper_threshold)
while True:
if conn.queue_len < lower_threshold:
adder.add_to_queue()
time.sleep(cycle)
def run(self):
print('Ip processing running')
valid_process = Process(target=Schedule.valid_proxy)
check_process = Process(target=Schedule.check_pool)
valid_process.start()
check_process.start()执行了run方法之后,开启了两个进程。
一个是定时检测 代理池中的 ip是否有效,另一个是检测池子中的ip个数是否满足要求。
第一个 方法: 定时检测代理池中的ip是否有效 。
def valid_proxy(cycle=VALID_CHECK_CYCLE): 是定时检测方法。其中的VALID_CHECK_CYCLE 是循环检测的周期间隔。
valid_proxy 方法在实例化连接redis之后,又实例化了一个检测是否有效的一个类。每次取出一半队列长度的代理。
具体的检测过程是在以下代码实现的。(这是一个异步检测。py3.6 )
async def test_single_proxy(self, proxy):
"""
text one proxy, if valid, put them to usable_proxies.
"""
try:
async with aiohttp.ClientSession() as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('Testing', proxy)
async with session.get(self.test_api, proxy=real_proxy, timeout=get_proxy_timeout) as response:
if response.status == 200:
self._conn.put(proxy)
print('Valid proxy', proxy)
except (ProxyConnectionError, TimeoutError, ValueError):
print('Invalid proxy', proxy)
except (ServerDisconnectedError, ClientResponseError,ClientConnectorError) as s:
print(s)
pass第二个 方法 : 检测代理池中的代理ip是否够用。不够的话,就向一些代理网站上取一些代理ip。并且检验有效之后就添加进到代理池。
def add_to_queue(self):
print('PoolAdder is working')
proxy_count = 0
while not self.is_over_threshold():
for callback_label in range(self._crawler.__CrawlFuncCount__):
callback = self._crawler.__CrawlFunc__[callback_label]
raw_proxies = self._crawler.get_raw_proxies(callback)
# test crawled proxies
self._tester.set_raw_proxies(raw_proxies)
self._tester.test()
proxy_count += len(raw_proxies)
if self.is_over_threshold():
print('IP is enough, waiting to be used')
break
if proxy_count == 0:
raise ResourceDepletionError这里的 for callback_label in range(self._crawler.__CrawlFuncCount__): 是一个很厉害的实现。
他将getter.py里的关于得到代理ip的网站的函数放到列表里。然后挨个执行一遍。具体实现如下
"""
元类,在FreeProxyGetter类中加入
__CrawlFunc__和__CrawlFuncCount__
两个参数,分别表示爬虫函数,和爬虫函数的数量。
"""
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)如果还想添加一个网站的抓取。
只要再添加一个crawl_开头的一个方法就好了。