- 1. 基本原理
- 2. 相关代码
- 3. 整体流程
- 4. 初始化中断控制器
- 4.1. LAPIC的创建
- 4.1.1. 整体流程
- 4.1.2. 代码入口
- 4.2. PIC和IOAPIC的创建
- 4.2.1. QEMU
- 4.2.2. 整体流程
- 4.2.3. 入口代码
- 4.2.4. kvm_pic_init(): 虚拟pic(8259A)的初始化
- 4.2.4.1. kvm_io_bus_register_dev(): 在相应的io_bus总线上注册设备
- 4.2.4.2. 三种设备在虚拟bus上的结构
- 4.2.5. kvm_ioapic_init(): ioapic的初始化
- 4.2.6. kvm_setup_default_irq_routing(): 默认中断路由表的初始化
- 4.1. LAPIC的创建
- 5. 中断注入的触发: kvm_set_irq()
- 5.1. 整体流程
- 5.2. 中断触发入口
- 5.3. kvm_irq_map_gsi(): 获取同一个irq对应的所有中断路由项(即设备)
- 5.4. irq_set[i].set(): 调用路由项的触发函数
- 5.4.1. PIC中断触发: kvm_set_pic_irq()
- 5.4.1.1. 整体流程
- 5.4.1.2. pic的触发入口
- 5.4.2. kvm_set_ioapic_irq(): IOAPIC中断触发
- 5.4.2.1. 整体流程
- 5.4.2.2. ioapic的触发入口
- 5.4.2.3. ioapic_service(): 根据RTE构建中断消息发往lapic
- 5.4.2.3.1. kvm_irq_delivery_to_apic(): 投递消息到lapic
- 5.4.3. kvm_set_msi(): MSI中断触发函数
- 5.4.3.1. 整体流程
- 5.4.3.2. msi的触发入口
- 5.4.1. PIC中断触发: kvm_set_pic_irq()
- 5.5. __apic_accept_irq(): LAPIC接收中断
- 6. 中断具体注入过程
- 6.1. 整体流程
- 6.2.
- 7. 中断注入触发的源
- 8. 参考
1. 基本原理
中断虚拟化起始关键在于对中断控制器的虚拟化.
在正常系统中:
中断控制器目前主要有APIC,这种架构下设备控制器通过某种触发方式通知IO APIC,IO APIC根据自身维护的重定向表pci irq routing table格式化出一条中断消息,把中断消息发送给local APIC,local APIC局部于CPU,即每个CPU一个,local APIC 具备传统中断控制器的相关功能以及各个寄存器,中断请求寄存器IRR,中断屏蔽寄存器IMR,中断服务寄存器ISR等.
针对这些关键部件的虚拟化是中断虚拟化的重点。
2. 相关代码

3. 整体流程
整个主要流程:
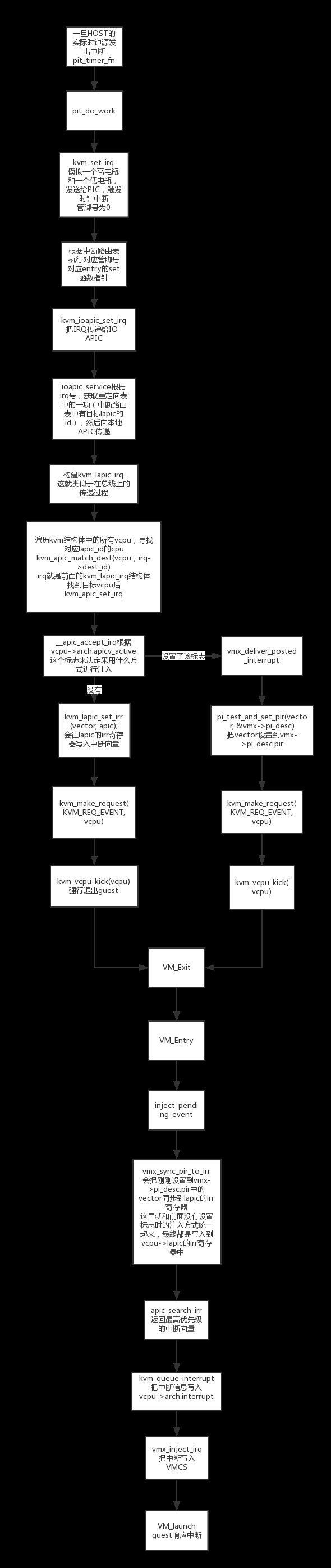
修正: 重定向表中有目标lapic的id
4. 初始化中断控制器
考虑到中断实时性对性能的影响,PIC和IOAPIC的设备模拟主要逻辑!!! 都放到了kvm模块进行实现,每个VCPU的LAPIC则完全!!!放到kvm中进行实现。
i8259控制器和IOAPIC的创建和初始化由qemu和kvm配合完成,包括了2个方面:
- kvm中设备相关数据结构初始化!!!
- qemu中设备模拟的初始化!!!
中断处理的逻辑放在kvm内核模块中进行实现,但设备的模拟呈现还是需要qemu设备模拟器来搞定,最后qemu和kvm一起配合完成快速中断处理的流程。
所以在qemu中也会创建i8259A和ioapic
4.1. LAPIC的创建
由于APIC Timer设备实际就是lapic的一个功能,所以在创建lapic设备同时,也就辅助设置了。
不存在qemu侧流程
4.1.1. 整体流程
kvm_arch_vcpu_create() // vcpu创建中创建lapic
├─ kvm_create_lapic() // lapic创建入口
| ├─ kzalloc(sizeof(*apic), GFP_KERNEL_ACCOUNT); // 如果irqchip在kvm中实现, 则直接返回, 不执行任何动作
| ├─ vcpu->arch.apic = apic; //
| ├─ apic->regs = (void *)get_zeroed_page(GFP_KERNEL_ACCOUNT); //
| ├─ hrtimer_init(&apic->lapic_timer.timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_HARD); //初始化hrtimer定时器
| ├─ apic->lapic_timer.timer.function = apic_timer_fn; // hrtimer定时器回调函数, 即APIC Timer设备产生中断的函数
| ├─ apic->lapic_timer.timer_advance_ns; // advanced timer
| └─ kvm_iodevice_init(&apic->dev, &apic_mmio_ops); //
├─ kvm_vcpu_reset(vcpu, false); // 对vcpu结构进行初始化
| ├─ kvm_lapic_reset(vcpu, init_event); // 设置寄存器的值为默认值4.1.2. 代码入口
lapic是每个vcpu一个, 所以在创建vcpu流程中创建了lapic
int kvm_create_lapic(struct kvm_vcpu *vcpu, int timer_advance_ns)
{
struct kvm_lapic *apic;
ASSERT(vcpu != NULL);
// 分配apic结构体
apic = kzalloc(sizeof(*apic), GFP_KERNEL_ACCOUNT);
if (!apic)
goto nomem;
vcpu->arch.apic = apic;
apic->regs = (void *)get_zeroed_page(GFP_KERNEL_ACCOUNT);
if (!apic->regs) {
printk(KERN_ERR "malloc apic regs error for vcpu %x\n",
vcpu->vcpu_id);
goto nomem_free_apic;
}
apic->vcpu = vcpu;
// 建立hrtimer定时器, 回调函数 apic_timer_fn
hrtimer_init(&apic->lapic_timer.timer, CLOCK_MONOTONIC,
HRTIMER_MODE_ABS_HARD);
// hrtimer定时器回调函数, 即APIC Timer设备产生中断的函数
apic->lapic_timer.timer.function = apic_timer_fn;
if (timer_advance_ns == -1) {
apic->lapic_timer.timer_advance_ns = LAPIC_TIMER_ADVANCE_NS_INIT;
lapic_timer_advance_dynamic = true;
} else {
apic->lapic_timer.timer_advance_ns = timer_advance_ns;
lapic_timer_advance_dynamic = false;
}
/*
* APIC is created enabled. This will prevent kvm_lapic_set_base from
* thinking that APIC state has changed.
*/
vcpu->arch.apic_base = MSR_IA32_APICBASE_ENABLE;
static_key_slow_inc(&apic_sw_disabled.key); /* sw disabled at reset */
kvm_iodevice_init(&apic->dev, &apic_mmio_ops);
return 0;
nomem_free_apic:
kfree(apic);
vcpu->arch.apic = NULL;
nomem:
return -ENOMEM;
}其中hrtimer_init是创建了一个时钟定时器,用来实现时钟的模拟
因为APIC Timer设备实际就是lapic的一个功能,所以在创建lapic设备同时创建了。
然后初始化APIC Timer设备产生中断的函数,实际就是定时器回调函数。
4.2. PIC和IOAPIC的创建
4.2.1. QEMU
qemu代码中中断控制器的kvm内核初始化流程为:
configure_accelerator
|--> accel_init_machine
|--> kvm_init
|--> kvm_irqchip_create
|--> kvm_vm_ioctl(s, KVM_CREATE_IRQCHIP)
|--> kvm_init_irq_routing
// kvm-all.c/kvm_init/kvm_irqchip_create
kvm_vm_ioctl(s, KVM_CREATE_IRQCHIP)qemu通过kvm的ioctl命令KVM_CREATE_IRQCHIP调用到kvm内核模块中,在内核模块中创建和初始化PIC/IOAPIC设备(创建设备对应的数据结构并将设备注册到总线上)。
4.2.2. 整体流程
kvm_vm_ioctl() // vm ioctl的入口
├─ kvm_arch_vm_ioctl()
| ├─ irqchip_in_kernel(kvm) // 如果irqchip在kvm中实现, 则直接返回, 不执行任何动作
| ├─ kvm_pic_init() // pic创建, 8259
| | ├─ struct kvm_pic *s = kzalloc(sizeof(struct kvm_pic), GFP_KERNEL_ACCOUNT); // 创建kvm_pic结构
| | ├─ kvm_iodevice_init(&s->dev_master, &picdev_master_ops); // 注册master的IO端口读写函数
| | ├─ kvm_iodevice_init(&s->dev_slave, &picdev_slave_ops); // 注册slave的IO端口读写函数
| | ├─ kvm_iodevice_init(&s->dev_eclr, &picdev_eclr_ops); // 注册eclr的IO端口读写函数
| | ├─ kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0x20, 2, &s->dev_master); // 注册了PIO型的bus访问形式;另一种IO形式为MMIO;
| | ├─ kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0xa0, 2, &s->dev_slave); // 注册了PIO型的bus访问形式;另一种IO形式为MMIO;
| | ├─ kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0x4d0, 2, &s->dev_eclr); // 注册了PIO型的bus访问形式;另一种IO形式为MMIO;
| | └─ kvm->arch.vpic = s; // 将s赋值给kvm->arch.vpic
| ├─ kvm_ioapic_init() // ioapic的初始化
| | ├─ struct kvm_ioapic *ioapic = kzalloc(sizeof(struct kvm_ioapic), GFP_KERNEL_ACCOUNT); // 创建kvm_pic结构
| ├─ kvm_setup_default_irq_routing(); // 设置默认的irq路由表
| | └─ kvm_set_irq_routing(); //
| | ├─ kzalloc(struct_size(new, map, nr_rt_entries), GFP_KERNEL_ACCOUNT); // 为中断路由表分配空间
| | ├─ for (i = 0; i < nr; ++i) // 循环默认的24个路由项
| | ├─ kzalloc(sizeof(*e), GFP_KERNEL_ACCOUNT); // 为每个中断路由项分配空间
| | ├─ setup_routing_entry(kvm, new, e, ue) // 设置路由项
| | | ├─ kvm_set_routing_entry(kvm, e, ue);; // 设置路由项的set方法
| | | └─ hlist_add_head(&e->link, &rt->map[e->gsi]); // 设置gsi对应的哈希链表
| | ├─ rcu_assign_pointer(kvm->irq_routing, new); // 设置虚拟机中断路由表
| | ├─ kvm_irq_routing_update(kvm); //
| | └─ kvm_arch_irq_routing_update(kvm); //
| └─ kvm->arch.irqchip_mode = KVM_IRQCHIP_KERNEL; // irqchip为kernel模式, 即在kernel中实现4.2.3. 入口代码
case KVM_CREATE_IRQCHIP: {
mutex_lock(&kvm->lock);
r = -EEXIST;
// 如果irqchip在kvm中实现, 则不用创建
if (irqchip_in_kernel(kvm))
goto create_irqchip_unlock;
r = -EINVAL;
if (kvm->created_vcpus)
goto create_irqchip_unlock;
// 主要过程, 是8259A pic初始化
r = kvm_pic_init(kvm);
if (r)
goto create_irqchip_unlock;
// ioapic的初始化
r = kvm_ioapic_init(kvm);
if (r) {
kvm_pic_destroy(kvm);
goto create_irqchip_unlock;
}
// 建立默认中断路由表
r = kvm_setup_default_irq_routing(kvm);
if (r) {
kvm_ioapic_destroy(kvm);
kvm_pic_destroy(kvm);
goto create_irqchip_unlock;
}
/* Write kvm->irq_routing before enabling irqchip_in_kernel. */
smp_wmb();
// irq属于内核实现
kvm->arch.irqchip_mode = KVM_IRQCHIP_KERNEL;
create_irqchip_unlock:
mutex_unlock(&kvm->lock);
break;
}4.2.4. kvm_pic_init(): 虚拟pic(8259A)的初始化
arch/x86/kvm/i8259.c
// arch/x86/kvm/i8259.c
int kvm_pic_init(struct kvm *kvm)
{
struct kvm_pic *s;
int ret;
// 分配 kvm_pic 结构体
s = kzalloc(sizeof(struct kvm_pic), GFP_KERNEL_ACCOUNT);
if (!s)
return -ENOMEM;
spin_lock_init(&s->lock);
// 该pic所属的kvm虚拟机
s->kvm = kvm;
s->pics[0].elcr_mask = 0xf8;
s->pics[1].elcr_mask = 0xde;
s->pics[0].pics_state = s;
s->pics[1].pics_state = s;
/*
* Initialize PIO device
*/
// 注册master的IO端口读写函数
kvm_iodevice_init(&s->dev_master, &picdev_master_ops);
kvm_iodevice_init(&s->dev_slave, &picdev_slave_ops);
kvm_iodevice_init(&s->dev_eclr, &picdev_eclr_ops);
mutex_lock(&kvm->slots_lock);
// 注册了PIO型的bus访问形式;另一种IO形式为MMIO;
ret = kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0x20, 2,
&s->dev_master);
if (ret < 0)
goto fail_unlock;
// 注册PIO类型bus的访问
ret = kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0xa0, 2, &s->dev_slave);
if (ret < 0)
goto fail_unreg_2;
// 注册PIO类型bus的访问
ret = kvm_io_bus_register_dev(kvm, KVM_PIO_BUS, 0x4d0, 2, &s->dev_eclr);
if (ret < 0)
goto fail_unreg_1;
mutex_unlock(&kvm->slots_lock);
kvm->arch.vpic = s;
return 0;
fail_unreg_1:
kvm_io_bus_unregister_dev(kvm, KVM_PIO_BUS, &s->dev_slave);
fail_unreg_2:
kvm_io_bus_unregister_dev(kvm, KVM_PIO_BUS, &s->dev_master);
fail_unlock:
mutex_unlock(&kvm->slots_lock);
kfree(s);
return ret;
}4.2.4.1. kvm_io_bus_register_dev(): 在相应的io_bus总线上注册设备
8259A PIC属于PIO访问类型.
int kvm_io_bus_register_dev(struct kvm *kvm, enum kvm_bus bus_idx, gpa_t addr,
int len, struct kvm_io_device *dev)
{
int i;
struct kvm_io_bus *new_bus, *bus;
struct kvm_io_range range;
// 获取io_bus总线
bus = kvm_get_bus(kvm, bus_idx);
if (!bus)
return -ENOMEM;
/* exclude ioeventfd which is limited by maximum fd */
if (bus->dev_count - bus->ioeventfd_count > NR_IOBUS_DEVS - 1)
return -ENOSPC;
// 分配新的io_bus
new_bus = kmalloc(struct_size(bus, range, bus->dev_count + 1),
GFP_KERNEL_ACCOUNT);
if (!new_bus)
return -ENOMEM;
range = (struct kvm_io_range) {
.addr = addr,
.len = len,
.dev = dev,
};
for (i = 0; i < bus->dev_count; i++)
if (kvm_io_bus_cmp(&bus->range[i], &range) > 0)
break;
memcpy(new_bus, bus, sizeof(*bus) + i * sizeof(struct kvm_io_range));
new_bus->dev_count++;
new_bus->range[i] = range;
memcpy(new_bus->range + i + 1, bus->range + i,
(bus->dev_count - i) * sizeof(struct kvm_io_range));
rcu_assign_pointer(kvm->buses[bus_idx], new_bus);
synchronize_srcu_expedited(&kvm->srcu);
kfree(bus);
return 0;
}4.2.4.2. 三种设备在虚拟bus上的结构
虚拟bus总线结构如下, 注意IO端口地址与设备读写函数的关联
每个kvm_io_device的设备都有对应的读写函数
4.2.5. kvm_ioapic_init(): ioapic的初始化
int kvm_ioapic_init(struct kvm *kvm)
{
struct kvm_ioapic *ioapic;
int ret;
// 分配 kmv_ioapic 结构体
ioapic = kzalloc(sizeof(struct kvm_ioapic), GFP_KERNEL_ACCOUNT);
if (!ioapic)
return -ENOMEM;
spin_lock_init(&ioapic->lock);
//
INIT_DELAYED_WORK(&ioapic->eoi_inject, kvm_ioapic_eoi_inject_work);
kvm->arch.vioapic = ioapic;
// 重置ioapic
kvm_ioapic_reset(ioapic);
//
kvm_iodevice_init(&ioapic->dev, &ioapic_mmio_ops);
ioapic->kvm = kvm;
mutex_lock(&kvm->slots_lock);
ret = kvm_io_bus_register_dev(kvm, KVM_MMIO_BUS, ioapic->base_address,
IOAPIC_MEM_LENGTH, &ioapic->dev);
mutex_unlock(&kvm->slots_lock);
if (ret < 0) {
kvm->arch.vioapic = NULL;
kfree(ioapic);
}
return ret;
}在MMIO_BUS上注册了ioapic设备

4.2.6. kvm_setup_default_irq_routing(): 默认中断路由表的初始化
中断路由表的初始化通过kvm_setup_default_irq_routing函数实现,
// 默认有24个表项
static const struct kvm_irq_routing_entry default_routing[] = {
ROUTING_ENTRY2(0), ROUTING_ENTRY2(1),
ROUTING_ENTRY2(2), ROUTING_ENTRY2(3),
ROUTING_ENTRY2(4), ROUTING_ENTRY2(5),
ROUTING_ENTRY2(6), ROUTING_ENTRY2(7),
ROUTING_ENTRY2(8), ROUTING_ENTRY2(9),
ROUTING_ENTRY2(10), ROUTING_ENTRY2(11),
ROUTING_ENTRY2(12), ROUTING_ENTRY2(13),
ROUTING_ENTRY2(14), ROUTING_ENTRY2(15),
ROUTING_ENTRY1(16), ROUTING_ENTRY1(17),
ROUTING_ENTRY1(18), ROUTING_ENTRY1(19),
ROUTING_ENTRY1(20), ROUTING_ENTRY1(21),
ROUTING_ENTRY1(22), ROUTING_ENTRY1(23),
};
int kvm_setup_default_irq_routing(struct kvm *kvm)
{
return kvm_set_irq_routing(kvm, default_routing,
ARRAY_SIZE(default_routing), 0);
}首个参数kvm指定特定的虚拟机,后面default_routing是一个全局的kvm_irq_routing_entry数组,一共24项,该数组没别的作用,就是初始化kvm_irq_routing_table路由表
看一下这个表项宏:
#define IOAPIC_ROUTING_ENTRY(irq) \
{ .gsi = irq, .type = KVM_IRQ_ROUTING_IRQCHIP, \
.u.irqchip = { .irqchip = KVM_IRQCHIP_IOAPIC, .pin = (irq) } }
#define ROUTING_ENTRY1(irq) IOAPIC_ROUTING_ENTRY(irq)注意看这个结构体, kvm_irq_routing_entry, 不是kvm_kernel_irq_routing_entry
这是初始化default_routing的一个关键宏,每一项都是通过该宏传递irq号(0-23)64位下是0-47, 可见
- gsi就是irq号;
- type是
KVM_IRQ_ROUTING_IRQCHIP, irq芯片, 而非MSI. - irqchip中:
- irqchip指明芯片, 有三种, pic master、pic slave和ioapic, 这里是ioapic
- pin是引脚号, 等于irq
所以这里的默认中断路由项, 一共24项, 全部是芯片类型(非MSI), 而且是ioapic, gsi和引脚都是0-24
看kvm_set_irq_routing,
int kvm_set_irq_routing(struct kvm *kvm,
const struct kvm_irq_routing_entry *ue,
unsigned nr,
unsigned flags)
{
// 路由表
struct kvm_irq_routing_table *new, *old;
// 路由表项
struct kvm_kernel_irq_routing_entry *e;
u32 i, j, nr_rt_entries = 0;
int r;
/*正常情况下,nr_rt_entries=nr*/
// 这里是 24
for (i = 0; i < nr; ++i) {
if (ue[i].gsi >= KVM_MAX_IRQ_ROUTES)
return -EINVAL;
nr_rt_entries = max(nr_rt_entries, ue[i].gsi);
}
nr_rt_entries += 1;
/* 为中断路由表申请空间 */
new = kzalloc(struct_size(new, map, nr_rt_entries), GFP_KERNEL_ACCOUNT);
if (!new)
return -ENOMEM;
/* 设置路由表的表项数目 */
new->nr_rt_entries = nr_rt_entries;
// 初始化路由表的每个芯片的每个引脚为GSI号, 为-1, 不再使用
for (i = 0; i < KVM_NR_IRQCHIPS; i++)
for (j = 0; j < KVM_IRQCHIP_NUM_PINS; j++)
new->chip[i][j] = -1;
/*初始化每一个路由项*/
for (i = 0; i < nr; ++i) {
r = -ENOMEM;
// 为每个路由项申请空间
e = kzalloc(sizeof(*e), GFP_KERNEL_ACCOUNT);
if (!e)
goto out;
r = -EINVAL;
switch (ue->type) {
// MSI类型的中断
case KVM_IRQ_ROUTING_MSI:
if (ue->flags & ~KVM_MSI_VALID_DEVID)
goto free_entry;
break;
default:
if (ue->flags)
goto free_entry;
break;
}
// 设置每一个路由项
r = setup_routing_entry(kvm, new, e, ue);
if (r)
goto free_entry;
// 到下一项
++ue;
}
mutex_lock(&kvm->irq_lock);
old = rcu_dereference_protected(kvm->irq_routing, 1);
// 更新虚拟机路由表, 设置虚拟机中断路由表为new
rcu_assign_pointer(kvm->irq_routing, new);
kvm_irq_routing_update(kvm);
kvm_arch_irq_routing_update(kvm);
mutex_unlock(&kvm->irq_lock);
kvm_arch_post_irq_routing_update(kvm);
synchronize_srcu_expedited(&kvm->irq_srcu);
/*释放old*/
new = old;
r = 0;
goto out;
free_entry:
kfree(e);
out:
free_irq_routing_table(new);
return r;
}所以实际上,回到函数中nr_rt_entries就是数组中项数,接着为kvm_irq_routing_table分配空间,注意分配的空间包含三部分:
kvm_irq_routing_table结构、map- nr个
kvm_kernel_irq_routing_entry
所以kvm_irq_routing_table的大小是和全局数组的大小一样的。
整个结构如下图所示
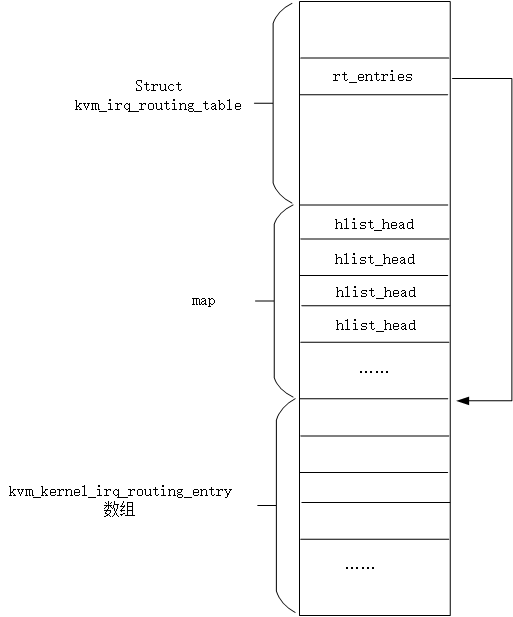
根据上图就可以理解new->rt_entries = (void *)&new->map[nr_rt_entries];这行代码的含义. (注, 新代码已经不是这样, 但是这部分内容保留, 便于了解发展演进)
接下来是对table的chip数组做初始化,这里初始化为-1.
接下来就是一个循环,对每一个中断路由项做初始化,该过程是通过setup_routing_entry函数实现的,这里看下该函数
static int setup_routing_entry(struct kvm *kvm,
struct kvm_irq_routing_table *rt,
struct kvm_kernel_irq_routing_entry *e,
const struct kvm_irq_routing_entry *ue)
{
struct kvm_kernel_irq_routing_entry *ei;
int r;
// 获取到这个路由项的gsi号
u32 gsi = array_index_nospec(ue->gsi, KVM_MAX_IRQ_ROUTES);
/*
* Do not allow GSI to be mapped to the same irqchip more than once.
* Allow only one to one mapping between GSI and non-irqchip routing.
*/
// 遍历这个gsi对应的路由项链表
hlist_for_each_entry(ei, &rt->map[gsi], link)
// 如果不是芯片
if (ei->type != KVM_IRQ_ROUTING_IRQCHIP ||
ue->type != KVM_IRQ_ROUTING_IRQCHIP ||
ue->u.irqchip.irqchip == ei->irqchip.irqchip)
return -EINVAL;
// 路由项的gsi
e->gsi = gsi;
// 路由项的类型
e->type = ue->type;
// 设置该路由项的set方法
r = kvm_set_routing_entry(kvm, e, ue);
if (r)
return r;
// irq芯片, 而非MSI时候
if (e->type == KVM_IRQ_ROUTING_IRQCHIP)
// 设置路由表的chip. 即引脚号
rt->chip[e->irqchip.irqchip][e->irqchip.pin] = e->gsi;
// 添加到路由表的哈希链表
hlist_add_head(&e->link, &rt->map[e->gsi]);
return 0;
}-
之前的初始化过程我们已经看见了,
.type为KVM_IRQ_ROUTING_IRQCHIP,所以这里实际上就是把e->gsi = ue->gsi; e->type = ue->type;. -
然后调用了
kvm_set_routing_entry,该函数中主要是设置了kvm_kernel_irq_routing_entry中的set函数
- IOAPIC的话设置的是
kvm_set_ioapic_irq函数, - pic的话设置
kvm_set_pic_irq函数 - MSI中断消息系统的中断触发函数
kvm_set_msi
-
然后设置irqchip的类型和管脚,对于IOAPIC也是直接复制过来,PIC由于管脚计算是
irq%8,所以这里需要加上8的偏移。之后设置table的chip为gis号。 -
最后就把
kvm_kernel_irq_routing_entry以gsi号位索引,加入到了map数组中对应的哈希链表中。
int kvm_set_routing_entry(struct kvm *kvm,
struct kvm_kernel_irq_routing_entry *e,
const struct kvm_irq_routing_entry *ue)
{
/* We can't check irqchip_in_kernel() here as some callers are
* currently inititalizing the irqchip. Other callers should therefore
* check kvm_arch_can_set_irq_routing() before calling this function.
*/
switch (ue->type) {
// 芯片类型
case KVM_IRQ_ROUTING_IRQCHIP:
if (irqchip_split(kvm))
return -EINVAL;
e->irqchip.pin = ue->u.irqchip.pin;
switch (ue->u.irqchip.irqchip) {
// pic slave, 注意没有break
case KVM_IRQCHIP_PIC_SLAVE:
e->irqchip.pin += PIC_NUM_PINS / 2;
/* fall through */
// pic master
case KVM_IRQCHIP_PIC_MASTER:
if (ue->u.irqchip.pin >= PIC_NUM_PINS / 2)
return -EINVAL;
// PIC的 set方法
e->set = kvm_set_pic_irq;
break;
// ioapic
case KVM_IRQCHIP_IOAPIC:
if (ue->u.irqchip.pin >= KVM_IOAPIC_NUM_PINS)
return -EINVAL;
// ioapic的 set 方法
e->set = kvm_set_ioapic_irq;
break;
default:
return -EINVAL;
}
e->irqchip.irqchip = ue->u.irqchip.irqchip;
break;
// MSI类型
case KVM_IRQ_ROUTING_MSI:
// MSI的set方法
e->set = kvm_set_msi;
e->msi.address_lo = ue->u.msi.address_lo;
e->msi.address_hi = ue->u.msi.address_hi;
e->msi.data = ue->u.msi.data;
if (kvm_msi_route_invalid(kvm, e))
return -EINVAL;
break;
// HV SINT类型, 不懂
case KVM_IRQ_ROUTING_HV_SINT:
e->set = kvm_hv_set_sint;
e->hv_sint.vcpu = ue->u.hv_sint.vcpu;
e->hv_sint.sint = ue->u.hv_sint.sint;
break;
default:
return -EINVAL;
}
return 0;
}5. 中断注入的触发: kvm_set_irq()
中断注入在KVM内部流程起始于一个函数kvm_set_irq
5.1. 整体流程
kvm_set_irq() // 中断触发入口
├─ kvm_irq_map_gsi() // 获取同一个irq注册的所有中断路由项
├─ while() { // 遍历中断路由项
├─ irq_set[i].set() // 调用对应路由实体的触发函数
└─ } // 遍历得到的中断路由项5.2. 中断触发入口
/*
* Return value:
* < 0 Interrupt was ignored (masked or not delivered for other reasons)
* = 0 Interrupt was coalesced (previous irq is still pending)
* > 0 Number of CPUs interrupt was delivered to
*/
int kvm_set_irq(struct kvm *kvm, int irq_source_id, u32 irq, int level,
bool line_status)
{
// 因为一共3个芯片, 每个芯片24个引脚, 也就是意味着同一个irq的路由项最多3个
struct kvm_kernel_irq_routing_entry irq_set[KVM_NR_IRQCHIPS];
int ret = -1, i, idx;
trace_kvm_set_irq(irq, level, irq_source_id);
/* Not possible to detect if the guest uses the PIC or the
* IOAPIC. So set the bit in both. The guest will ignore
* writes to the unused one.
*/
idx = srcu_read_lock(&kvm->irq_srcu);
// 获取同一个irq注册的所有中断路由项, 存于irq_set, 返回数量
i = kvm_irq_map_gsi(kvm, irq_set, irq);
srcu_read_unlock(&kvm->irq_srcu, idx);
/* 依次调用同一个irq上的所有芯片的set方法 */
while (i--) {
int r;
// 调用对应路由实体的触发函数
r = irq_set[i].set(&irq_set[i], kvm, irq_source_id, level,
line_status);
if (r < 0)
continue;
ret = r + ((ret < 0) ? 0 : ret);
}
return ret;
}各个参数的意思:
- kvm指定特定的虚拟机
irq_source_id是中断源ID,一般有KVM_USERSPACE_IRQ_SOURCE_ID和KVM_IRQFD_RESAMPLE_IRQ_SOURCE_ID, 对于KVM设备我们都会申请一个中断资源ID,注册KVM IO设备时申请的- irq是全局的中断号,这个是转化GSI之前的,比如时钟是0号,这里就是0,而不是32
- level指定高低电平,需要注意的是,针对边沿触发,需要两个电平触发来模拟,先高电平再低电平。
5.3. kvm_irq_map_gsi(): 获取同一个irq对应的所有中断路由项(即设备)
回到函数中,首先要收集的是同一irq上注册的所有的设备信息,这主要在于irq共享的情况,非共享的情况下最多就一个。
设备信息抽象成一个kvm_kernel_irq_routing_entry,这里临时放到irq_set数组中。
int kvm_irq_map_gsi(struct kvm *kvm,
struct kvm_kernel_irq_routing_entry *entries, int gsi)
{
struct kvm_irq_routing_table *irq_rt;
struct kvm_kernel_irq_routing_entry *e;
int n = 0;
// 得到中断路由表
irq_rt = srcu_dereference_check(kvm->irq_routing, &kvm->irq_srcu,
lockdep_is_held(&kvm->irq_lock));
if (irq_rt && gsi < irq_rt->nr_rt_entries) {
// 提取中断路由表中对应的中断路由实体,map[gsi]是一个对应中断的路由实体表头结点
// 这里遍历它能够得到所有对应的路由实体
hlist_for_each_entry(e, &irq_rt->map[gsi], link) {
entries[n] = *e;
++n;
}
}
return n;
}5.4. irq_set[i].set(): 调用路由项的触发函数
然后对于数组中的每个元素,调用其set方法
- 在传统pic情况下,是
kvm_set_pic_irq - 目前大都是APIC架构,因此set方法基本都是
kvm_set_ioapic_irq - MSI中断消息系统的中断触发函数
kvm_set_msi.
5.4.1. PIC中断触发: kvm_set_pic_irq()
5.4.1.1. 整体流程
kvm_set_pic_irq() // pic的中断触发入口
├─ struct kvm_pic *pic = kvm->arch.vpic; // 获取虚拟机的pic
└─ kvm_pic_set_irq()
| ├─ irq_level = __kvm_irq_line_state(); // 获取电平
| └─ ioapic_set_irq() //
| | ├─ u32 mask = 1 << irq; // irq对应的位
| | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | ├─ edge = (entry.fields.trig_mode == IOAPIC_EDGE_TRIG); // 判断触发方式, 是否边沿触发
| | ├─ ioapic->irr &= ~mask; // 低电平时, 表明边沿触发第二次触发, 清理irr中相应的irq位, 直接返回, 说明模拟情况下电平触发只在高电平触发
| | ├─ old_irr = ioapic->irr; // 保存原有irr寄存器
| | ├─ ioapic->irr |= mask; // irr寄存器相应位置位
| | └─ ioapic_service(); // 将s赋值给kvm->arch.vpic
| | | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | | ├─ irqe.XXX = XXX // 构建中断消息, 对应kvm_lapic_irq
| | | ├─ kvm_irq_delivery_to_apic(); // 将中断消息投递到lapic
| | | | ├─ //
| | | | └─ kvm_apic_set_irq(); //
| | | └─ entry->fields.remote_irr = 1; // 投递成功且电平触发模式5.4.1.2. pic的触发入口
static int kvm_set_pic_irq(struct kvm_kernel_irq_routing_entry *e,
struct kvm *kvm, int irq_source_id, int level,
bool line_status)
{
struct kvm_pic *pic = kvm->arch.vpic;
return kvm_pic_set_irq(pic, e->irqchip.pin, irq_source_id, level);
}对于PIC来说
它主要是设置kvm里面的虚拟中断控制器结构体struct kvm_pic完成虚拟中断控制器的设置。如果是边缘触发,需要触发电平先1再0,完成一个正常的中断模拟。
5.4.2. kvm_set_ioapic_irq(): IOAPIC中断触发
5.4.2.1. 整体流程
kvm_set_ioapic_irq() // ioapic的中断触发入口
├─ struct kvm_ioapic *ioapic = kvm->arch.vioapic; // 获取虚拟机的ioapic
└─ kvm_ioapic_set_irq()
| ├─ irq_level = __kvm_irq_line_state(); // 获取电平
| └─ ioapic_set_irq() //
| | ├─ u32 mask = 1 << irq; // irq对应的位
| | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | ├─ edge = (entry.fields.trig_mode == IOAPIC_EDGE_TRIG); // 判断触发方式, 是否边沿触发
| | ├─ ioapic->irr &= ~mask; // 低电平时, 表明边沿触发第二次触发, 清理irr中相应的irq位, 直接返回, 说明模拟情况下电平触发只在高电平触发
| | ├─ old_irr = ioapic->irr; // 保存原有irr寄存器
| | ├─ ioapic->irr |= mask; // irr寄存器相应位置位
| | └─ ioapic_service(); // 将s赋值给kvm->arch.vpic
| | | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | | ├─ irqe.XXX = XXX // 构建中断消息, 对应kvm_lapic_irq
| | | ├─ kvm_irq_delivery_to_apic(); // 将中断消息投递到lapic
| | | | ├─ //
| | | | └─ kvm_apic_set_irq(); //
| | | └─ entry->fields.remote_irr = 1; // 投递成功且电平触发模式对于IOAPIC来说, 整个流程是先检查IOAPIC状态,如果符合注入条件,则组建中断结构体,发送到指定VCPU的LAPIC,设置LAPIC的寄存器,完成虚拟中断控制器设置。
5.4.2.2. ioapic的触发入口
static int kvm_set_ioapic_irq(struct kvm_kernel_irq_routing_entry *e,
struct kvm *kvm, int irq_source_id, int level,
bool line_status)
{
// 获取该虚拟机的ioapic
struct kvm_ioapic *ioapic = kvm->arch.vioapic;
return kvm_ioapic_set_irq(ioapic, e->irqchip.pin, irq_source_id, level,
line_status);
}
int kvm_ioapic_set_irq(struct kvm_ioapic *ioapic, int irq, int irq_source_id,
int level, bool line_status)
{
int ret, irq_level;
BUG_ON(irq < 0 || irq >= IOAPIC_NUM_PINS);
spin_lock(&ioapic->lock);
/*得到请求电平*/
irq_level = __kvm_irq_line_state(&ioapic->irq_states[irq],
irq_source_id, level);
// ioapic中断触发
ret = ioapic_set_irq(ioapic, irq, irq_level, line_status);
spin_unlock(&ioapic->lock);
return ret;
}
static int ioapic_set_irq(struct kvm_ioapic *ioapic, unsigned int irq,
int irq_level, bool line_status)
{
union kvm_ioapic_redirect_entry entry;
// irq对应的位
u32 mask = 1 << irq;
u32 old_irr;
int edge, ret;
// 该irq对应的ioapic的重定向表项, 即RTE
entry = ioapic->redirtbl[irq];
/*判断触发方式*/
edge = (entry.fields.trig_mode == IOAPIC_EDGE_TRIG);
// 如果低电平, 表明是模拟边沿触发的第二次触发
// 清理irr对应位后直接返回
// 说明电平触发只是在high电平触发
if (!irq_level) {
// 第二次边沿触发, 清理该irq位
ioapic->irr &= ~mask;
ret = 1;
// 直接返回
goto out;
}
// 往下表明是第一次边沿触发或者电平触发, 都是高电平
/*
* AMD SVM AVIC accelerate EOI write and do not trap,
* in-kernel IOAPIC will not be able to receive the EOI.
* In this case, we do lazy update of the pending EOI when
* trying to set IOAPIC irq.
*/
if (kvm_apicv_activated(ioapic->kvm))
ioapic_lazy_update_eoi(ioapic, irq);
/*
* Return 0 for coalesced interrupts; for edge-triggered interrupts,
* this only happens if a previous edge has not been delivered due
* to masking. For level interrupts, the remote_irr field tells
* us if the interrupt is waiting for an EOI.
*
* RTC is special: it is edge-triggered, but userspace likes to know
* if it has been already ack-ed via EOI because coalesced RTC
* interrupts lead to time drift in Windows guests. So we track
* EOI manually for the RTC interrupt.
*/
// RTC
if (irq == RTC_GSI && line_status &&
rtc_irq_check_coalesced(ioapic)) {
ret = 0;
goto out;
}
// 原来的irr寄存器
old_irr = ioapic->irr;
// irr相应位置位
ioapic->irr |= mask;
// 如果是边沿触发
if (edge) {
ioapic->irr_delivered &= ~mask;
// 边沿触发且旧的irr寄存器与请求的irr相等
// 说明已经有个这样的中断请求, 不触发
if (old_irr == ioapic->irr) {
ret = 0;
goto out;
}
}
// 1. 边沿触发, 旧的irr寄存器与请求的irr不等
// 或者
// 2. 电平触发
ret = ioapic_service(ioapic, irq, line_status);
out:
trace_kvm_ioapic_set_irq(entry.bits, irq, ret == 0);
return ret;
}到这里,中断已经到达模拟的IO-APIC了,IO-APIC最重要的就是它的重定向表,针对重定向表的操作主要在ioapic_service中,之前都是做一些准备工作,在进入ioapic_service函数之前,主要有两个任务:
-
判断触发方式,主要是区分电平触发和边沿触发。
-
设置ioapic的irr寄存器。
之前我们说过,边沿触发需要两个水平触发来模拟,前后电平相反。这里就要先做判断是对应哪一次。只有首次触发才会进行后续的操作,而二次触发相当于reset操作,就是把ioapic的irr寄存器清除。
5.4.2.3. ioapic_service(): 根据RTE构建中断消息发往lapic
边沿触发且旧irr与新的不等, 或者, 电平触发,就会对其进行更新,进入ioapic_service函数。
// arch/x86/kvm/ioapic.h
#ifdef CONFIG_X86
#define RTC_GSI 8
#else
#define RTC_GSI -1U
#endif
// arch/x86/kvm/ioapic.c
static int ioapic_service(struct kvm_ioapic *ioapic, int irq, bool line_status)
{
// 根据irq获取重定向表的相应项RTE
union kvm_ioapic_redirect_entry *entry = &ioapic->redirtbl[irq];
// 下面根据entry构建lapic的irq
struct kvm_lapic_irq irqe;
int ret;
// 1. 该entry设置了mask, 即被屏蔽
// 或者
// 2. 电平触发以及
// 不触发, 直接返回
if (entry->fields.mask ||
(entry->fields.trig_mode == IOAPIC_LEVEL_TRIG &&
entry->fields.remote_irr))
return -1;
// 下面根据entry格式化了中断消息
irqe.dest_id = entry->fields.dest_id;
// 向量号
irqe.vector = entry->fields.vector;
irqe.dest_mode = kvm_lapic_irq_dest_mode(!!entry->fields.dest_mode);
irqe.trig_mode = entry->fields.trig_mode;
irqe.delivery_mode = entry->fields.delivery_mode << 8;
irqe.level = 1;
irqe.shorthand = APIC_DEST_NOSHORT;
irqe.msi_redir_hint = false;
// 边沿触发
if (irqe.trig_mode == IOAPIC_EDGE_TRIG)
ioapic->irr_delivered |= 1 << irq;
// RTC, irq8
if (irq == RTC_GSI && line_status) {
/*
* pending_eoi cannot ever become negative (see
* rtc_status_pending_eoi_check_valid) and the caller
* ensures that it is only called if it is >= zero, namely
* if rtc_irq_check_coalesced returns false).
*/
BUG_ON(ioapic->rtc_status.pending_eoi != 0);
// 将消息传递给相应的vcpu
ret = kvm_irq_delivery_to_apic(ioapic->kvm, NULL, &irqe,
&ioapic->rtc_status.dest_map);
ioapic->rtc_status.pending_eoi = (ret < 0 ? 0 : ret);
} else
ret = kvm_irq_delivery_to_apic(ioapic->kvm, NULL, &irqe, NULL);
// 投递成功并且是电平触发, 设置目的中断请求寄存器
if (ret && irqe.trig_mode == IOAPIC_LEVEL_TRIG)
entry->fields.remote_irr = 1;
return ret;
}该函数比较简单,就是根据irq号,获取重定向表中的一项,判断kvm_ioapic_redirect_entry没有设置mask,然后根据kvm_ioapic_redirect_entry,构建kvm_lapic_irq,这就类似于在总线上的传递过程。
5.4.2.3.1. kvm_irq_delivery_to_apic(): 投递消息到lapic
之后调用kvm_irq_delivery_to_apic,该函数会把消息传递给相应的VCPU ,
int kvm_irq_delivery_to_apic(struct kvm *kvm, struct kvm_lapic *src,
struct kvm_lapic_irq *irq, struct dest_map *dest_map)
{
int i, r = -1;
struct kvm_vcpu *vcpu, *lowest = NULL;
unsigned long dest_vcpu_bitmap[BITS_TO_LONGS(KVM_MAX_VCPUS)];
unsigned int dest_vcpus = 0;
if (kvm_irq_delivery_to_apic_fast(kvm, src, irq, &r, dest_map))
return r;
if (irq->dest_mode == APIC_DEST_PHYSICAL &&
irq->dest_id == 0xff && kvm_lowest_prio_delivery(irq)) {
printk(KERN_INFO "kvm: apic: phys broadcast and lowest prio\n");
irq->delivery_mode = APIC_DM_FIXED;
}
memset(dest_vcpu_bitmap, 0, sizeof(dest_vcpu_bitmap));
// 遍历虚拟机每个vcpu
kvm_for_each_vcpu(i, vcpu, kvm) {
if (!kvm_apic_present(vcpu))
continue;
// 根据dest_id
if (!kvm_apic_match_dest(vcpu, src, irq->shorthand,
irq->dest_id, irq->dest_mode))
continue;
if (!kvm_lowest_prio_delivery(irq)) {
if (r < 0)
r = 0;
r += kvm_apic_set_irq(vcpu, irq, dest_map);
} else if (kvm_apic_sw_enabled(vcpu->arch.apic)) {
if (!kvm_vector_hashing_enabled()) {
if (!lowest)
lowest = vcpu;
else if (kvm_apic_compare_prio(vcpu, lowest) < 0)
lowest = vcpu;
} else {
__set_bit(i, dest_vcpu_bitmap);
dest_vcpus++;
}
}
}
if (dest_vcpus != 0) {
int idx = kvm_vector_to_index(irq->vector, dest_vcpus,
dest_vcpu_bitmap, KVM_MAX_VCPUS);
lowest = kvm_get_vcpu(kvm, idx);
}
if (lowest)
r = kvm_apic_set_irq(lowest, irq, dest_map);
return r;
}
bool kvm_apic_match_dest(struct kvm_vcpu *vcpu, struct kvm_lapic *source,
int shorthand, unsigned int dest, int dest_mode)
{
struct kvm_lapic *target = vcpu->arch.apic;
u32 mda = kvm_apic_mda(vcpu, dest, source, target);
ASSERT(target);
switch (shorthand) {
case APIC_DEST_NOSHORT:
if (dest_mode == APIC_DEST_PHYSICAL)
return kvm_apic_match_physical_addr(target, mda);
else
return kvm_apic_match_logical_addr(target, mda);
case APIC_DEST_SELF:
return target == source;
case APIC_DEST_ALLINC:
return true;
case APIC_DEST_ALLBUT:
return target != source;
default:
return false;
}
}
EXPORT_SYMBOL_GPL(kvm_apic_match_dest);
int kvm_apic_set_irq(struct kvm_vcpu *vcpu, struct kvm_lapic_irq *irq,
struct dest_map *dest_map)
{
// 获取vcpu的lapic
struct kvm_lapic *apic = vcpu->arch.apic;
return __apic_accept_irq(apic, irq->delivery_mode, irq->vector,
irq->level, irq->trig_mode, dest_map);
}具体需要调用kvm_apic_set_irq函数,继而调用__apic_accept_irq, 让lapic接收中断
5.4.3. kvm_set_msi(): MSI中断触发函数
5.4.3.1. 整体流程
kvm_set_msi() // msi的中断触发入口
├─ struct kvm_lapic_irq irq;; //
├─ kvm_set_msi_irq(kvm, e, &irq);
└─ kvm_irq_delivery_to_apic(kvm, NULL, &irq, NULL);
| ├─ irq_level = __kvm_irq_line_state(); // 获取电平
| └─ ioapic_set_irq() //
| | ├─ u32 mask = 1 << irq; // irq对应的位
| | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | ├─ edge = (entry.fields.trig_mode == IOAPIC_EDGE_TRIG); // 判断触发方式, 是否边沿触发
| | ├─ ioapic->irr &= ~mask; // 低电平时, 表明边沿触发第二次触发, 清理irr中相应的irq位, 直接返回, 说明模拟情况下电平触发只在高电平触发
| | ├─ old_irr = ioapic->irr; // 保存原有irr寄存器
| | ├─ ioapic->irr |= mask; // irr寄存器相应位置位
| | └─ ioapic_service(); // 将s赋值给kvm->arch.vpic
| | | ├─ entry = ioapic->redirtbl[irq]; // 获取irq对应的ioapic中的重定向表项, 即RTE
| | | ├─ irqe.XXX = XXX // 构建中断消息, 对应kvm_lapic_irq
| | | ├─ kvm_irq_delivery_to_apic(); // 将中断消息投递到lapic
| | | | ├─ //
| | | | └─ kvm_apic_set_irq(); //
| | | └─ entry->fields.remote_irr = 1; // 投递成功且电平触发模式5.4.3.2. msi的触发入口
int kvm_set_msi(struct kvm_kernel_irq_routing_entry *e,
struct kvm *kvm, int irq_source_id, int level, bool line_status)
{
struct kvm_lapic_irq irq;
if (kvm_msi_route_invalid(kvm, e))
return -EINVAL;
if (!level)
return -1;
kvm_set_msi_irq(kvm, e, &irq);
return kvm_irq_delivery_to_apic(kvm, NULL, &irq, NULL);
}就是将irq消息解析,然后构造发送给VCPU的LAPIC,后面和IOAPIC的相同。
kvm_set_msi() -> kvm_irq_delivery_to_apic() -> kvm_apic_set_irq() -> __apic_accept_irq()这里要注意,CPU主循环和中断注入是两个并行的过程,所以CPU处于任何状态都能进行设置中断,设置中断以后,就会引起中断退出(最后一点是个人意见,可能不正确,应该是要写到vmcs位)。另外来自QEMU的中断注入也是调用这个循环,所以在QEMU中的中断和CPU循环也是并行执行。
5.5. __apic_accept_irq(): LAPIC接收中断
然后来看下LAPIC如何接收中断,主要是在函数__apic_accept_irq中,这里就是将中断写入当前触发VCPU的kvm_lapic结构体中的相应位置。
/*
* Add a pending IRQ into lapic.
* Return 1 if successfully added and 0 if discarded.
*/
static int __apic_accept_irq(struct kvm_lapic *apic, int delivery_mode,
int vector, int level, int trig_mode,
struct dest_map *dest_map)
{
int result = 0;
struct kvm_vcpu *vcpu = apic->vcpu;
trace_kvm_apic_accept_irq(vcpu->vcpu_id, delivery_mode,
trig_mode, vector);
// APIC 投递模式, 表明是什么功能
switch (delivery_mode) {
case APIC_DM_LOWEST:
vcpu->arch.apic_arb_prio++;
/* fall through */
case APIC_DM_FIXED:
if (unlikely(trig_mode && !level))
break;
/* FIXME add logic for vcpu on reset */
if (unlikely(!apic_enabled(apic)))
break;
result = 1;
if (dest_map) {
__set_bit(vcpu->vcpu_id, dest_map->map);
dest_map->vectors[vcpu->vcpu_id] = vector;
}
if (apic_test_vector(vector, apic->regs + APIC_TMR) != !!trig_mode) {
if (trig_mode)
// 中断触发,设置中断位,设置apic里面的寄存器变量
// 偏移地址 APIC_TMR 和真实APIC控制器相同
kvm_lapic_set_vector(vector,
apic->regs + APIC_TMR);
else
kvm_lapic_clear_vector(vector,
apic->regs + APIC_TMR);
}
if (kvm_x86_ops.deliver_posted_interrupt(vcpu, vector)) {
// 设置irr寄存器
kvm_lapic_set_irr(vector, apic);
// 请求 KVM_REQ_EVENT 事件
// 在下次vm-entry的时候会进行中断注入
kvm_make_request(KVM_REQ_EVENT, vcpu);
kvm_vcpu_kick(vcpu);
}
break;
case APIC_DM_REMRD:
result = 1;
vcpu->arch.pv.pv_unhalted = 1;
kvm_make_request(KVM_REQ_EVENT, vcpu);
kvm_vcpu_kick(vcpu);
break;
case APIC_DM_SMI:
result = 1;
kvm_make_request(KVM_REQ_SMI, vcpu);
kvm_vcpu_kick(vcpu);
break;
case APIC_DM_NMI:
result = 1;
kvm_inject_nmi(vcpu);
kvm_vcpu_kick(vcpu);
break;
case APIC_DM_INIT:
if (!trig_mode || level) {
result = 1;
/* assumes that there are only KVM_APIC_INIT/SIPI */
apic->pending_events = (1UL << KVM_APIC_INIT);
kvm_make_request(KVM_REQ_EVENT, vcpu);
kvm_vcpu_kick(vcpu);
}
break;
case APIC_DM_STARTUP:
result = 1;
apic->sipi_vector = vector;
/* make sure sipi_vector is visible for the receiver */
smp_wmb();
set_bit(KVM_APIC_SIPI, &apic->pending_events);
kvm_make_request(KVM_REQ_EVENT, vcpu);
kvm_vcpu_kick(vcpu);
break;
case APIC_DM_EXTINT:
/*
* Should only be called by kvm_apic_local_deliver() with LVT0,
* before NMI watchdog was enabled. Already handled by
* kvm_apic_accept_pic_intr().
*/
break;
default:
printk(KERN_ERR "TODO: unsupported delivery mode %x\n",
delivery_mode);
break;
}
return result;
}该函数中会根据不同的传递模式处理消息
kvm_vcpu_kick 产生处理器中断ipi , 重新调度,为中断注入做准备。
大部分情况都是APIC_DM_FIXED,在该模式下,中断被传递到特定的CPU,其中会调用kvm_x86_ops->deliver_posted_interrupt,实际上对应于vmx.c中的vmx_deliver_posted_interrupt
/*
* Send interrupt to vcpu via posted interrupt way.
* 1. If target vcpu is running(non-root mode), send posted interrupt
* notification to vcpu and hardware will sync PIR to vIRR atomically.
* 2. If target vcpu isn't running(root mode), kick it to pick up the
* interrupt from PIR in next vmentry.
*/
static int vmx_deliver_posted_interrupt(struct kvm_vcpu *vcpu, int vector)
{
struct vcpu_vmx *vmx = to_vmx(vcpu);
int r;
r = vmx_deliver_nested_posted_interrupt(vcpu, vector);
if (!r)
return 0;
if (!vcpu->arch.apicv_active)
return -1;
// 设置位图
if (pi_test_and_set_pir(vector, &vmx->pi_desc))
return 0;
/*标记位图更新标志*/
/* If a previous notification has sent the IPI, nothing to do. */
if (pi_test_and_set_on(&vmx->pi_desc))
return 0;
if (!kvm_vcpu_trigger_posted_interrupt(vcpu, false))
kvm_vcpu_kick(vcpu);
return 0;
}这里主要是设置vmx->pi_desc中的位图即struct pi_desc中的pir字段,其是一个32位的数组,共8项。因此最大标记256个中断,每个中断向量对应一位。
static inline bool kvm_vcpu_trigger_posted_interrupt(struct kvm_vcpu *vcpu,
bool nested)
{
#ifdef CONFIG_SMP
int pi_vec = nested ? POSTED_INTR_NESTED_VECTOR : POSTED_INTR_VECTOR;
if (vcpu->mode == IN_GUEST_MODE) {
/*
* The vector of interrupt to be delivered to vcpu had
* been set in PIR before this function.
*
* Following cases will be reached in this block, and
* we always send a notification event in all cases as
* explained below.
*
* Case 1: vcpu keeps in non-root mode. Sending a
* notification event posts the interrupt to vcpu.
*
* Case 2: vcpu exits to root mode and is still
* runnable. PIR will be synced to vIRR before the
* next vcpu entry. Sending a notification event in
* this case has no effect, as vcpu is not in root
* mode.
*
* Case 3: vcpu exits to root mode and is blocked.
* vcpu_block() has already synced PIR to vIRR and
* never blocks vcpu if vIRR is not cleared. Therefore,
* a blocked vcpu here does not wait for any requested
* interrupts in PIR, and sending a notification event
* which has no effect is safe here.
*/
apic->send_IPI_mask(get_cpu_mask(vcpu->cpu), pi_vec);
return true;
}
#endif
return false;
}设置好后,请求KVM_REQ_EVENT事件,在下次vm-entry的时候会进行中断注入。
static inline void kvm_make_request(int req, struct kvm_vcpu *vcpu)
{
/*
* Ensure the rest of the request is published to kvm_check_request's
* caller. Paired with the smp_mb__after_atomic in kvm_check_request.
*/
smp_wmb();
set_bit(req & KVM_REQUEST_MASK, (void *)&vcpu->requests);
}6. 中断具体注入过程
当我们设置好虚拟中断控制器以后,接着在KVM_RUN退出以后,就开始遍历这些虚拟中断控制器,如果发现中断,就将中断写入中断信息位(中断注入).
中断注入实际是向客户机CPU注入一个事件,这个事件包括异常, 外部中断和NMI。异常我们一般看作为同步,中断被认为异步。
硬件具体实现就是设置VMCS中字段VM-Entry interruption-infomation中断信息位字段。
中断注入实际在VM运行前完成的, 当中断完成后通过读取中断的返回信息来分析中断是否正确。
6.1. 整体流程
vcpu_enter_guest() // 物理CPU进入guest模式
├─ kvm_check_request(KVM_REQ_EVENT, vcpu) || req_int_win // 检查是否有事件请求
| ├─ inject_pending_event(vcpu); // 注入阻塞的事件,中断,异常和nmi
├─ kvm_x86_ops.run(vcpu) // 真正进入虚拟机模式
6.2.
在vcpu_enter_guest (x86.c)函数中,有这么一段代码
//检查是否有事件请求
if (kvm_check_request(KVM_REQ_EVENT, vcpu) || req_int_win) {
++vcpu->stat.req_event;
kvm_apic_accept_events(vcpu);
if (vcpu->arch.mp_state == KVM_MP_STATE_INIT_RECEIVED) {
r = 1;
goto out;
}
// 注入阻塞的事件,中断,异常和nmi等
/*注入中断在vcpu加载到真实cpu上后,相当于某些位已经被设置*/
if (inject_pending_event(vcpu) != 0)
req_immediate_exit = true;
else {
/* Enable SMI/NMI/IRQ window open exits if needed.
*
* SMIs have three cases:
* 1) They can be nested, and then there is nothing to
* do here because RSM will cause a vmexit anyway.
* 2) There is an ISA-specific reason why SMI cannot be
* injected, and the moment when this changes can be
* intercepted.
* 3) Or the SMI can be pending because
* inject_pending_event has completed the injection
* of an IRQ or NMI from the previous vmexit, and
* then we request an immediate exit to inject the
* SMI.
*/
if (vcpu->arch.smi_pending && !is_smm(vcpu))
if (!kvm_x86_ops.enable_smi_window(vcpu))
req_immediate_exit = true;
/* 使能NMI/IRQ window,参见Intel64 System Programming Guide 25.3节(P366)
* 当使能了interrupt-window exiting或NMI-window exiting(由VMCS中相关字段控制),
* 表示在刚进入虚拟机后,就会立刻因为有pending或注入的中断导致VM-exit
*/
if (vcpu->arch.nmi_pending)
kvm_x86_ops.enable_nmi_window(vcpu);
// 收集中断
if (kvm_cpu_has_injectable_intr(vcpu) || req_int_win)
kvm_x86_ops.enable_irq_window(vcpu);
WARN_ON(vcpu->arch.exception.pending);
}
if (kvm_lapic_enabled(vcpu)) {
update_cr8_intercept(vcpu);
kvm_lapic_sync_to_vapic(vcpu);
}
}即在进入非根模式之前会检查KVM_REQ_EVENT事件,如果存在pending的事件,则调用kvm_apic_accept_events接收,这里主要是处理APIC初始化期间和IPI中断的,暂且不关注。
之后会调用inject_pending_event()
static int inject_pending_event(struct kvm_vcpu *vcpu)
{
int r;
/* try to reinject previous events if any */
if (vcpu->arch.exception.injected)
kvm_x86_ops.queue_exception(vcpu);
/*
* Do not inject an NMI or interrupt if there is a pending
* exception. Exceptions and interrupts are recognized at
* instruction boundaries, i.e. the start of an instruction.
* Trap-like exceptions, e.g. #DB, have higher priority than
* NMIs and interrupts, i.e. traps are recognized before an
* NMI/interrupt that's pending on the same instruction.
* Fault-like exceptions, e.g. #GP and #PF, are the lowest
* priority, but are only generated (pended) during instruction
* execution, i.e. a pending fault-like exception means the
* fault occurred on the *previous* instruction and must be
* serviced prior to recognizing any new events in order to
* fully complete the previous instruction.
*/
// 如果存在老的还没有注入的中断,则注入之
else if (!vcpu->arch.exception.pending) {
if (vcpu->arch.nmi_injected)
kvm_x86_ops.set_nmi(vcpu);
else if (vcpu->arch.interrupt.injected)
kvm_x86_ops.set_irq(vcpu);
}
/*
* Call check_nested_events() even if we reinjected a previous event
* in order for caller to determine if it should require immediate-exit
* from L2 to L1 due to pending L1 events which require exit
* from L2 to L1.
*/
if (is_guest_mode(vcpu) && kvm_x86_ops.check_nested_events) {
r = kvm_x86_ops.check_nested_events(vcpu);
if (r != 0)
return r;
}
/* try to inject new event if pending */
if (vcpu->arch.exception.pending) {
trace_kvm_inj_exception(vcpu->arch.exception.nr,
vcpu->arch.exception.has_error_code,
vcpu->arch.exception.error_code);
WARN_ON_ONCE(vcpu->arch.exception.injected);
vcpu->arch.exception.pending = false;
vcpu->arch.exception.injected = true;
if (exception_type(vcpu->arch.exception.nr) == EXCPT_FAULT)
__kvm_set_rflags(vcpu, kvm_get_rflags(vcpu) |
X86_EFLAGS_RF);
if (vcpu->arch.exception.nr == DB_VECTOR) {
/*
* This code assumes that nSVM doesn't use
* check_nested_events(). If it does, the
* DR6/DR7 changes should happen before L1
* gets a #VMEXIT for an intercepted #DB in
* L2. (Under VMX, on the other hand, the
* DR6/DR7 changes should not happen in the
* event of a VM-exit to L1 for an intercepted
* #DB in L2.)
*/
kvm_deliver_exception_payload(vcpu);
if (vcpu->arch.dr7 & DR7_GD) {
vcpu->arch.dr7 &= ~DR7_GD;
kvm_update_dr7(vcpu);
}
}
kvm_x86_ops.queue_exception(vcpu);
}
/* Don't consider new event if we re-injected an event */
if (kvm_event_needs_reinjection(vcpu))
return 0;
if (vcpu->arch.smi_pending && !is_smm(vcpu) &&
kvm_x86_ops.smi_allowed(vcpu)) {
vcpu->arch.smi_pending = false;
++vcpu->arch.smi_count;
enter_smm(vcpu);
} else if (vcpu->arch.nmi_pending && kvm_x86_ops.nmi_allowed(vcpu)) {
--vcpu->arch.nmi_pending;
vcpu->arch.nmi_injected = true;
kvm_x86_ops.set_nmi(vcpu);
} else if (kvm_cpu_has_injectable_intr(vcpu)) {
/*
* Because interrupts can be injected asynchronously, we are
* calling check_nested_events again here to avoid a race condition.
* See https://lkml.org/lkml/2014/7/2/60 for discussion about this
* proposal and current concerns. Perhaps we should be setting
* KVM_REQ_EVENT only on certain events and not unconditionally?
*/
if (is_guest_mode(vcpu) && kvm_x86_ops.check_nested_events) {
r = kvm_x86_ops.check_nested_events(vcpu);
if (r != 0)
return r;
}
if (kvm_x86_ops.interrupt_allowed(vcpu)) {
// 获得当前中断号, 将中断记录到vcpu中
kvm_queue_interrupt(vcpu, kvm_cpu_get_interrupt(vcpu),
false);
// 写入vmcs结构中
kvm_x86_ops.set_irq(vcpu);
}
}
return 0;
}在这里会检查当前是否有可注入的中断,而具体检查过程时首先会通过kvm_cpu_has_injectable_intr函数,其中调用kvm_apic_has_interrupt->apic_find_highest_irr->vmx_sync_pir_to_irr, vmx_sync_pir_to_irr函数对中断进行收集,就是检查vmx->pi_desc中的位图,如果有,则会调用kvm_apic_update_irr把信息更新到apic寄存器里。
然后调用apic_search_irr获取IRR寄存器中的中断,没找到的话会返回-1. 找到后调用kvm_queue_interrupt,把中断记录到vcpu中。
static inline void kvm_queue_interrupt(struct kvm_vcpu *vcpu, u8 vector,
bool soft)
{
//将当前中断pending标记为true
vcpu->arch.interrupt.pending = true;
vcpu->arch.interrupt.soft = soft;
vcpu->arch.interrupt.nr = vector;
}最后会调用kvm_x86_ops->set_irq,进行中断注入的最后一步,即写入到vmcs结构中。该函数指针指向vmx_inject_irq
static void vmx_inject_irq(struct kvm_vcpu *vcpu)
{
struct vcpu_vmx *vmx = to_vmx(vcpu);
uint32_t intr;
// 之前得到并且设置好的中断的中断向量号
int irq = vcpu->arch.interrupt.nr;
trace_kvm_inj_virq(irq);
++vcpu->stat.irq_injections;
if (vmx->rmode.vm86_active) {
int inc_eip = 0;
if (vcpu->arch.interrupt.soft)
inc_eip = vcpu->arch.event_exit_inst_len;
kvm_inject_realmode_interrupt(vcpu, irq, inc_eip);
return;
}
// 设置有中断向量的有效性
intr = irq | INTR_INFO_VALID_MASK;
// 看是外部中断还是软中断,我们之前注入的地方默认是false,所以是走下面分支
// 如果是软件中断
if (vcpu->arch.interrupt.soft) {
// 内部中断
intr |= INTR_TYPE_SOFT_INTR;
// 软件中断需要写入指令长度
vmcs_write32(VM_ENTRY_INSTRUCTION_LEN,
vmx->vcpu.arch.event_exit_inst_len);
} else
// 标记为外部中断
intr |= INTR_TYPE_EXT_INTR;
// 写入vmcs的VM_ENTRY_INTR_INFO_FIELD中断信息位中
vmcs_write32(VM_ENTRY_INTR_INFO_FIELD, intr);
vmx_clear_hlt(vcpu);
}最终会写入到vmcs的VM_ENTRY_INTR_INFO_FIELD中,这需要按照一定的格式。具体格式详见intel手册。
0-7位是向量号,8-10位是中断类型(硬件中断或者软件中断),- 最高位是有效位,
- 12位是NMI标志。
// arch/x86/include/asm/vmx.h
/*
* Interruption-information format
*/
#define INTR_INFO_VECTOR_MASK 0xff /* 7:0 */
#define INTR_INFO_INTR_TYPE_MASK 0x700 /* 10:8 */
#define INTR_INFO_DELIVER_CODE_MASK 0x800 /* 11 */
#define INTR_INFO_UNBLOCK_NMI 0x1000 /* 12 */
#define INTR_INFO_VALID_MASK 0x80000000 /* 31 */这样KVM就完成了虚拟中断的注入,从中断源触发到写入虚拟中断控制器,再到VMCS的过程。
7. 中断注入触发的源
最后再回过头来讲讲是什么时候触发这个kvm_set_irq的。当然中断需要模拟的时候就调用。这里调用分为两种。
- 可以直接在KVM中调用这个函数,如虚拟I8254,我在其他文章中分析过i8254的中断模拟过程,这里有这种类型设备的中断源的模拟,顺被贴一张,一般中断源的逻辑流程图:

- 可以从QEMU中通过调用QEMU中的函数中断注入函数
kvm_set_irq.
在QEMU中,如果有中断触发,会触发到相应中断控制器,中断方式也有8259(hw/i8259.c), IOAPIC(hw/ipf.c x86下没用这个,pic和apic相同处理,将pic扩展到24个), MSI(hw/msix.c),在这里中断控制器里面都会触发这个QEMU的kvm_set_irq函数。
至于这个kvm_set_irq函数位置在qemu-kvm.c,在这个函数中进而调用kvm_set_irq_level,最后通过一个KVM_IRQ_LINE的IOCTL调用KVM模块里面的kvm_set_irq函数。
int kvm_set_irq_level(kvm_context_t kvm, int irq, int level, int *status)
{
... ...
event.level = level;
event.irq = irq;
/*IOCTL*/
r = kvm_vm_ioctl(kvm_state, kvm->irqchip_inject_ioctl, &event);
... ...
}这里我就不分析QEMU中的中断源了,毕竟主要讲的是KVM
8. 参考
https://www.cnblogs.com/ck1020/p/7424922.html
https://blog.csdn.net/yearn520/article/details/6663532