import requests
import time
import random
from lxml import etree
import csv
user_agents = [ "Mozilla/5.0 (Windows NT 5.1; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/29.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0",
"Mozilla/5.0 (X11; U; Linux Core i7-4980HQ; de; rv:32.0; compatible; JobboerseBot; Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0"]
def get_html():
for page in range(1, 101):
url = "https://wh.fang.ke.com/loupan/hannan-caidian-jiangxia-huangbei-xinzhou-jiangan-jianghan-wuchang-qiaokou-hanyang-hongshan-dongxihu-qingshan-donghugaoxin-zhuankoukaifaqu/pg{}/#donghugaoxin".format(page)
header = {"user-agent": random.choice(user_agents)}
try:
r = requests.get(url, headers=header).text
except Exception as e:
print(e)
else:
get_data(r)
time.sleep(2)
def get_data(r):
html = etree.HTML(r)
lis = html.xpath('//ul[@class="resblock-list-wrapper"]/li')
for li in lis:
item = {}
item['name'] = li.xpath('./div/div[@class="resblock-name"]/a/@title')[0]
item['type'] = li.xpath('./div/div[@class="resblock-name"]/span[last()]/text()')[0]
location = li.xpath('./div/a[@class="resblock-location"]/text()')
item['location'] = ''
for l in location:
item['location'] += l.strip()
item['price'] = li.xpath('./div/div[@class="resblock-price"]//span[@class="number"]/text()')[0]
save_data(item)
def save_data(item):
with open("贝壳新房数据.csv", "a", encoding='utf-8') as f:
w = csv.DictWriter(f, fieldnames=['name', 'type', 'location', 'price'])
w.writerow(item)
print(item, "已写入")
get_html()

import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
font = {
'family':'SimHei',
'weight':'bold',
'size':12
}
matplotlib.rc("font", **font)
datas = pd.read_csv("贝壳新房数据.csv", header=None)
datas[2] = datas[2].str.split("/", expand=True)[0]
datas
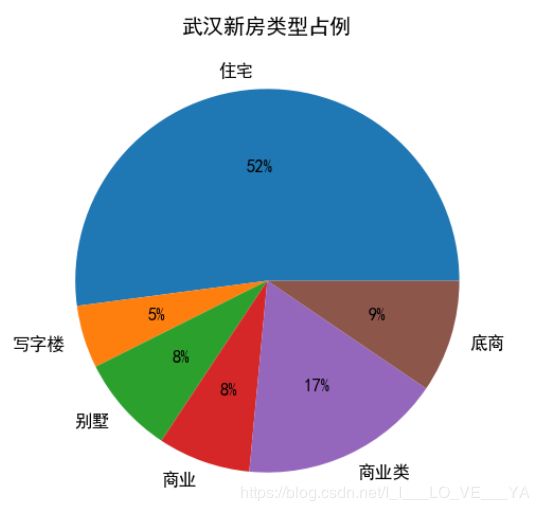
plt.figure(figsize=(8,6), dpi=100)
data = datas.groupby(1).count()[0]
plt.pie(data, labels=data.index, autopct="%.f%%")
plt.title("武汉新房类型占例")
plt.show()
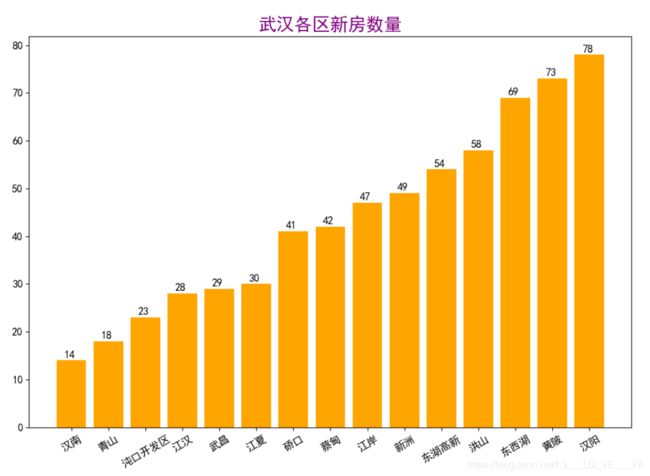
plt.figure(figsize=(12,8), dpi=100)
data = datas[2].value_counts()
data = data.sort_values()
x_label = data.index
y = data.values
x = range(len(x_label))
plt.bar(x, y, color="orange")
plt.xticks(x, x_label, rotation=30)
for i,j in zip(x,y):
plt.text(i-0.2, j+0.5, j)
plt.title("武汉各区新房数量", fontsize=20, color="purple", fontstyle="italic")
for i,x in enumerate(datas[3]):
if datas[3][i] == "价格待定":
datas.drop(index=i, inplace=True)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('max_colwidth',100)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
data1 = datas[datas[1]=="住宅"]
data1 = data1[3].astype("i4")
mx = max(data1)
mi = min(data1)
b = round((mx - mi) / 2000)
plt.figure(figsize=(12,8), dpi=80)
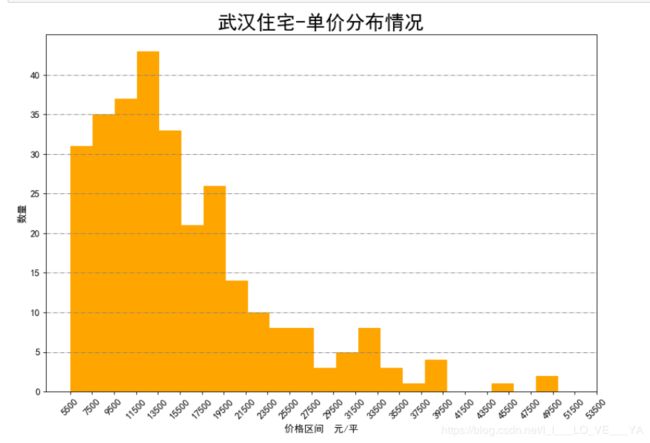
plt.hist(data1, bins=b, color="orange")
plt.xticks(range(5500, 55000)[::2000], rotation=45)
plt.xlabel("价格区间 元/平")
plt.yticks(range(44)[::5])
plt.ylabel("数量")
plt.title("武汉住宅-单价分布情况", fontsize=24)
plt.grid(linestyle="-.", axis='y', color="grey")
plt.show()