浅谈变分自编码器(Variational Auto Encoder)
作者:SnowYuan
1.VAE简介
变分自编码器(Variational Autoencoder,VAE)是生成模型(Generative Model)的一种,另一种常见的生成模型是生成式对抗网络(Generative Adversarial Network,GAN),这里我们介绍下VAE的原理,并用Keras实现。
变分自动编码器很酷,他们让我们对大的数据集建模,设计出复杂的生成模型的数据,它们可以生成虚构的名人面孔和高分辨率数字艺术品的图像。这些模型在图像生成和增强学习方面也产生了当前最先进的机器学习结果。下图展示的是一个用VAE模型生成的虚构的名人面孔。

图1 一个变分的自动编码器生成的虚构的名人面孔
2. VAE原理
从概率的角度,我们假设任何数据集都采样自某个分布P(X|z),z 是隐藏的变量,代表了某种内部特征,比如手写数字的图片 x,z 可以表示字体的大小,书写风格,加粗、斜体 等设定,它符合某个先验分布,在给定具体隐藏变量 z 的情况下,我们可以从学到了 分布中采样一系列的生成样本,这些样本都具有 z 所表示的共性。
在P(z)已知(可以假定它符合已知的分布,比如N(0,1)的条件下,我们的目的就是希望能学会生成概率模型P(X|Z)。这里我们可以采用最大似然估计(Maximum likelihood estimation):一个好的模型,应该拥有很大的概率产生已观测的样本x ∈D 。如果我们的生成模型是用来参数化,比如我们通过一个神经网络 Decoder 来学习,那么就是此 decoder 的权值w, b等,那么我们的神经网络的优化目标是:
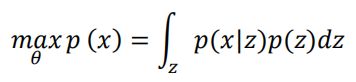
很遗憾的是,由于 z 是连续变量,上述积分没法转换为离散形式,导致上式很难直接优化。
换一个思路,利用变分推断(Variational Inference)的思想,我们通过分布q(z|x)来逼近 p(x|z),即需要优化q(z|x) 与p(x|z)之间的距离:
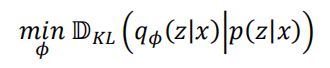
其中 KL 散度是一种衡量分布p,q之间的差距的度量,定义为:
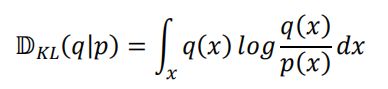
我们试图建立一个生成模型,而不是一个模糊的数据结构,可以“记忆”图像。我们还不能生成任何东西,因为除了从图像中编码外,我们不知道如何创建潜在向量。这里有一个简单的解决方案。我们在编码网络上添加了一个约束,迫使它生成大致遵循单位高斯分布的潜在向量。正是这个约束将变分自编码器从标准自编码器中分离出来。生成新图像现在很容易:所有我们需要做的是从单位高斯矩阵采样一个潜在的向量z并通过它的解码器。
在实践中,我们的网络如何精确表达潜在变量与单位高斯分布如何接近是需要权衡的,我们让网络自己来决定。对于我们的损失项,我们总结了两个单独的损失:生成损失,这是一个衡量网络重建图像准确性的均方误差,和一个潜在损失,这是KL散度,衡量潜在变量与单位高斯分布的匹配程度。
generation_loss = mean(square(generated_image - real_image))
latent_loss = KL-Divergence(latent_variable, unit_gaussian)
loss = generation_loss + latent_loss
为了优化KL散度,我们需要应用一个简单的重新参数化技巧:不是编码器生成一个实值向量,而是生成一个均值向量和一个标准差向量。
KL散度计算如下:
#z_mean and z_stddev are two vectors generated by encoder network
latent_loss = 0.5 * tf.reduce_sum(tf.square(z_mean) + tf.square(z_stddev) - tf.log(tf.square(z_stddev)) - 1,1)
当我们计算解码器网络的损耗时,我们只需要从标准差中取样,然后相加,并将其作为我们的潜在向量
samples = tf.random_normal([batchsize,n_z],0,1,dtype=tf.float32)
sampled_z = z_mean + (z_stddev * samples)
除了允许我们生成随机的潜在变量之外,这个约束还改进了我们的网络的泛化能力。
3.网络定义
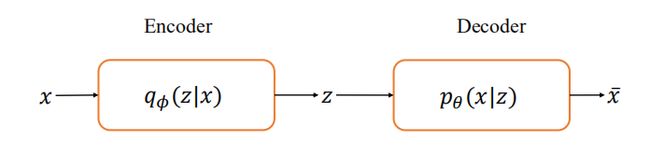
VAE由三部分组成:编码器q(z | x ),先验p(z ),解码器p(x | z )。
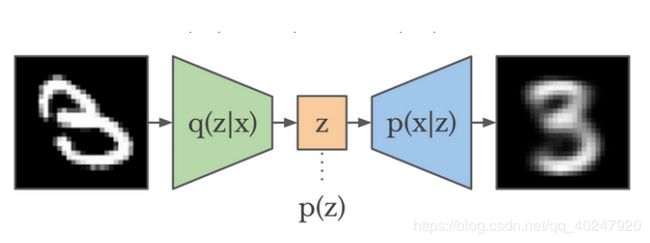
图2 VAE网络结构
4.VAE MNIST实战
通过对潜在空间的采样,我们可以使用解码器网络来形成一个可生成的模型,该模型能够生成与训练期间所观察到的类似的新数据。具体来说,我们将采样的先验分布p(z)假设成它遵循一个单位的高斯分布。图3显示了经过MNIST手写数字数据集训练的变分自编码器的解码器网络生成的数据。在这里,我们从一个二维高斯函数中采样了一个网格值,并显示了我们的解码器网络的输出。

图3 VAE模型生成的手写数字
如图3所示,每个不同的数字存在于潜在空间的不同区域,并从一个数字平滑地变换到另一个数字。当您想要在两个观察值之间插入数据时,这种平滑转换非常有用,例如最近的一个例子,谷歌为两个音乐样本之间的插入建立了一个模型。
VAE MNIST数据集代码示例如下:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras as kr
from keras import backend as K
%matplotlib inline
# MNIST Dataset parameters.
num_features = 784 # data features (img shape: 28*28).
# Training parameters.
batch_size = 128
epochs = 50
# Network Parameters
hidden_1 = 128 # 1st layer num features.
hidden_2 = 64 # 2nd layer num features (the latent dim).
from tensorflow.keras.datasets import mnist, fashion_mnist
def load_data(choice='mnist', labels=False):
if choice not in ['mnist', 'fashion_mnist']:
raise ('Choices are mnist and fashion_mnist')
if choice is 'mnist':
(X_train, y_train), (X_test, y_test) = mnist.load_data()
else:
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train, X_test = X_train / 255., X_test / 255.
X_train, X_test = X_train.reshape([-1, 784]), X_test.reshape([-1, 784])
X_train = X_train.astype(np.float32, copy=False)
X_test = X_test.astype(np.float32, copy=False)
if labels:
return (X_train, y_train), (X_test, y_test)
return X_train, X_test
def plot_digits(X, y, encoder, batch_size=128):
# display a 2D plot of the digit classes in the latent space
z_mean, _, _ = encoder.predict(X, batch_size=batch_size)
plt.figure(figsize=(12, 10))
plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y)
plt.colorbar()
plt.xlabel("z[0] Latent Dimension")
plt.ylabel("z[1] Latent Dimension")
plt.show()
def generate_manifold(decoder):
"""Generates a manifold of MNIST digits from a random noisy data.
"""
# display a 30x30 2D manifold of digits
n = 30
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# linearly spaced coordinates corresponding to the 2D plot
# of digit classes in the latent space
grid_x = np.linspace(-4, 4, n)
grid_y = np.linspace(-4, 4, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
start_range = digit_size // 2
end_range = n * digit_size + start_range + 1
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0] Latent Dimension")
plt.ylabel("z[1] Latent Dimension")
plt.imshow(figure, cmap='Greys_r')
plt.show()
def sampling(args):
z_mean, z_log_var = args
# eps = K.random_normal(tf.shape(z_log_var), dtype=tf.float32, mean=0., stddev=1.0, name='epsilon')
eps = K.random_normal(tf.shape(z_log_var), dtype=tf.float32, mean=0., stddev=1.0)
z = z_mean + tf.exp(z_log_var / 2) * eps
return z
# Encoder
inputs = kr.layers.Input(shape=(num_features, ), name='input')
x = kr.layers.Dense(hidden_dim, activation='relu')(inputs)
z_mean = kr.layers.Dense(latent_dim, name='z_mean')(x)
z_log_var = kr.layers.Dense(latent_dim, name='z_log_var')(x)
### Use reparameterization trick to push the sampling out as input
z = kr.layers.Lambda(sampling, name='z')([z_mean, z_log_var])
### instantiate encoder model
encoder = kr.Model(inputs, [z_mean, z_log_var, z], name='encoder')
encoder.summary()
# Decoder
latent_inputs = kr.layers.Input(shape=(latent_dim), name='z_sampling')
x = kr.layers.Dense(hidden_dim, activation='relu')(latent_inputs)
outputs = kr.layers.Dense(num_features, activation='sigmoid')(x)
#### instantiate decoder model
decoder = kr.Model(latent_inputs,outputs, name='decoder')
decoder.summary()
## VAE model = encoder + decoder
outputs = decoder(encoder(inputs)[2]) # select the Z value from outputs of the encoder
vae = kr.Model(inputs, outputs, name='vae')
# Define VAE Loss
# Reconstruction loss
reconstruction_loss = tf.losses.mean_squared_error(inputs, outputs)
reconstruction_loss = reconstruction_loss * num_features
# KL Divergence loss
kl_loss = 1+z_log_var - tf.square(z_mean)- tf.exp(z_log_var)
kl_loss = -0.5 * tf.reduce_sum(kl_loss, axis=-1)
vae_loss = tf.reduce_mean(reconstruction_loss + kl_loss )
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
vae.summary()
# Train Model
(X_train, _), (X_test, y) = load_data('mnist', labels=True)
vae.fit(X_train, epochs=epochs, batch_size=batch_size, validation_data=(X_test, None))
# Predict and Visualization
generate_manifold(decoder)
plot_digits(X_test, y, encoder) # y for label color