目标检测的终极武器·Efficentdet的进阶之路--从Modile Net 到 Efficentnet 并附源码
Efficentdet的进阶之路
论文:https://arxiv.org/pdf/1911.09070.pdf
tf源码:https://github.com/google/automl/tree/master/efficientdet
pytorch源码:https://github.com/JianqiuChen/EfficientDet.Pytorch
MobileNet三部曲
【MobileNet V1】

把普通的卷积变成深度卷积(depthwise convolution)和点对卷积(pointwise convolution)。可以降低大约kernel size 平方倍
kernel 的大小是 DK 生成的特征图的DF M是输入通道数 N是输出通道数
原始的卷积是 DK × DK x DF x DF x M x N
deepwise 卷积是上图中b 表示用M个维度为DKDK1的卷积核去卷积对应输入的M个feature map,然后得到M个结果,而且这M个结果相互之间不累加(传统的卷积是用N个卷积核卷积输入的所有(也就是M个)feature map,然后累加这M个结果,最终得到N个累加后的结果)
c)就是 用N个维度为11M的卷积核卷积(b)的结果,即输入是DFDFM,最终得到DFDFN的feature map。这个就可以当做是普通的一个卷积过程了,所以计算量是DFDF11M*N
【MobileNet V2】
使用流行学习进行证明
1) ReLu会导致的较多的信息损耗在通道数较少的时候
策略:在输出通道较少的时候用线性激活函数,其他时候任然用ReLU6
2)通道数多的时候可以减少损失
策略:当使用ReLU6的时候,增加通道数为输入通道数的t倍

线性瓶颈的倒置残差结构:模块的输入为一个低维的压缩表示特征,首先将其扩展到高维并用轻量级depthwise conv 进行卷积。随后用线性卷积(linear conv)将特征投影回低维表示。
【MobileNet V3】
(1)用MnasNet搜索网络结构;
使用强化学习搜索最优网络,每层的结构多样化
搜索空间包含如下:
标准卷积,深度可分离卷积(DWConv), MBConv(即上面提到的MobileNetV2的卷积模块)
卷积核大小:3, 5, 7等
Squeeze-and-excitation ratio (SE-Ratio): 0, 0.25
Skip-connection
输出通道数
不同block中的layer数量
(2)V1的深度可分离卷积;
(3)V2的线性瓶颈的倒置残差结构;
(4)引入SE模块 (通道加权)

使有效的feature map权重大,无效或效果小的feature map权重小的方 式训练模型达到更好的结果。
(5)新的激活函数h-swish(x);
(6)网格搜索中利用两个策略:资源受限的NAS和NetAdapt;
(7)修改V2最后部分减小计算。
【EfficientNet】 速度与精度的结合
对 网络深度、网络宽度、图像分辨率 在当前计算资源下进行调忧

网络的构建分两步进行:
第一步是在当前系数下,首先固定 ϕ \phi ϕ 为 1,即设定计算量为原来的 2 倍,在这样一个小模型上做网格搜索(grid search),得到最佳系数 α \alpha α, β \beta β, γ \gamma γ
第二步 固定 α \alpha α, β \beta β, γ \gamma γ 使用不同的混合系数 ϕ \phi ϕ放大网络。
【EfficientDet】 速度与精度的结合
作者在两个方向提高了目标检测模型的效率
【BIFPN】:快速实现多尺度的特征融合
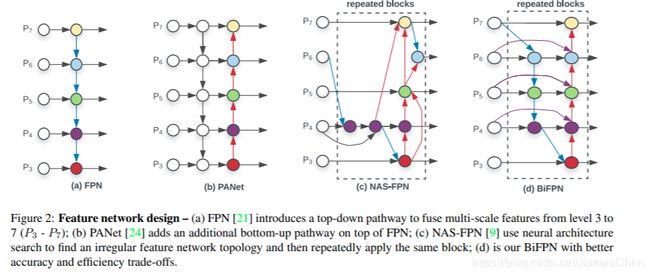
BiFPN 和以往的FPN网络做对比
传统的FPN网络是受限于单向流动的网络结构
Conventional top-down FPN is inherently limited by the
one-way information flow.
PANet 引入了另一条bottom-up path 整合网络 图b
NAS 网络通过几千个gpu小时搜索到了一个较好的跨比例的特征网络(cross-scale feature network topology) 图c
BIFPN 在跨比例连接上的改进
第一点改进 每个字节点的输入信息不再只有一个
第二点改进 在同一level上建立另一条路径以在不增加参数的情况下融合更多的特征
第三点改进 加入了双向的路径 把双向的路径当作一个网络重复多次以完成更好的特征融合
BIFPN 在特征加权上的改进:
引入可学习权重
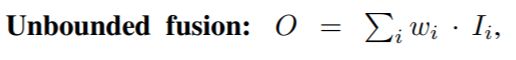
作者发现不同resolution的图像对输出特征的贡献程度也是不一样的
无限制的加权:
w 的值可以是一个标量(对每一个特征),可以是一个向量(对每一个通道),也可以是一个多维度的tenor(对每一个像素)。但是如果出现偏差不加限制容易导致训练不稳定。
简单解决方法是 每一个权重用softmax但是效率较低
最终解决办法是使用快速归一融合的方法
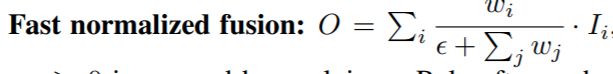
weight前采用relu函数 确保w>0
实验表明和softmax方法只有很细小的差异在学习行为和准确率上但是速度要快30%!
上图 第六层BIFPN融合的公式(所有的特征都用这种相似的方式):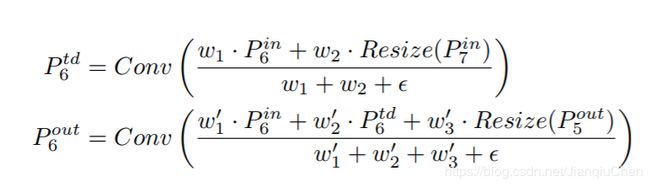
整体网络架构

复合缩放
主干网络:使用和 EfficientNetB0-B6一样的设置 以复用checkpoint
BiFPN网络:

Box/class prediction network:
宽度和BiFPN一样
深度改为:
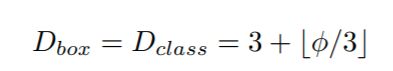
Input image resolution:

整体的复合缩放设置
