hadoop - hadoop2.6 分布式 - 集群环境搭建 - Hadoop 2.6 分布式 配置,初始化,启动过程
1.背景
上篇记录了hadoop的核心配置和zookeeper的基本配置,这篇将我的配置记录下,包括启动过程的总结!简单的分布式环境搭建了四遍,也算是懂些了皮毛,总算是可以启动了!我的运行环境这里不在详述。还是声明一点,所有的均是在root用户下完成的!
2.Hadoop 配置
2.1 etc/hadoop 目录下
先进入 该目录下 :
root@note1:~/hadoop-2.6/etc/hadoop#
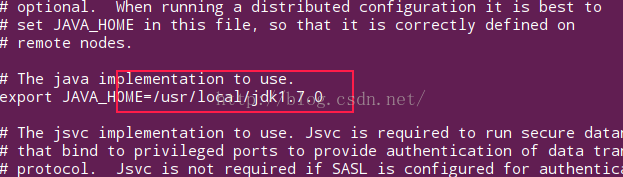
(1)hadoop-env.sh
配置JAVA运行环境 , JAVA_HOME ;
root@note1:~/hadoop-2.6/etc/hadoop# vi hadoop-env.sh
(2) core-site.xml
root@note1:~/hadoop-2.6/etc/hadoop# more core-site.xml 全部配置如下 :
fs.defaultFS hdfs://yuannews
(3)hdfs-site.xml
root@note1:~/hadoop-2.6/etc/hadoop# cat hdfs-site.xml 配置如下 :
dfs.nameservices
yuannews
dfs.ha.namenodes.yuannews
nn1,nn2
dfs.namenode.rpc-address.yuannews.nn1
note1:8020
dfs.namenode.rpc-address.yuannews.nn2
note3:8020
dfs.namenode.http-address.yuannews.nn1
note1:50070
dfs.namenode.http-address.yuannews.nn2
note3:50070
dfs.namenode.shared.edits.dir
qjournal://note3:8485;note4:8485;note5:8485/yuannews
dfs.client.failover.proxy.provider.yuannews
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/opt/hadoop/jn/data/
dfs.ha.automatic-failover.enabled
true
(4)maperd-site.xml
将 maperd-site.xml.template 重命名为 mapred-site.xml
root@note1:~/hadoop-2.6/etc/hadoop# mv mapred-site.xml.template mapred-site.xml
配置如下 :
mapreduce.framework.name
yarn
(5)yarn-site.xml
root@note1:~/hadoop-2.6/etc/hadoop# more yarn-site.xml 配置如下 :配置 主运行节点,我的是 note1 ;
yarn.resourcemanager.hostname
note1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
(6)slaves
配置其他集群机子地址,相当于 datanode 所在的地址!
配置如下 :
192.168.56.3
192.168.56.4
192.168.56.5
(7) 配置总结
上面配置的 dfs.journalnode.edits.dir 的时候,需要手动创建该目录,其余的就是服务名称了,一定要对!
3.zookeeper配置
(1)zoo.cfg
root@note1:~/zookeeper-3.4.6/conf# more zoo.cfg 将 zoo.simple.cfg 重命名为 zoo.cfg , 配置如下 :
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
# maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
# The number of snapshots to retain in dataDir
# autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
# autopurge.purgeInterval=1
server.1=note1:2888:3888
server.2=note3:2888:3888
server.3=note4:2888:3888
(1)手动创建 dataDir 目录,我的是 /opt/zookeeper
(2) 在该目录下创建 /opt/zookeeper 目录下,创建 myid 文件 ,文件内容为 上面zoo.cfg配置文件的最后的 server.x 的x , 规则 如下:
1)m节点机子运行zookeeper,在m上,复制zookeeper的程序,即解压出来的,并且相同的配置!
2)每个节点机子上都创建 dataDir目录,并创建myid文件
3)myid 文件内容与 zoo.cfg 最后的对应,比如 server.2=note3:2888:3888 , 那么note3节点机子上的myid 内容为 2,仅仅一个2 ,就可以了,依次类推!
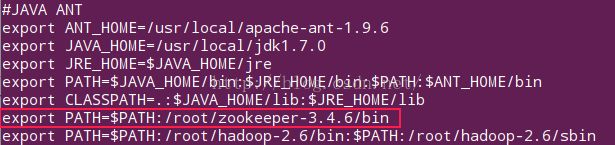
(2)全局配置
将 zookeeper的bin 目录配置到 /etc/profile文件中,我的如下 :
export PATH=$PATH:/root/zookeeper-3.4.6/bin
别忘了 ,执行 source /etc/profile !
(3)zookeeper 测试启动过程
zkServer.sh start
4.初始化过程
(1)测试启动 journalnode
进入 hadoop/sbin 目录
./hadoop-daemon.sh start journalnode
(2)格式化一台namenode
我的有两台namenode , 在 所以在 一台机子上进行 格式化 namenode,这里成为namenode1 , 其他的不需要格式化,但是需要进行以后的操作;
root@note1:~/hadoop-2.6/bin# ./hdfs namenode -format
(3)初始化其他namenode
已经格式化了 namenode1 , 现在初始化 namenode2 , 所以,先启动刚才格式化的 namenode1 :
root@note1:~/hadoop-2.6/sbin# ./hadoop-daemon.sh start namenode
后在 namenode2 的节点机子上执行 初始化操作:
root@note3:~/hadoop-2.6/bin# ./hdfs namenode -bootstrapStandby
(4)初始化 zkfc
前提是 ,在你配置的 zookeeper的机子上,启动 zookeeper (ZK), 然后才能格式化 zkfc , 否则,会报错!
root@note1:~/hadoop-2.6/bin# ./hdfs zkfc -formatZK
(5)启动与停止
start-dfs.sh 和 stop-dfs.sh(6) 注意
在启动的时候,如果发现没有启动的话,注意检查2点,节点机子ip是否可以 ping通 和 节点机子的防火墙是否关闭(有时候);
5.启动过程
先启动 zookeeper , 在启动 hadoop -dfs , 后启动 hadoop - yarn ;
6.总结
这是 这几天的收货,昨天很不好的就是 ,执行了 :rm -rf ~ 命令,结果你懂的,什么都没有了!后花了2个小时,进行了配置,很顺利就完成了!