spark-整合Phoenix将数据写入Hbase
文章目录
- 一 环境准备
- 1.1 pom文件
- 1.2 config配置:
- 1.3 properties解析工具类
- 1.4 HbaseUtil工具类
- 1.5 kafkaUtil根据指定的topic返回对应的Dstream
- 1.6 jedisUtils从连接池中获取Jedis连接实例
- 1.7 样例类
- 二 Spark直接将数据写入Hbase
- 三 Spark整合Phoenix将数据写入hbase
- 四遇到的问题
- 问题1 :Phoenix建表语句大小写问题
- 问题2:jar包冲突
- 问题3 redis 强制退出问题
一 环境准备
需求描述:创建StreamingContext,从kafka中实时消费启动日志数据,借助redis对当天的启动日志进行去重,将去重后的结果写入redis和Habse
1.1 pom文件
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-sparkartifactId>
<version>4.14.2-HBase-1.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.3.1version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.3.1version>
dependency>
dependencies>
1.2 config配置:
# Kafka配置
kafka.broker.list=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka.group=guochao
# Redis配置
redis.host=hadoop102
redis.port=6379
zooleeper.list=hadoop102:2181,hadoop103:2181,hadoop104:2181
1.3 properties解析工具类
object PropertiesUtil {
private val in: InputStream = ClassLoader.getSystemResourceAsStream("config.properties")
private val pro = new Properties()
pro.load(in);
// 获取对应的value的值
def getPropertiesValue(propertiesName:String)={
pro.getProperty(propertiesName)
}
}
1.4 HbaseUtil工具类
object HbaseUtil {
//连接hbase
def getConnection: Connection ={
val configuration = HBaseConfiguration.create()
configuration.set("hbase.zookeeper.quorum",PropertiesUtil.getPropertiesValue("zooleeper.list"))
ConnectionFactory.createConnection(configuration)
}
}
1.5 kafkaUtil根据指定的topic返回对应的Dstream
/**
* 创建Kafka 数据源 从指定的topic 消费数据 返回DStream
*/
object MyKafkaUtils {
//从kafka 指定的topic 中消费数据
def getDstreamFromKafka(ssc:StreamingContext, topic:String): InputDStream[(String, String)] ={
val kafkaParams: Map[String, String] = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG->PropertiesUtil.getPropertiesValue("kafka.broker.list"),
ConsumerConfig.GROUP_ID_CONFIG->PropertiesUtil.getPropertiesValue("kafka.group")
)
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc,
kafkaParams,
Set(topic)
)
}
}
1.6 jedisUtils从连接池中获取Jedis连接实例
object JedisUtils {
private val jedisPoolConfig: JedisPoolConfig = new JedisPoolConfig()
jedisPoolConfig.setMaxTotal(100) //最大连接数
jedisPoolConfig.setMaxIdle(20) //最大空闲
jedisPoolConfig.setMinIdle(20) //最小空闲
jedisPoolConfig.setBlockWhenExhausted(true) //忙碌时是否等待
jedisPoolConfig.setMaxWaitMillis(500) //忙碌时等待时长 毫秒
jedisPoolConfig.setTestOnBorrow(false) //每次获得连接的进行测试
private val jedisPool: JedisPool = new JedisPool(jedisPoolConfig, "hadoop102", 6379)
// 直接得到一个 Redis 的连接
def getJedisClient: Jedis = {
jedisPool.getResource
}
}
1.7 样例类
package com.gc.bean
case class StartupLog(mid: String,
uid: String,
appId: String,
area: String,
os: String,
channel: String,
logType: String,
version: String,
ts: Long,
var logDate: String,
var logHour: String)
二 Spark直接将数据写入Hbase
package com.gc.app
import java.text.SimpleDateFormat
import java.util
import java.util.Date
import com.alibaba.fastjson.JSON
import com.gc.bean.StartupLog
import com.gc.util.{ConstantParam, HbaseUtil, JedisUtils, MyKafkaUtils}
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.client.{Put, Table}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
/**
* 统计日活(启动日志)
* 一个用户当天首次登陆算一个活跃用户
*
*/
object DauApp {
def main(args: Array[String]): Unit = {
//创建StreamingContext 对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("DauApp")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
// 消费kafka中的实时数据流
val kafkaSource: InputDStream[(String, String)] = MyKafkaUtils.getDstreamFromKafka(ssc,ConstantParam.START_LOG)
//处理数据 封装样例类
val logDstream = kafkaSource.map({
case (_, value) => {
//将数据解析为json
val log: StartupLog = JSON.parseObject(value, classOf[StartupLog])
log.logDate = new SimpleDateFormat("yyyy-MM-dd").format(new Date())
log.logHour = new SimpleDateFormat("HH").format(new Date())
log
}
})
// 借助redis 对数据进行去重 将数据转换成RDD进行操作
// 创建连接查询出Redis 中的数据 并将数据进行广播
val client = JedisUtils.getJedisClient
val set: util.Set[String] = client.smembers(s"gmall:start:dau:${new SimpleDateFormat("yyyy-MM-dd").format(new Date())}")
client.close()
val sscBd: Broadcast[util.Set[String]] = ssc.sparkContext.broadcast(set) // 广播变量
val filterDstream: DStream[StartupLog] = logDstream.transform(rdd => {
rdd.filter(log => {
!sscBd.value.contains(log.mid) // 如果在redis中不存在则为当天首次活跃用户
})
})
// 将数据写入redis 维护活跃设备Id
filterDstream.foreachRDD(rdd=>{
rdd.foreachPartition(it=>{
// 创建jedis 连接
val client = JedisUtils.getJedisClient
// 遍历写入数据 借助set
it.foreach(log=>{
client.sadd(s"gmall:start:dau:${log.logDate}",log.mid) //按照设备Id进行去重
})
//关闭连接
client.close()
})
})
// 将去重后的结果写入到hbase中
filterDstream.foreachRDD(rdd=>{
rdd.foreachPartition(it=>{
//创建hbase的连接
var putList=ListBuffer[Put]();
val conn = HbaseUtil.getConnection
val table: Table = conn.getTable(TableName.valueOf("start_log_adu"))
it.foreach(log=>{
val put =new Put(Bytes.toBytes(log.mid))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("uid"),Bytes.toBytes(log.uid))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("appId"),Bytes.toBytes(log.appId))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("area"),Bytes.toBytes(log.area))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("os"),Bytes.toBytes(log.os))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("channel"),Bytes.toBytes(log.channel))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("logType"),Bytes.toBytes(log.logType))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("version"),Bytes.toBytes(log.version))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("ts"),Bytes.toBytes(log.ts))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("logDate"),Bytes.toBytes(log.logDate))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("logHour"),Bytes.toBytes(log.logHour))
putList+=put
})
import scala.collection.JavaConversions._
table.put(putList);
table.close()
conn.close()
})
})
ssc.start()
ssc.awaitTermination()
}
}
三 Spark整合Phoenix将数据写入hbase
通过Phoenix创建表:
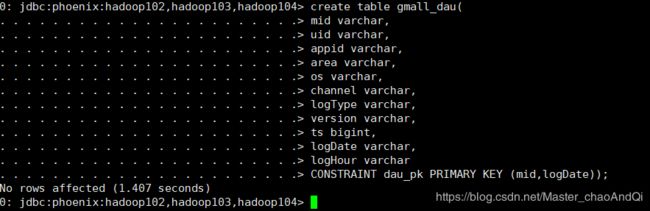
create table gmall_dau(
mid varchar,
uid varchar,
appid varchar,
area varchar,
os varchar,
channel varchar,
logType varchar,
version varchar,
ts bigint,
logDate varchar,
logHour varchar
CONSTRAINT dau_pk PRIMARY KEY (mid,logDate))
column_encoded_bytes=0;
CONSTRAINT dau_pk PRIMARY KEY (mid,logDate)); 以mid和logDate作为主键,在hbase中会进行无缝拼接,拼接成Hbase中的rowkey
saveToPhoenix方法签名
def saveToPhoenix(tableName: String, cols: Seq[String],
conf: Configuration = new Configuration, zkUrl: Option[String] = None, tenantId: Option[String] = None)
: Unit = {
将原直接写入hbase的代码修改为通过Phoenix写入数据到hbase
import org.apache.phoenix.spark._ // 隐式转换
filterDstream.foreachRDD(rdd=>{
rdd.saveToPhoenix(
tableName = "GMALL_DAU", cols=Seq("MID","UID","APPID","AREA","OS","CHANNEL","LOGTYPE","VERSION","TS","LOGDATE","LOGHOUR"),
zkUrl=Some("hadoop102,hadoop103,hadoop104:2181")
)
})
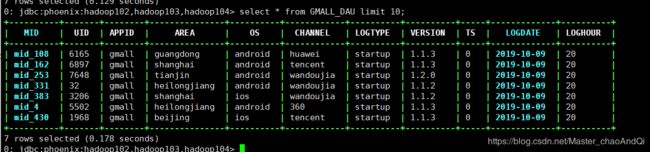
结果:
四遇到的问题
问题1 :Phoenix建表语句大小写问题
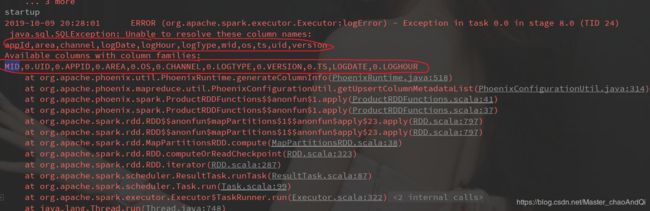
原因:在建表的时候,使用的是小写,phoenix会将建表语句全部改为大写,字段名不匹配,前面的0.Mid中 0 是因为在建表时未指定对应的列族,默认列族为0(如果想使用小写,则需要将表明和字段名用双引号包裹起来)
问题2:jar包冲突
在项目中同时加入了Hbase-client hbase-server phoenix-hbase导致jar包冲突,在使用Phoenix 写入数据的时候,将其它的两个注释掉即可
Caused by: com.google.common.util.concurrent.ExecutionError: java.lang.NoSuchMethodError: com.lmax.disruptor.dsl.Disruptor.(Lcom/lmax/disruptor/EventFactory;ILjava/util/concurrent/ThreadFactory;Lcom/lmax/disruptor/dsl/ProducerType;Lcom/lmax/disruptor/WaitStrategy;)V
at com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2212)
at com.google.common.cache.LocalCache.get(LocalCache.java:4053)
at com.google.common.cache.LocalCache$LocalManualCache.get(LocalCache.java:4899)
at org.apache.phoenix.jdbc.PhoenixDriver.getConnectionQueryServices(PhoenixDriver.java:241)
at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver.createConnection(PhoenixEmbeddedDriver.java:147)
at org.apache.phoenix.jdbc.PhoenixDriver.connect(PhoenixDriver.java:221)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:208)
at org.apache.phoenix.mapreduce.util.ConnectionUtil.getConnection(ConnectionUtil.java:113)
at org.apache.phoenix.mapreduce.util.ConnectionUtil.getOutputConnection(ConnectionUtil.java:97)
at org.apache.phoenix.mapreduce.util.ConnectionUtil.getOutputConnection(ConnectionUtil.java:92)
at org.apache.phoenix.mapreduce.util.ConnectionUtil.getOutputConnection(ConnectionUtil.java:71)
at org.apache.phoenix.mapreduce.util.PhoenixConfigurationUtil.getUpsertColumnMetadataList(PhoenixConfigurationUtil.java:306)
at org.apache.phoenix.spark.ProductRDDFunctions$$anonfun$1.apply(ProductRDDFunctions.scala:41)
at org.apache.phoenix.spark.ProductRDDFunctions$$anonfun$1.apply(ProductRDDFunctions.scala:37)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:797)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:797)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
... 3 more
问题3 redis 强制退出问题
MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
强制关闭Redis快照导致不能持久化。
连接上redis客户端设置如下参数
config set stop-writes-on-bgsave-error no