python+LeNet+mnist手写数字识别+gpu运行
卷积神经网络可谓是现在深度学习领域中大红大紫的网络框架,尤其在计算机视觉领域更是一枝独秀。CNN从90年代的LeNet开始,21世纪初沉寂了10年,直到12年AlexNet开始又再焕发第二春,从ZF Net到VGG,GoogLeNet再到ResNet和最近的DenseNet,网络越来越深,架构越来越复杂。详细的介绍可以看这儿CNN网络架构演进:从LeNet到DenseNet
LeNet是整个卷积神经网络的开山之作,1998年由LeCun提出,它的结构简单。研究透它可以很好的理解神经网络结构原理。
首先就是,LeNet的网络结构如图所示
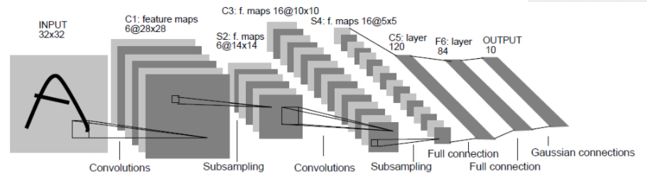
LeNet 一共有7层,分别是《卷积层--池化层--卷积层--池化层--全连接层--全连接层--全连接层》如下图所示

LeNet的pytorch代码如下:带#注释的代码是gpu运行.
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import torch.utils.data as Data
import torchvision
EPOCH=1
BATCH_SIZE=50
LR=0.01
DOWNLOAD_MNIST = False
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
#test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255.
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255.
#test_y = test_data.test_labels[:2000].cuda()
test_y = test_data.test_labels[:2000]
#查看下载的mnist数据集
#print(train_data.train_data.size())#训练集的大小[60000,28,28]
#print(test_data.test_data.size())#测试集的大小
#print(test_data.test_labels[0])#测试集的第一个标签
#plt.imshow(train_data.train_data[2],cmap='gray')#训练集的第三张图片
#搭建网络
class _LeNet(nn.Module):
def __init__(self):
super(_LeNet,self).__init__()#输入是28*28*1
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=5,stride=1,padding=2),#28*28*16
nn.MaxPool2d(kernel_size=2),#14*14*16
)
self.conv2=nn.Sequential(
nn.Conv2d(in_channels=16,out_channels=32,kernel_size=5,stride=1,padding=2),#14*14*32
nn.MaxPool2d(kernel_size=2),#7*7*32
)
self.linear1=nn.Linear(7*7*32,120)
self.linear2=nn.Linear(120,84)
self.out=nn.Linear(84,10)
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0),-1)
x=self.linear1(x)
x=self.linear2(x)
output=self.out(x)
return output
cnn=_LeNet()
#cnn.cuda()
#print(cnn)
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
loss_func=nn.CrossEntropyLoss()
#训练过程,train_loader加载训练数据
for epoch in range(EPOCH):
for step,(x,y) in enumerate(train_loader):
#c_x=x.cuda()
c_x=x
#c_y=y.cuda()
c_y=y
output=cnn(c_x)
loss=loss_func(output,c_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#########训练到此结束##########
if step%50==0:
test_out=cnn(test_x)
#pred_y = torch.max(test_out, 1)[1].cuda().data
pred_y = torch.max(test_out, 1)[1].data
accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
#print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy(), '| test accuracy: %.2f' % accuracy)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
#pred_y = torch.max(test_output, 1)[1].cuda().data
pred_y = torch.max(test_output, 1)[1].data
print(pred_y, 'prediction numbe')
print(test_y[:10], 'real number')
1、输入图片是28*28*1,第一层卷积conv1,输入是一张图片,输出是16张图片(采集的不同特征),卷积核大小是5*5,滑动步幅1个像素,padding是2,padding的详细解释吴恩达-深度学习-卷积神经网络-Padding 笔记。输出的大小是28*28*16
2、第二层是池化,一般常用最大池化Maxpool。kernel=2,就是相当于将上一层的图像缩小2倍。经过这一层图像大小变为
14*14*16
3、第三层卷积。输出的图像大小14*14*32
4、第四层Maxpool,输出大小变为,7*7*32
5、第五层全连接层。即将第四层的特征图变为一维向量,全连接层的输入就是7*7*32 ,输出这儿是120,
6、第六层全连接层。输入是上一层的输出即120,这个输出是84
7、第七层全连接层。输入是上一层的输出即84,这个输出是10(10个分类0-9)
运行代码后截图:

可以看出训练一个epoch后,正确率0.96;训练更多的epoch可以要提高正确率。另外使用GPU后计算速度明显提高。