胖虎的Hadoop笔记——Hadoop的伪分布式部署
胖虎的Hadoop笔记——Hadoop的伪分布式部署
本博客用于Hadoop大数据企业课笔记记录。第三步
一、VMware安装和创建虚拟机
1.VMware安装
安装包下载:https://pan.baidu.com/s/16T72wWtK3zMbAdyfavNGDA
提取码:on8c
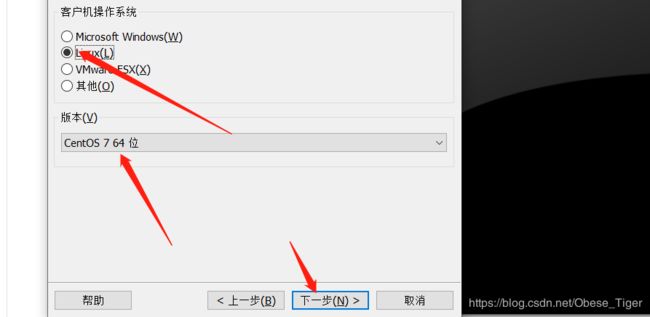
2.创建虚拟机(CentOS7)
下载镜像文件:https://pan.baidu.com/s/16T72wWtK3zMbAdyfavNGDA
提取码:on8c
创建虚拟机,构造配置文件
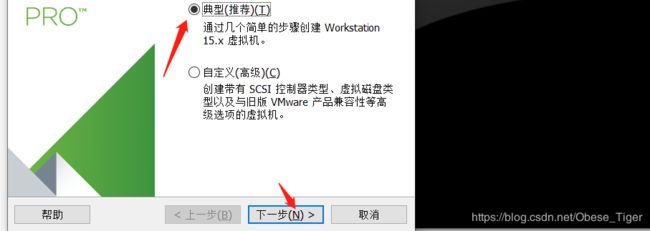



完成后运行此虚拟机。

之后选择安装语言为中文简体

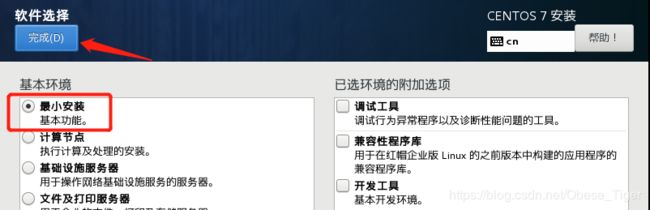
在软件选择里面,下载最小安装就可以:
在网络上设置上:

然后设置用户名和密码,等安装完成后,重启就可以使用了。
二、Hadoop前期环境配置
1.修改普通用户权限
在root用户下进入权限配置文件
vi /etc/sudoers //Esc键 后输入 : 然后输入 wq 最后回车
在文件的指定位置添加普通用户(hadoop)的信息,如下图:

保存退出时,因为文件为只读类型,需要强制保存退出。(Esc键 后输入 : 然后输入 wq!)
此后hadoop用户再需要使用sudo命令时输入密码。
2.修改虚拟机网络
在VM的虚拟网络编辑器查看,网关和IP信息

进入虚拟网络编辑器

记住以下两端IP信息,之后的网络设置需要用到,设置错误将难以连接网络。

修改网络属性
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
将里面的BOOTPROTO属性修改为静态:
BOOTPROTO="static" //将之前的动态分配IP删掉,加入新的
然后添加网络描述信息,将以下内容,追加到末尾:
IPADDR=192.168.232.100 //IP地址前三字段要和之前查到的子网IP前三字段相同,最后一个字段3~254之间任意,不要和其他冲突
NETMASK=255.255.255.0 //子网掩码,将之前查到的添加进去
GATEWAY=192.168.232.2 //网关IP,将之前查到的添加进去
DNS1=8.8.8.8
DNS2=192.168.232.1
重启网络服务
sudo service network restart
下载vim和net-tools,命令如下:
sudo yum install -y vim
sudo yum install -y net-tools
查看网络是否修改好
ifconfig

显示为之前你设置的IP,同时可以ping通网页,表示网络配置成功。
最后将主机名和IP映射:
sudo vim /etc/hosts
将原有的内容注释掉,添加IP和主机名,如下图所示:

3.设置SSH免密码登录
输入以下命令:
ssh-keygen -t rsa
之后输入多次回车键,直到结束。然后输入如下命令:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
sudo chmod 600 authorized_keys
尝试ssh连接
ssh hadoop@hadoop000 //询问就输入yes
登录后,输入exit退出。表示ssh免密码登录完成。
4.关闭虚拟机的防火墙
输入以下命令关闭防火墙,并设置为开机不启动,用于后期访问端口时不会被拒绝。
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
查看防火墙状态:
sudo systemctl status firewalld.service

表示防火墙未激活,关闭成功。
三、Hadoop安装和JDK安装
1.下载Hadoop和JDK的压缩包并解压
Hadoop下载:https://archive.apache.org/dist/hadoop/common/
JDK下载:https://www.oracle.com/java/technologies/oracle-java-archive-downloads.html
- 将下载好的压缩包拷贝到虚拟机里

- 在
/home/hadoop目录下创建一个名字为app的文件夹,并把JDK和Hadoop解压到里面
mkdir /home/hadoop/app
tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/app
tar -zxvf hadoop-2.7.3.tar.gz -C ~/app
2.配置环境变量
vim ~/.bash_profile
根据你自己本身下载的版本和目录,配置以下路径:
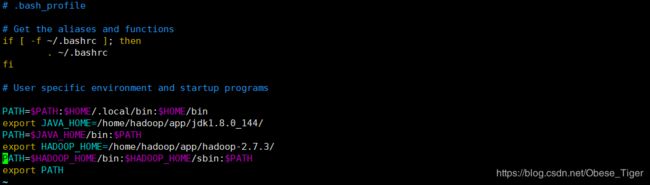
代码为:
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144/
PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/home/hadoop/app/hadoop-2.7.3/
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
四、配置Hadoop的集群文件
所有的配置文件都在解压后的hadoop文件夹下的/hadoop/hadoop-2.7.3/etc/hadoop/目录里。
cd /home/hadoop/hadoop/hadoop-2.7.3/etc/hadoop/
1.配置hadoop-env.sh
vim hadoop-env.sh
将里面的JAVA_HOME修改成绝对路径的地址,下图为改好的结果:

2.配置core-site.xml
vim core-site.xml
将以下内容添加到之间:
fs.defaultFS</name>
hdfs://hadoop:9000</value>
</property>
hadoop.tmp.dir</name>
/home/hadoop/app/tmp</value>
</property>
保存退出后,在hadoop的用户目录下创建/home/hadoop/app/tmp文件夹结构。
mkdir ~/app/tmp
3.配置hdfs-site.xml
vim hdfs-site.xml
将以下内容添加到之间:
dfs.replication</name>
1</value>
</property>
dfs.permissions</name>
false</value>
</property>
4.配置mapred-site.xml
cp mapred-site.xml.template mapred-site.xml //根据模板生成配置文件
vim mapred-site.xml
将以下内容添加到之间:
mapreduce.framework.name</name>
yarn</value>
</property>
5.配置yarn-site.xml
vim yarn-site.xml
将以下内容添加到之间:
yarn.resourcemanager.hostname</name>
hadoop</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
五、启动Hadoop集群并测试
1.启动Hadoop集群
格式化集群
hdfs namenode -format
启动集群
start-all.sh
输入jps指令,当返回5个组件状态时,表示hadoop配置成功。
2.测试Hadoop集群 —— Hello World
1.在/home/hadoop目录下创建一个名字为data的文件夹
mkdir ~/data
在data文件夹内创建一个txt格式的文件,在里面输入若干单词,用空格和回车相互隔开,并保存。

2.在hadoop里面创建文件夹,并上传之前的txt文件。
hadoop fs -mkdir ./input
hadoop fs -put word.txt ./input
3.通过hadoop集群统计出各个单词的数量。
cd ~/app/hadoop-2.7.3/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/word.txt /output
4.查看统计结果。
hadoop fs -cat /output/part-r-00000
当集群不需要使用时,停止集群
stop-all.sh