JAVA并发编程的艺术学习笔记 第6章 Java并发容器和框架
Java中提供的各种比方容器和框架, 分析了容器和框架的实现原理。
1. ConcurrentHashMap
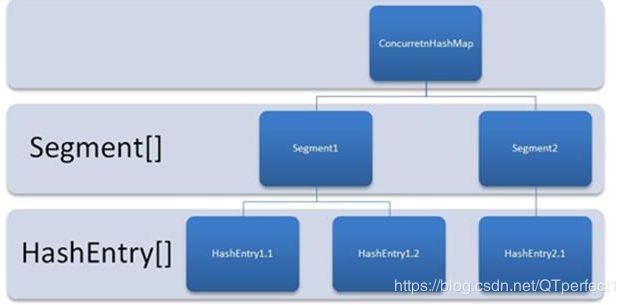
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
ConcurrentHashMap初始化方法是通过initialCapacity默认初始容量,loadFactor加载因子, concurrencyLevel并发级别,几个参数来初始化。
segments数组的长度ssize通过concurrencyLevel计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14,15或16,ssize都会等于16,即容器里锁的个数也是16。
ConcurrentHashMap的get操作
Segment的get操作实现非常简单和高效。先经过一次再哈希,然后使用这个哈希值通过哈希运算定位到segment,再通过哈希算法定位到元素。
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空(空代表这个值被移除了,因为ConcurrentHashMap设计的不允许存储null)的才会加锁重读,我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。
ConcurrentHashMap的Put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put方法首先定位到Segment,然后在Segment里进行插入操作。
ConcurrentHashMap的size操作
如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count(HashMap是整个HashMap维护一个count,而ConcurrentHashMap是每个桶维护一个)是一个volatile变量,那么在多线程场景下,我们可以直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小,虽然相加时可以获取每个Segment的count的最新值,但是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
2. Fork/Join框架介绍
什么是Fork/Join框架
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
我们再通过Fork和Join这两个单词来理解下Fork/Join框架,Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+。。+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果
子问题中应该避免使用synchronized关键词或其他方式方式的同步。也不应该是一阻塞IO或过多的访问共享变量。在理想情况下,每个子问题的实现中都应该只进行CPU相关的计算,并且只适用每个问题的内部对象。唯一的同步应该只发生在子问题和创建它的父问题之间。
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
具体使用
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask :用于有返回结果的任务。
ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
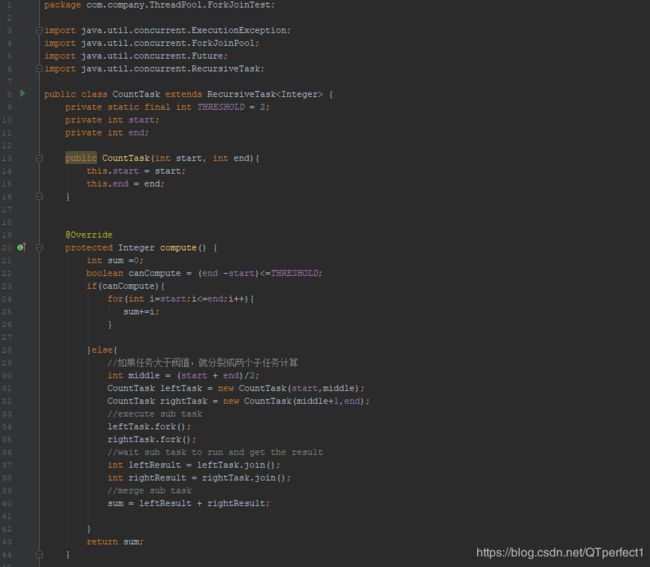
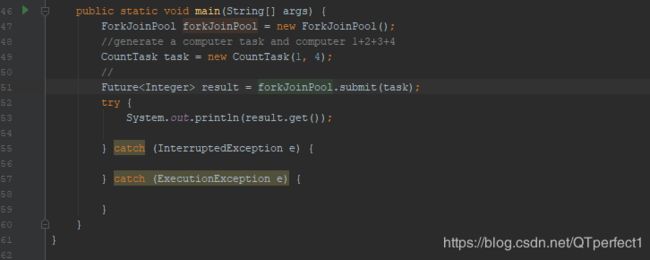
让我们通过一个简单的需求来使用下Fork/Join框架,需求是:计算1+2+3+4的结果。
使用Fork/Join框架首先要考虑到的是如何分割任务,如果我们希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是4个数字相加,所以Fork/Join框架会把这个任务fork成两个子任务,子任务一负责计算1+2,子任务二负责计算3+4,然后再join两个子任务的结果。
因为是有结果的任务,所以必须继承RecursiveTask,实现代码如下: