Deep Memory Network 深度记忆网络
RNN解决长期依赖的能力随着文本长度的增加越来越差,attention机制是解决这种问题的一种思路,今天我们再来看另外一种思路,深度记忆网络。Deep Memory Network在QA和Aspect based Sentiment等NLP领域都有过成功的实践,但其提出者本身是以通用模型的形式提出的。
Introduce of Memory Network
Memory Network是一种新的可学习模型,它使用一个整合了长期记忆的一个组件(称为Memory)作为推断组件(inference components)来进行推理。长期记忆Memory可以被读和写,以实现预测的最终目的。原论文作者认为RNN的记忆问题(无法完成简单的复制任务,即将输入原样输出)也可以被Memory Network解决。它核心思想来自机器学习文献中成功应用的使用外置的可读写的记忆模块来进行推断。
Memory Networks
一个记忆网络是由一个记忆 m m m(一个以 m i m_i mi作为索引的数组对象)和4个组件 I , G , O , R I,G,O,R I,G,O,R组成。其中:
- I:(input feature map) - 将输入转化为中间特征表示。
- G:(Generalization) - 给定新输入的条件下更新旧记忆。原作者称之为泛化,因为网络在该阶段有机会将记忆压缩和泛化以供后面使用。
- O:(Output feature map) - 给定新输入和当前记忆状态,产生一个新的输出(在特征表示空间上)。
- R:(Response) - 将output(即O)转化到目标形式(例:一个文本的回复或者一个动作)
Memory Networks的处理过程
给定一个输入x(例:字符、词或者句子(视处理力度而定),图像或者声音信号),模型处理过程如下:
- 将x转化为中间特征表示 I ( x ) I(x) I(x)。
- 使用新输入更新记忆 m i m_i mi: m i = G ( m i , I ( x ) , m ) , ∀ i m_i=G(m_i, I(x), m), \forall i mi=G(mi,I(x),m),∀i
- 使用新输入的中间特征表示和记忆计算输出特征 o o o: o = O ( I ( x ) , m ) o=O(I(x), m) o=O(I(x),m)
- 最后,解码输出特征到最终回复: r = R ( o ) r=R(o) r=R(o)
这个过程在训练和测试时都适用,两者之间的区别在于:测试时记忆也会被存储,但模型参数 I , G , O , R I,G,O,R I,G,O,R将不会再更新。 I , G , O , R I,G,O,R I,G,O,R可以使用现有任何机器学习的方法来实现(SVM, 决策树)。
组件 I I I: I I I可以使用标准的预处理步骤来实现,比如输入文本的语法分析、指代消解、实体识别等。它同样也可以将输入编码到一个中间的特征表示(将文本转化为稀疏或者稠密的特征向量)。
组件 G G G: 最简单的G的形式可以是将 I ( x ) I(x) I(x)储存起来的槽位(slot):
m H ( x ) = I ( x ) m_{H(x)}=I(x) mH(x)=I(x)
其中 H ( x ) H(x) H(x)是选择槽位的一个函数。即, G G G只更新m的索引 H ( x ) H(x) H(x),其他索引下的记忆部分将保持不变。更复杂的 G G G的实现还可以允许 G G G去根据当前输入x得到的新证据去更新先前存储的记忆。如果输入是字符级别或者词级别的你也可以将其进行分组。
如果记忆非常庞大(假设要记忆整个Freebase或者Wikipedia),你可能不得不把记忆使用 H ( x ) H(x) H(x)来组织起来。
如果记忆已经被填满。你也可以使用 H H H来实现一种遗忘机制。
O O O和 R R R组件: O O O组件被特别应用于读取记忆和执行推断, R R R组件则根据 O O O的输出产生最终回复。例:在QA中,使用 O O O查找相关的记忆,然后 R R R生成文字来组成答案。 R R R可以是RNN,视 O O O的输出而定。这种设计基于的假设是,如果没有限定在这种记忆上,RNN会表现得相当差(事实上很多场景下确实如此)。
原论文给了一个QA的例子,但由于这个模型并没有广泛使用这里就不介绍了。我们转而介绍一种常用的端到端的记忆网络实现。
End-To-End Memory Network
端到端的记忆网络本质上也是一种RNN架构,但与RNN不同之处在于,在递归过程中会多次读取大型外部存储的记忆来输出一个符号。下面介绍的Memory Network可以有很多层,也易于反向传播,需要对网络的每一层进行监督训练。它以端到端的形式被应用于QA和Aspect Based Sentiment。
模型将一系列离散的输入 x i , . . . , x n x_i,...,x_n xi,...,xn存储在记忆中,并接受一个查询 q q q,输出回答 a a a。模型会将所有的 x x x写为记忆存储在一个固定大小的缓存中,然后寻求一个 x x x和 q q q的连续表示。该连续表示会被多跳处理以输出a。这使得错误信号能够在多级记忆中反向传播到输入。
Single Layer
整个模型是很多层堆起来的,我们先介绍单个层。
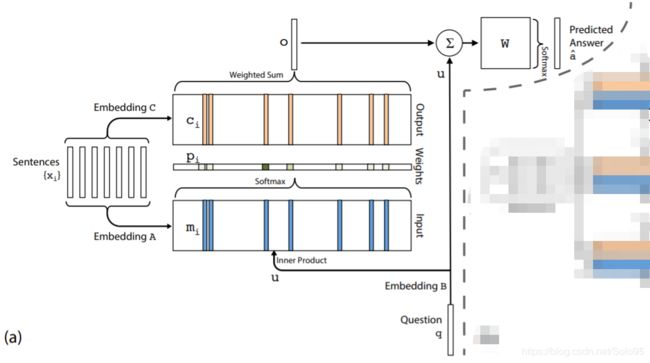
输入记忆表示(Input memory representation):假定我们被给定输入集 x 1 , . . . , x i x_1,...,x_i x1,...,xi存储在记忆中。整个输入集 x i {x_i} xi都会经由每个 x i x_i xi所处的连续空间的嵌入(embedding)被转化为维度为 d d d的记忆向量 m i {m_i} mi,最简单的实现方法可以使用一个嵌入矩阵 A ( d × V ) A(d\times V) A(d×V),查询 q q q也会被嵌入,可以用维度与 A A A相同的嵌入矩阵 B B B来得到一个中间状态 u u u,在嵌入空间上,我们使用内积计算 u u u和记忆 m i m_i mi的匹配程度,然后再softmax:
p i = S o f t m a x ( u T m i ) ( 1 ) p_i=Softmax(u^Tm_i) \ (1) pi=Softmax(uTmi) (1)
输出记忆表示(Output memory representation):每一个 x i x_i xi都有一个相关的输出向量 c i c_i ci(最简单的情况下使用另外的嵌入矩阵 C C C)。自记忆 o o o产生的回复向量通过使用自输入产生的概率向量 p i p_i pi与转化后的 c i c_i ci加权求和得到:
o = ∑ i p i c i o=\sum_ip_ic_i o=i∑pici
产生最终预测:在单层的情况下,输出向量 o o o的和输入嵌入 u u u求和再乘上一个最终的权重矩阵 W W W,然后经过softmax产生预测标签:
a ^ = S o f t m a x ( W ( o + u ) ) \hat{a}=Softmax(W(o+u)) a^=Softmax(W(o+u))
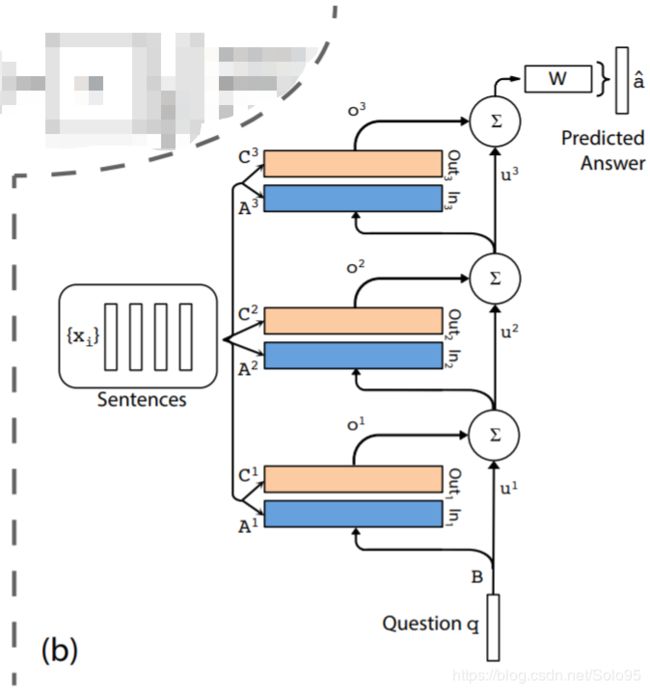
Multi Layers
模型可以扩展到处理K跳操作。记忆层是以如下方式进行堆积的:
- 下一层的input由上一层的输出 o k o^k ok和输入 u k u^k uk求和得来:
u k + 1 = u k + o k u^{k+1}=u^k+o^k uk+1=uk+ok - 每一层都有自己的嵌入矩阵 A k , C k A^k, C^k Ak,Ck,本用于对输入 x i {x_i} xi进行嵌入。但是,这些矩阵被限制在易于训练并且能减少参数的数量的程度。
- 在网络顶层, W W W对应的输入同样组合了输入和记忆层顶层的输出:
a ^ = S o f t m a x ( W u K + 1 ) = S o f t m a x ( W ( o K + u K ) ) \hat{a}=Softmax(Wu^{K+1})=Softmax(W(o^K+u^K)) a^=Softmax(WuK+1)=Softmax(W(oK+uK))
原论文探索了两种类型的权重捆绑:
- 邻接(Adjacent):一个层输出的嵌入是下一层的输入,即: A k + 1 = C K A^{k+1}=C^K Ak+1=CK,作者同样也限制: (a)回答预测矩阵要和最终的输出嵌入相同,即: W T = C K {W^T=C^K} WT=CK。(b)问题嵌入和第一层的输入嵌入相同,即 B = A 1 B=A^1 B=A1
- 层级别(Layer-wise,类RNN):层与层之间共享输入个输出嵌入,即:
A 1 = A 2 = . . . = A K A^1=A^2=...=A^K A1=A2=...=AK且 C 1 = C 2 = . . . = C K C^1=C^2=...=C^K C1=C2=...=CK。作者发现在层间加上一个线性的映射函数 H H H非常有用,即 u k + 1 = H u k + o k u^{k+1}=Hu^k+o^k uk+1=Huk+ok。H同样也是被学习的参数和其他参数一起更新。
在使用层级别权重捆绑的情况下,Deep Memory Network某种程度上退化到了RNN,这一点读者可以仔细体会一下。
参考文献
- MEMORY NETWORKS (ICLR 2015)
- End-To-End Memory Networks (NIPS 2015)