论文浅尝 | 机器阅读理解中常识知识的显式利用
论文笔记整理:吴林娟,天津大学硕士,自然语言处理方向。
 链接:https://arxiv.org/pdf/1809.03449.pdf
链接:https://arxiv.org/pdf/1809.03449.pdf
动机
机器阅读理解(MRC)和人类进行阅读理解之间还存在差距,作者认为主要体现在对于数据的需求和噪声鲁棒性上,人类往往拥有大量的常识性知识,从短文中就能进行深刻的阅读理解。所以在文章中,作者探索了如何将MRC模型的神经网络与常识相结合,并基于常识数据的扩展,实现了一个端到端的知识辅助阅读器(KAR)机器阅读模型。KAR在性能上可与最新的MRC模型相媲美,并且在噪声方面具有更强的鲁棒性。当只有一部分训练样本(20%–80%)可用时,KAR能大大超越最新的MRC模型,并且仍具有相当强的抗噪能力。
亮点
(1)提出了一个数据丰富的方法,作者使用WordNet从每个给定的段落-问句对中提取词间语义联系作为常识。题目中之所以叫常识知识的显式使用,是作者探索的一种和目前把常识编码后增强单词或上下文表示的形式不同的方法,对常识知识的使用更好理解和控制。
(2)作者提出了一个名为知识辅助阅读器(KAR)的端到端MRC模型,该模型使用提取到的常识来辅助其注意机制,增强模型的阅读理解能力,削弱噪声的影响。实验证明了模型的先进性。
方法及模型
数据丰富的方法
主要是基于WordNet从每个给定的段落-问句对中提取词间语义联系作为常识数据提供给MRC模型。
1、语义关系链
WordNet是英语的词汇数据库,其中单词根据其含义被组织为同义词集,同义词集通过语义关系进一步相互关联,总共有十六种语义关系类型(例如,上位词,下位词,全称,副词,属性等)。基于同义词集和语义关系,作者定义了一个新概念:语义关系链。
语义关系链是语义关系的级联序列,它将一个同义词集链接到另一个同义词集。
例如,同义词集“keratin.n.01”通过语义关系“substance holonym”与同义词集“feather.n.01”相关,同义词集“ feather.n.01”通过语义关系“partholonym”与同义词集“ bird.n.01”相关,而同义词集“bird.n.01”通过语义关系“ hyponym”与同义词集“parrot.n.01”相关,因此“ substance holonym -> part holonym-> hyponym”是一条语义关系链,将同义词集“ keratin.n.01”链接到同义词集“ parrot.n.01”。文中将语义关系链中的每个语义关系命名为一跳,因此上述语义关系链是3跳链,每个单独的语义关系都等效于1跳链。
2、词间语义连接
给定一个词 ω,同义词集表示为 Sω,同义词集 Sω 以及从 Sω 可以用语义关系链扩展到的其他同义词集共同组成 S*ω,如果对语义关系链没有限制的话 S*ω 将拥有所有同义词集这是没有意义的,所以作者提出了:当且仅当 Sω1^* (k)∩Sω2≠∅,单词ω1才与另一个单词ω2语义连接,k表示语义关系链的最大允许跳数。
3、常识知识提取
结合文章的模型,作者仅提取了词间语义连接的位置信息,并设置超参数来控制提取结果的数量。如果将其设置为0,则单词间语义连接将仅存在于同义词之间;如果增加,更多词之间将存在词间语义联系。但是,由于自然语言的复杂性和多样性,提取的结果中只有一部分可以用作有用的常识,而其余部分对于预测答案范围则毫无用处,所以参数不可设置太大。
知识辅助阅读器
KAR模型主要由五层构成:词典嵌入层、上下文嵌入层、粗记忆层、精记忆层、答案跨度预测层。

1、知识辅助的相互关注
作为粗记忆层的一部分,知识辅助的相互关注旨在将问题上下文嵌入 C_Q融合到段落上下文嵌入 C_p 中,关键问题是计算每个段落上下文嵌入 c_pi 和问题上下文嵌入 c_qj 之间的相似度:
![]()
带*号的向量是指经过了之前提取的常识知识加强之后的向量。基于以上相似度函数和增强的上下文嵌入,为执行知识辅助的相互关注,首先作者构建了知识辅助的相似度矩阵A,其中A_(i,j)=f^*(C_pi, c_qj)。关注段落的问题总表示R_Q和关注问题的段落总表示R_p为:
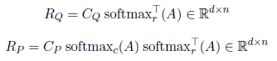
最后经过具有ReLU激活的稠密层把 C_p,C_Q,C_P⨀C_Q 和 R_P⨀R_Q 串联,得到输出G ̃∈R^(d×n)。
2、知识辅助的自我注意
作为精记忆层的一部分,知识辅助的自我关注旨在将粗记忆层G融合到自身中。作者使用预先提取的常识来确保每个段落词的粗记忆融合仅涉及其他段落词的精确子集。特别的,对于每个段落词 p_i,粗记忆是g_pi,提取到的常识集合为E_pi,通过搜集G的列(索引由E_pi给出)可以获匹配的粗记忆,然后构造一个g_pi参与的Z总表示,可以获得匹配的向量 g_(pi)^+:
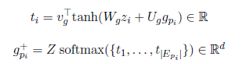
最后经过具有ReLU激活的稠密层把g_pi和g_(pi)^+串联,获得融合结果 h_pi,输出为 H={h_p1, h_p2,..., h_pn}。
实验
作者将KAR需要与其他MRC模型的性能和抗噪性进行比较,具体来说,不仅需要评估开发集和测试集上KAR的性能,还要评估对抗集上的性能。所以主要和以下五个模型进行了比较:
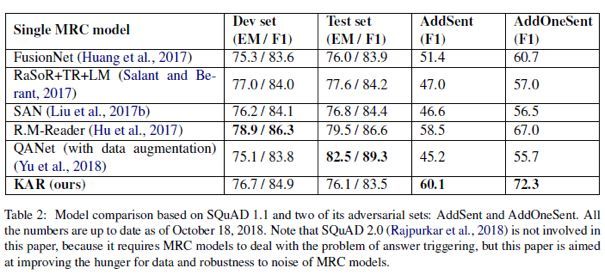
在开发集和测试集上,KAR的性能与最新的MRC模型相当。在对抗集上,KAR大大优于最新的MRC模型。 也就是说,KAR在性能上可与最新的MRC模型相媲美,并且在噪声方面比它们具有更强的鲁棒性。
作者分析了模型表现优良的原因:
1、KAR旨在利用数据丰富方法中预先提取的词间语义连接。某些词间语义连接,尤其是通过多跳语义关系链获得的词间语义连接,对于预测答案范围非常有用。
2、从段落-问题对中提取的词间语义联系通常也会出现在许多其他段落-问题对中,因此从少量训练示例中提取的词间语义联系很可能实际上覆盖了更大的培训示例。
3、一些单词间的语义联系分散了对答案范围的预测。例如,鉴于上下文“银行经理正沿着水边走”,“银行”和“水边”之间的词间语义联系毫无意义。正是知识辅助的注意力机制使KAR能够忽略这种分散注意力的词间语义联系,从而仅使用重要的语义联系。
总结
在文章中,作者创新地将MRC模型的神经网络与人类的常识相结合。实验结果表明KAR的端到端的MRC模型的效果很好,文章提出的使用WordNet进行常识知识的显式使用来提高MRC模型性能和鲁棒性确实是一个不错的思路。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。