SVM之目标函数求解
经过前面几篇文章的介绍,我们知道了支持向量机背后的原理。同时,为了求解SVM中的目标函数,我们还在前面两篇文章中陆续介绍了拉格朗日乘数法和对偶性问题。接下来,在这篇文章中将开始正式介绍SVM的求解过程。
1 构造广义拉格朗日函数 L ( w , b , α ) \mathcal{L}(w,b,\alpha) L(w,b,α)
由 前文可知SVM最终的优化目标为:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y ( i ) ( w T x ( i ) + b ) ≥ 1 , i = 1 , 2 , . . . m (1) \begin{aligned} &\min_{w,b} \frac{1}{2}{||w||^2}\\[1ex] &s.t.\;\;y^{(i)}\large(w^Tx^{(i)}+b)\geq1,i=1,2,...m \end{aligned}\tag{1} w,bmin21∣∣w∣∣2s.t.y(i)(wTx(i)+b)≥1,i=1,2,...m(1)
由此我们可以得到广义的拉格朗日函 数为:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i [ y ( i ) ( w T x ( i ) + b ) − 1 ] (2) \begin{aligned} &\mathcal{L}(w,b,\alpha)=\frac{1}{2}||w||^2-\sum_{i=1}^m\alpha_i\large[y^{(i)}(w^Tx^{(i)}+b)-1] \end{aligned}\tag{2} L(w,b,α)=21∣∣w∣∣2−i=1∑mαi[y(i)(wTx(i)+b)−1](2)
且同时记:
g i ( w ) = − y ( i ) ( w T x ( i ) + b ) + 1 ≤ 0 (3) g_i(w)=-y^{(i)}(w^Tx^{(i)}+b)+1\leq0\tag{3} gi(w)=−y(i)(wTx(i)+b)+1≤0(3)
由对偶性:
d ∗ = max α , α i ≥ 0 min w , b L ( w , b , α ) = min w , b max α , α i ≥ 0 L ( w , b , α ) = p ∗ (4) d^*=\max_{\alpha,\alpha_i\geq0}\min_{w,b}\mathcal{L}(w,b,\alpha)=\min_{w,b}\max_{\alpha,\alpha_i\geq0}\mathcal{L}(w,b,\alpha)=p^*\tag {4} d∗=α,αi≥0maxw,bminL(w,b,α)=w,bminα,αi≥0maxL(w,b,α)=p∗(4)
可知,对偶问题 d ∗ d^* d∗与原始问题 p ∗ p^* p∗同解需满足KKT条件:
{ α i ≥ 0 ; g i ( w , b ) ≤ 0 ; α i g i ( w , b ) = 0 (5) \begin{aligned} \begin{cases} \alpha_i\geq0;\\[2ex]g_i(w,b)\leq0;\\[2ex]\alpha_ig_i(w,b)=0\end{cases} \end{aligned}\tag{5} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧αi≥0;gi(w,b)≤0;αigi(w,b)=0(5)
于是,对于任意训练样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)),总有 α i = 0 \alpha_i=0 αi=0或者 α i g i ( w , b ) = 0 \alpha_ig_i(w,b)=0 αigi(w,b)=0。若 α i = 0 \alpha_i=0 αi=0,由下面式子 ( 6 ) (6) (6)中 w w w的解析式可知,超平面为 0 x + b = 0 0x+b=0 0x+b=0,这就意味着 α i = 0 \alpha_i=0 αi=0所对应的样本点与决策面无关;若 α i > 0 \alpha_i>0 αi>0,由式子 ( 3 ) ( 5 ) (3)(5) (3)(5)可知则必有 y ( i ) ( w T x ( i ) + b ) = 1 y^{(i)}(w^Tx^{(i)}+b)=1 y(i)(wTx(i)+b)=1,也就是说该样本点是一个支持向量。这显示出一个重要性质:超平面仅仅与支持向量有关。
2 关于参数 w , b w,b w,b,求 L \mathcal{L} L的极小值 W ( α ) W(\alpha) W(α)
这一步同拉格朗日乘数法求极值一样,分别对 w , b w,b w,b求偏导,并令其为0:
∂ L ∂ w = w − ∑ i = 1 m α i y ( i ) x ( i ) = 0 ; w = ∑ i = 1 m α i y ( i ) x ( i ) ∂ L ∂ b = ∑ i = 1 m α i y ( i ) = 0 (6) \begin{aligned} \frac{\partial \mathcal{L}}{\partial w}&=w-\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}=0;\\[1ex] w&=\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}\\[1ex] \frac{\partial \mathcal{L}}{\partial b}&=\sum_{i=1}^m\alpha_iy^{(i)}=0 \end{aligned}\tag{6} ∂w∂Lw∂b∂L=w−i=1∑mαiy(i)x(i)=0;=i=1∑mαiy(i)x(i)=i=1∑mαiy(i)=0(6)
在此,我们便得到了权重 w w w的解析表达式,而它对于理解SVM中核函数的利用有着重要作用。接着将 ( 6 ) (6) (6)代入 ( 2 ) (2) (2)可得:
W ( α ) = min w , b L ( w , b , α ) = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m y ( i ) y ( j ) α i α j ( x ( i ) ) T x ( j ) (7) \begin{aligned} W(\alpha)=\min_{w,b}\mathcal{L}(w,b,\alpha)=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^my^{(i)}y^{(j)}\alpha_i\alpha_j(x^{(i)})^Tx^{(j)} \end{aligned}\tag{7} W(α)=w,bminL(w,b,α)=i=1∑mαi−21i,j=1∑my(i)y(j)αiαj(x(i))Tx(j)(7)
详细步骤:
L = 1 2 w T w − ∑ i = 1 m α i [ y ( i ) ( w T x ( i ) + b ) − 1 ] = 1 2 w T w − ∑ i = 1 m α i y ( i ) w T x ( i ) − ∑ i = 1 m α i y ( i ) b + ∑ i = 1 m α i = 1 2 w T w − w T ∑ i = 1 m α i y ( i ) x ( i ) − b ∑ i = 1 m α i y ( i ) + ∑ i = 1 m α i (8) \begin{aligned} \mathcal{L}&=\frac{1}{2}w^Tw-\sum_{i=1}^m\alpha_i\large[y^{(i)}(w^Tx^{(i)}+b)-1]\\[1ex] &=\frac{1}{2}w^Tw-\sum_{i=1}^m\alpha_iy^{(i)}w^Tx^{(i)}-\sum_{i=1}^m\alpha_iy^{(i)}b+\sum_{i=1}^m\alpha_i\\[1ex] &=\frac{1}{2}w^Tw-w^T\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}-b\sum_{i=1}^m\alpha_iy^{(i)}+\sum_{i=1}^m\alpha_i\\[1ex] \end{aligned}\tag{8} L=21wTw−i=1∑mαi[y(i)(wTx(i)+b)−1]=21wTw−i=1∑mαiy(i)wTx(i)−i=1∑mαiy(i)b+i=1∑mαi=21wTw−wTi=1∑mαiy(i)x(i)−bi=1∑mαiy(i)+i=1∑mαi(8)
将 ( 6 ) (6) (6)代入 ( 8 ) (8) (8)得
W ( α ) = 1 2 w T w − w T w + ∑ i = 1 m α i = ∑ i = 1 m α i − 1 2 w T w = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) (9) \begin{aligned} W(\alpha)&=\frac{1}{2}w^Tw-w^Tw+\sum_{i=1}^m\alpha_i\\[1ex] &=\sum_{i=1}^m\alpha_i-\frac{1}{2}w^Tw\\[1ex] &=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)}\\[1ex] \end{aligned}\tag{9} W(α)=21wTw−wTw+i=1∑mαi=i=1∑mαi−21wTw=i=1∑mαi−21i,j=1∑mαiαjy(i)y(j)(x(i))Tx(j)(9)
其中:
w T w = ∑ i = 1 m α i y ( i ) x ( i ) ⋅ ∑ j = 1 m α j y ( j ) x ( j ) = ∑ i , j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) = ∑ i = 1 m ∑ j = 1 m α i α j y ( i ) y ( j ) ( x ( i ) ) T x ( j ) (10) \begin{aligned} w^Tw&=\sum_{i=1}^m\alpha_iy^{(i)}x^{(i)}\cdot\sum_{j=1}^m\alpha_jy^{(j)}x^{(j)}\\[1ex] &=\sum_{i,j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)}\\[1ex] &=\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)} \end{aligned}\tag{10} wTw=i=1∑mαiy(i)x(i)⋅j=1∑mαjy(j)x(j)=i,j=1∑mαiαjy(i)y(j)(x(i))Tx(j)=i=1∑mj=1∑mαiαjy(i)y(j)(x(i))Tx(j)(10)
3 求 W ( α ) W(\alpha) W(α)的极大值
由式子 ( 7 ) (7) (7)我们可以得出如下优化问题:
max α W ( α ) = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m y ( i ) y ( j ) α i α j ( x ( i ) ) T x ( j ) s . t . α i ≥ 0 , i = 1 , . . . , m ∑ i = 1 m α i y ( i ) = 0 (11) \begin{aligned} \max_{\alpha} &W(\alpha)=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^my^{(i)}y^{(j)}\alpha_i\alpha_j(x^{(i)})^Tx^{(j)}\\[1ex] s.t.\;\;&\alpha_i\geq0,i=1,...,m\\[1ex] &\sum_{i=1}^m\alpha_iy^{(i)}=0 \end{aligned}\tag{11} αmaxs.t.W(α)=i=1∑mαi−21i,j=1∑my(i)y(j)αiαj(x(i))Tx(j)αi≥0,i=1,...,mi=1∑mαiy(i)=0(11)
之所以式子 ( 6 ) (6) (6)中的最后一个也会成为约束条件,是因为 W ( α ) W(\alpha) W(α)就是通过 ( 6 ) (6) (6)求解出来的,是 W ( α ) W(\alpha) W(α)存在的前提。
现在我们的优化问题变成了如上的形式。对于这个问题,我们有更高效的优化算法,即序列最小优化(SMO)算法。我们通过这个优化算法能得到 α \alpha α,然后再将 α \alpha α代入式子 ( 6 ) (6) (6)我们就可以求解出 w , b w,b w,b,进而求得我们最初的目的:找到超平面,即”决策平面”。
4 求解参数 b b b
在求解出 α \alpha α之后,代入 ( 6 ) (6) (6)即可求解得到 w w w;而 b b b的求解公式为:
b = − 1 2 ( max i : y ( i ) = − 1 w T x ( i ) + min i : y ( i ) = + 1 w T x ( i ) ) (12) b=-\frac{1}{2}\large(\max_{i:y^{(i)}=-1}w^Tx^{(i)}+\min_{i:y^{(i)}=+1}w^Tx^{(i)})\tag{12} b=−21(i:y(i)=−1maxwTx(i)+i:y(i)=+1minwTx(i))(12)
这个公式怎么来的呢?由式子 ( 5 ) (5) (5)可知,正负样本支持向量所在的直线为 y ( i ) ( w T x ( i ) + b ) = 1 y^{(i)}(w^Tx^{(i)}+b)=1 y(i)(wTx(i)+b)=1,即:
对于正样本支持向量来说有:
w T x ( + ) + b = 1 (13) w^Tx^{(+)}+b=1\tag{13} wTx(+)+b=1(13)
对于负样本支持向量来说有:
w T x ( − ) + b = − 1 (14) w^Tx^{(-)}+b=-1\tag{14} wTx(−)+b=−1(14)
因此由 ( 13 ) ( 14 ) (13)(14) (13)(14)可得:
b = − 1 2 ( w T x ( + ) + w T x ( − ) ) (15) b=-\frac{1}{2}\large(w^Tx^{(+)}+w^Tx^{(-)})\tag{15} b=−21(wTx(+)+wTx(−))(15)
不过这看起来似乎和 ( 12 ) (12) (12)还有一点点差距,原因在哪儿呢?在前面的文章我们说到可以用 ∣ w T x + b ∣ |w^Tx+b| ∣wTx+b∣(函数间隔)来衡量样本点到超平面的远近程度,由于大家的截距 b b b都是一样,所以我们同样可以用 ∣ w T x ∣ |w^Tx| ∣wTx∣来作为标准。因此对于正样本来说,离超平面最近的支持向量就应该是 min ( w T x ) \min(w^Tx) min(wTx)(因为此时 w T x > 0 w^Tx>0 wTx>0,所以选择最小的);而对于负样本来说,离超平面最近的支持向量就应该是 max ( w T x ) \max(w^Tx) max(wTx)(因为此时 w T x < 0 w^Tx<0 wTx<0,所以选择最大的)。由此,我们便能得到截距 b b b的计算公式。
例如:
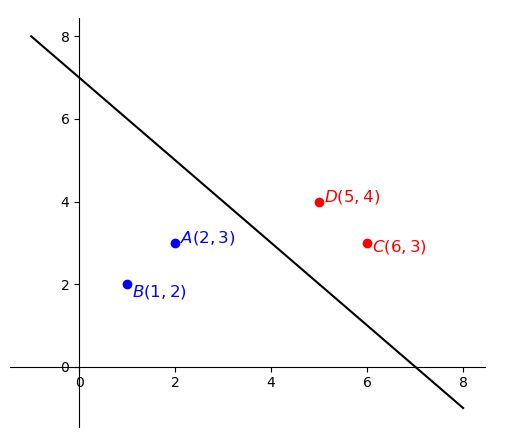
如图,红色为正样本( y = + 1 y=+1 y=+1),紫色为负样本( y = − 1 y=-1 y=−1),直线为 x 1 + x 2 − b = 0 x_1+x_2-b =0 x1+x2−b=0,则有:
max i : y ( i ) = − 1 w T x ( i ) = max ( 1 ∗ 2 + 1 ∗ 3 , 1 ∗ 1 + 1 ∗ 2 ) = 5 min i : y ( i ) = + 1 w T x ( i ) = min ( 1 ∗ 5 + 1 ∗ 4 , 1 ∗ 6 + 1 ∗ 3 ) = 9 b = − 1 2 ( 5 + 9 ) = − 7 \begin{aligned} &\max_{i:y^{(i)}=-1}w^Tx^{(i)}=\max(1*2+1*3,1*1+1*2)=5\\[1ex] &\min_{i:y^{(i)}=+1}w^Tx^{(i)}=\min(1*5+1*4,1*6+1*3)=9\\[1ex] &b=-\frac{1}{2}(5+9)=-7 \end{aligned} i:y(i)=−1maxwTx(i)=max(1∗2+1∗3,1∗1+1∗2)=5i:y(i)=+1minwTx(i)=min(1∗5+1∗4,1∗6+1∗3)=9b=−21(5+9)=−7
5 总结
在这篇文章中,笔者首先介绍了在求解SVM模型中如何构造广义的拉格朗日函数以及其对应的对偶问题;接着我们通过求解对偶问题中 L ( w , b , α ) \mathcal{L}(w,b,\alpha) L(w,b,α)的极小值得到了 w w w的计算解析式 ( 6 ) (6) (6),需要提醒的是 w w w的表达式也是理解SVM核函数的关键;最后我们同样还得到了截距 b b b的计算解析式。同时,这也是关于SVM内容的最后一篇文章,当然还是有很多地方没有介绍到例如 α , w \alpha,w α,w的求解过程等。其原因在于对于最后部分的求解内容笔者自己确实也没弄明白,所以就不再此处献丑了。感兴趣的朋友可以自己检索相关资料进行学习。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至[email protected]并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1]《统计机器学习(第二版)》李航,公众号回复“统计学习方法”即可获得电子版与讲义
[2] Andrew Ng. CS229. Note3 http://cs229.stanford.edu/notes/cs229-notes3.pdf
[3] Deriving the optimal value for the intercept term in SVM https://stats.stackexchange.com/questions/91269/deriving-the-optimal-value-for-the-intercept-term-in-svm
推荐阅读
[1]原来这就是支持向量机
[2]从另一个角度理解支持向量机
[3]SVM之sklearn建模与线性不可分
[4]SVM之软间隔最大化