Hadoop2.7.2版本分布式集群搭建详细记录(2)
接上上一篇《Hadoop2.7.2版本分布式集群搭建详细记录》。
Hadoop Cluster Setup
4.hadoop平台安装
hadoop下载地址附上: http://archive.apache.org/dist/hadoop/core/ 我下载的是当前最新版本 2.7.2版本。
hadoop的安装是挺简单的了。。直接把下载的压缩包解压到/usr/bin/下即可了。。。很简单的把。。
centos7中解压命令为: tar -xzvf hadoop-zip-file-name -C /usr/bin
5.修改hadoop环境配置
这玩意实在坑=(其实是我太菜 哈哈哈=。=)。配置文件目录为: /usr/bin/hadoop-2.7.2/etc/hadoop ( 网上很多教程都是1.x版本的,配置文件目录不一样)
主要修改以下几个文件 hadoop-env.sh yarn-env.sh (这两个文件是解决JAVA_HOME问题)。这个比较简单。。找到后直接把jd绝对路径值赋值给JAVA_HOME
重点解决 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
配置参考文档: http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html (Hadoop Cluster Setup)
这里我直接列出几个文件的内容吧。测试通过了。。
core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/usr/bin/hadoop-2.7.2
io.file.buffer.size
131702
hdfs-site.xml
dfs.namenode.name.dir
file:/usr/bin/hadoop-2.7.2/dfs/name
dfs.datanode.data.dir
file:/usr/bin/hadoop-2.7.2/dfs/data
dfs.replication
1
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
最后还要配置下slavers文件。这个保险起见,用vi来编辑。应该是换行的原因吧。
这些配置好后,把hadoop-2.7.2文件发送给各个slaver机器上。
linux命令如下: scp -r /usr/bin/hadoop-2.7.2 root@slaver-name:/usr/bin/
这些弄好后就在master机器上,进入到hadoop-2.7.2文件夹下面。
cd /usr/bin/hadoop-2.7.2/
这时候先初始化hadoop : bin/hadoop namenode -format (注意下图划红线部分 表示成功执行 否则查错 在logs文件夹下)
然后启动hadoop :sbin/start-all.sh
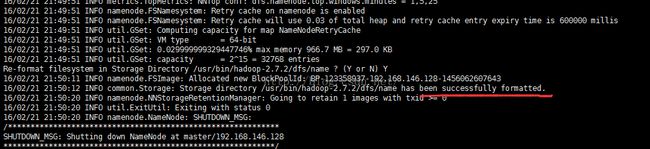
这时候检查下master 和slaver机器中 hadoop运行状态,方法两个,一个是通过jps命令 一个是web查看。
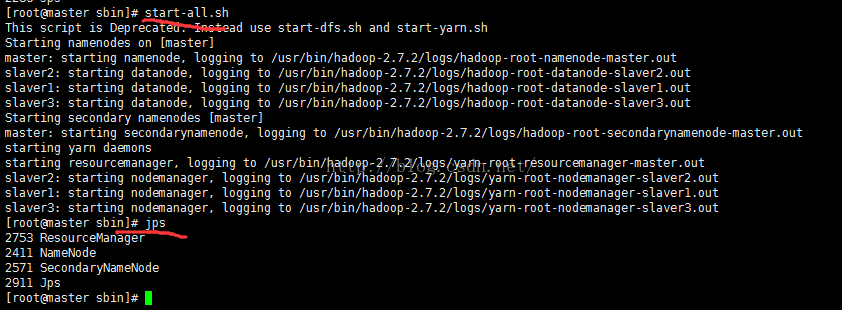
下图为slaver中的jps结果:

注意下: 如果NodeManager没有启动 那么基本是yarn-site.xml文件配置有错误。。。
接下来看看成功启动后web上的结果 我们看两个端口的结果:


好了,hadoop的搭建和环境配置到此结束。接下来,我们测试下hadoop中样例。
6. 测试hadoop样例
样例jar地址:/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
为了方便演示,我把此文件直接上传到hadoop-2.7.2根目录下。命名为examples.jar
输入指令: bin/hadoop jar examples.jar 查看examples.jar有哪些类。如果想更加了解某个类 可以输入 bin/hadoop jar examples.jar pi 即可了解关于计算pi的参数

ok,这里我们就先测试计算pi的值 参数选择10 20。。下一节,用Python写WordCount代码。
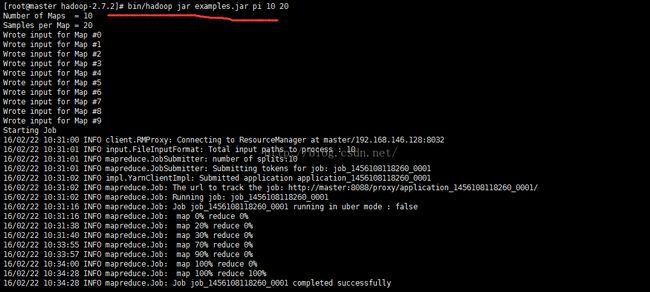

此时,打开master:8088也可以查看到此任务。

7. 编写基本的MapReduce程序并运行
说明下,这里我使用python来写。至于java环境开发的话,网上教程挺多的。难度不大。这里用python的原因是,不用搭配环境,直接vim即可上手。多方便啊。
先说说相关的基本知识点,hadoop允许用户使用各种支持标准输入输出(stdin stdout)的语言进行MapReduce编码。hadoop之所以能实现如此的灵活性,是通过hadoop-streaming来实现的。关于Streaming的知识点,可以查看官方文档(我认为,应该多看官方文档,而不是有问题就直接百度,多去思考思考,不行再来百度谷歌也不迟。)