分别用selenium和scrapy爬取网站(一)
用selenuim抓取“美食”网页信息
一、下载安装selenuim、PhantomJS(Chrome),并配置好环境。
二、利用selenium打开浏览器,设计爬取过程。
from selenium import webdriver
browser = webdriver.Chrome()运行上述程序,程序会自动调用chrome浏览器。
- 打开淘宝首页,在搜索框中输入“美食“,并且点击”搜索“按钮。
- 参考selenium python官方文档: http://selenium-python.readthedocs.io/waits.html,利用selenium模仿输入、点击等操作。首先,添加以下import信息。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC- 输入框和点击按钮的获取方法如下:
browser.get('https://www.taobao.com')
wait=WebDriverWait(browser, 10)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))
)
submit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")) - 查看官方文档,找到利用selenium向输入框输入文字及点击按钮的方法
input.send_keys("美食")
submit.click()- 何时页面算加载完成?观察到页面最下方有一个页码栏,找到该搜索一共包含多少页。若出现了总共的页数,则视为页面加载完成。

- selenium中实现方法如下:

- 按F12审查元素,复制selector。

total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))- 之后,获取页面详情。在使用selenium访问网站时,有可能会发生一些异常,常见的异常为连接超时,使用try。搜索部分整段代码如下:
def search():
try:
browser.get('https://www.taobao.com')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))
)
submit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,
"#J_TSearchForm > div.search-button > button")) )
input.send_keys(KEY_WORD)
total=wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,
'#mainsrp-pager > div > div > div > div.total')))
get_product()#获取商品信息
return total.text #返回多少页
except TimeoutError:
return search() #递归 再次调用- 翻页操作:

跟前面的操作相同,获取输入框和确定按钮。
def next_page(page_number):#page_number是当前的页码 执行翻页操作
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,
"#mainsrp-pager > div > div > div > div.form > input"))
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,
"#mainsrp-pager > div > div > div > div.form >span.btn.J_Submit")))
input.clear()#清除输入框里面的内容
input.send_keys(page_number)
submit.click()
#与前面的
wait.until(
'#mainsrp-pager > div > div > div > ul > li.item.active > span'),
str(page_number))
)
get_product()
except TimeoutError:
next_page(page_number)
def main():
total=search()#共100页
total=int(re.compile('(\d+)').search(total).group(1))#获取数字
for i in range(2,total+1):
next_page(i)- 接下来,开始爬取各商品信息,首先获取每个商品所在的div。
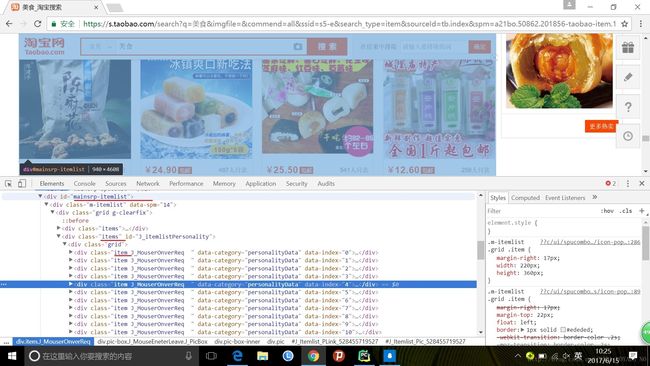
def get_product():
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,
'#mainsrp-itemlist .items .item'))
)
html=browser.page_source
print(html)- 使用pyquery来解析
from pyquery import PyQuery as pq
doc=pq(html)
items=doc('#mainsrp-itemlist .items .item').items()#items()可以得到所有选择的内容
- 获取每个商品的图片的src,商品价格,成交量,标题,店铺名称,店铺地址。
for item in items:
product={
'image':item.find('.pic .img').attr('src'),#获取src属性
'price':item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3], #309人付款 去掉最后三个字
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
- 将获取的信息保存到数据库中。
import pymysql
con = pymysql.connect(**DBKWARGS)
cur = con.cursor()
def save_to_mysql(result):
sql_content = ("insert into TBMeishi (image,price,deal,title,shop,location)"
"values(%s,%s,%s,%s,%s,%s)")
lis = (result['image'],result['price'],result['deal'],result['title'],
result['shop'],result['location'] )
try:
cur.execute(sql_content, lis)
except Exception as e: #Excdption 是所有错误的父类
print(e)
con.rollback()
else:
con.commit()
print("插入数据成功")- 可将chrome浏览器换成无头浏览器PhantomJS。
EXECT_PATH='******'#你浏览器所在的位置。
browser = webdriver.PhantomJS(EXECT_PATH)
browser.set_window_size(1400,900)- 换成无头浏览器之后,可以加入一些print,方便了解程序运行情况。
def main():
try:
total=search()
total=int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
except Exception:
print("程序出错")
finally:
browser.close()
cur.close()
con.close()
if __name__=="__main__":
main()- 在最后别忘了关闭要浏览器和数据库,养成良好的编程习惯。