CVPR2020 best paper:对称可变形三维物体的无监督学习
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

代码地址:
https://github.com/elliottwu/unsup3d
项目地址:https://elliottwu.com/projects/unsup3d/
测试地址:
http://www.robots.ox.ac.uk/~vgg/blog/unsupervised-learning-of-probably-symmetric-deformable-3d-objects-from-images-in-the-wild.html?image=004_face&type=human
概述
作者提出了一种从原始单目图像学习三维形变物体的方法,并且没有额外的监督信号。这个方法是基于自编码器的架构,将输入的图像转换为深度、反射率、视角和照明信息。为了分解这些没有监督的组件,作者使用了这样一个事实,即在大体上很多物体都是一个对称结构。对照明的推理允许我们去发掘潜在的对称,尽管由于阴影等原因外表不是对称的。实验表明这个方法能够从单目图像中恢复效果非常好的人脸、猫脸和汽车的三维形状。
简介
理解图像的3D结构在很多计算机视觉应用中是非常关键的,很多深度网络都是在2D平面上理解图像,3D建模能够去除自然图像中的变化性并且提高图像的理解。和其他一些方式类似,作者考虑从可变形物体学习3D模型(注:就是通过改变物体的形状来生成模型,比如说mesh表示的球体,通过改变顶点的位置即可生成另外一个物体)。
作者在两个挑战性的条件下研究这个问题,第一个是没有2D或者3D的真值,第二个是算法必须使用无约束的单目图像集合——特别地,不需要相同实例的多个视角图像,这是因为在很多应用中从一张图像是非常重要的。基于上面两个问题,该算法能够从一张图像中建立该物体的三维形状,如下图所示:

首先用一个自编码器将图像分解成反射率、深度、光照和视角信息,并且对于这些信息没有直接的监督。但是,这是一个不适定问题,为了最小化这个问题,作者注意到大多数的物体都是对称的。由此可以通过简单的镜像对称获得一个虚拟的第二视角,如果能够找到这两张图像之间的联系,三维重建就能够通过立体重建实现。
但是对于一个物体来说,由于各种原因,并不是完全对称的。作者从两个方面解决这个问题,第一个方法是利用确定的光照模型来发掘潜在的对称性,第二个方式是增大这个模型去推理物体潜在的对称性缺失。
作者将上面的组件集成到一个端到端的学习框架中,包括置信图,都是从原始图像生成的。同时还发现,对称可以通过翻转内部表示来实现,这对于概率性的对称推理特别有用。最后实验表面,该方法在很多数据集上面都表现出了很好的效果,并且超过了目前最先进的技术(可直接看最后的实验结果和视频)。
相关工作
为了评估该方法对于基于图像的三维重建文献的贡献,作者考虑了以下三个方面的内容:信息的使用,假设和输出。下表显示了相比于之前的作品,作者基于上述三个因素的贡献:

SFM:传统的方法例如sfm能够从单个严格的场景中重建三维结构,尽管单目重建方法能够从单个图像中表现出很好的效果,但是需要多个视角或者视频进行训练。还有一个方法叫做Non-Rigid SfM (NRSfM),能够学习重建可变形的物体,但是需要标注好的2D关键点作为监督。
Shape from X:其他的一些线索被选择或者作为sfm的补充来恢复形状,例如轮廓、纹理、对称等。特别地,本文的方法受到从对称和明暗情况恢复形状的影响,前者使用镜像图像作为虚拟第二视角重建对称物体,后者假设一个阴影模型,如兰伯氏反射率,并通过利用非均匀光照重建表面。
特殊种类的重建:基于图像的方法最近被广泛应用,不管是原始图像还是2D关键点。尽管这是一个不适定问题,但是可以通过从训练数据中学习合适的对象来解决。除了直接使用3D真值,一些作者考虑使用视频、立体对,还有一些方法使用2D关键点标注或者图像mask。对于人体或者人脸来说,有些方法直接从原始图像学习重建通过一些预先定义的模型。这些模型是由一些特殊的软件或者其他方法生成的,但是这对于一些动物来说比较难获得,限制了形状的细节部分。
最近才有作者尝试着从原始单目图像中学习物体类别的几何纹理,但是都有一定的缺陷或者不足,将会在后面做一个详细的比较。因为要从3D模型恢复图像进行比较,所以一个很重要的组件是可微渲染器。现在已经提出了很多渲染方法,这里使用了Neural 3d mesh renderer(公众号里面有一篇文章专门讲这个)。
方法
给定一个对象类别的图像集合,例如人脸,我们的目标是学习一个模型Φ,将输入的图像分解成3D形状、反射率、照明和视角,如下图所示:
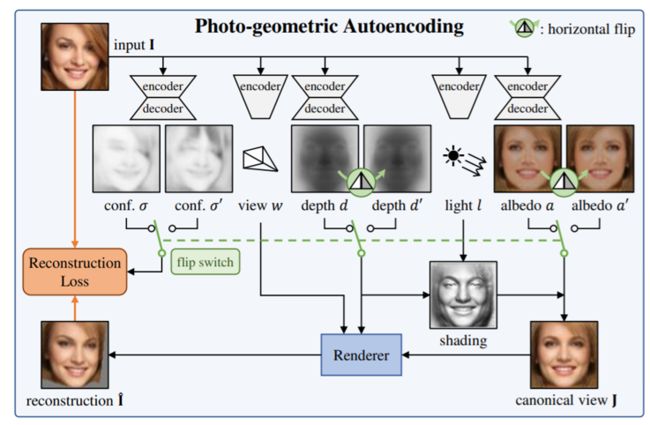
因为只有原始图像可以学习,所以首先从图像中恢复前面提到的四个因素。还有一个事实是,大部分物体都是对称的,但是由于其它原因,对于每一个实例来说不一定是完全对称的。为了解决这个问题,作者明确建立了非对称光照模型,并且对于输入图像中的每个像素,都有一个置信值,用于解释该像素在图像中具有对称对等物的概率(上图conf)。下面将详细介绍各部分的内容。
1、照片自编码:一张图像可以表示成3xWxH的网格,假设图像大部分都是以感兴趣对象为中心,我们的目标是学习一个函数Φ,实现神经网络,将输入转换为四个要素(d,a,w,l)。这四个要素分别事深度图d,反照率图像a,光方向l和视角w。
然后由这四个要素分两步重建物体,光照Λ和投影Π,如下所示:
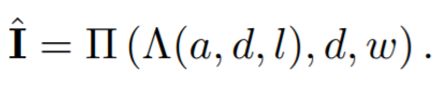
光照功能Λ从一个规范角度生成基于深度图d、光方向l和反射率a的物体,视点w表示规范视点和实际输入图像I的视点之间的转换。然后投影函数Π基于变化的角度、规范的深度和光照功能产生的模型,生成另外一幅图像,和输入图像求重建损失。
2、可能对称的物体:利用对称进行三维重建需要在图像中识别对称的物体点,这里作者假设深度和反照率在一个标准坐标系中重建,是关于一个固定的垂直面对称的。这能够帮助模型发现“规范视图”,这对重建来说非常重要。
为了实现上述目标,作者考虑了一个操作器沿着水平轴翻转图,d≈flipd和a≈flipa。虽然这些限制可以通过在学习目标中添加相应的损失函数来强制执行,但它们很难平衡。为此,作者通过获得翻转后重建的模型来达到相同效果,如下图所示:
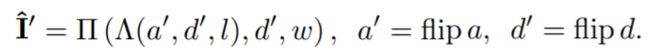
然后分别考虑两个模型重建后生成图像的损失,因为它们是相称的,很容易平衡和共同训练。更重要的是,这个方法能够允许我们更容易的推理对称的概率。
原始图像和生成的图像之间的损失如下所示:
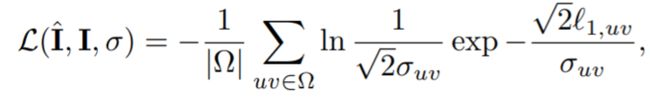
其中L1,uv是像素之间的L1损失,σ是由网络建立的置信图,表达了模型的任意不确定性。这种损失可以解释为重构残差的拉普拉斯分布的负对数似然性。优化可能性使模型自我校准,学习有意义的置信图。
更重要的是,作者从相同的图像中,利用网络来估计第二个置信图。这个置信图表示输入图像的哪些部分可能是不对称的。例如第二章图像中人脸上面的头发不是对称的,第二个置信图在不满足对称假设的头发区域,可指定较高的重建不确定性。
总的来说,作者结合两种重构误差给出了学习目标:
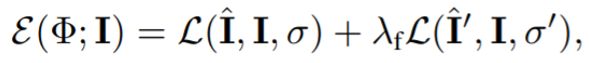
3、成像模型:图像是由一个相机在特定的角度拍摄得到的,如果我们用P表示一个在摄像机参考系中表示的3D点,它通过以下投影映射到像素P=(u,v,1):
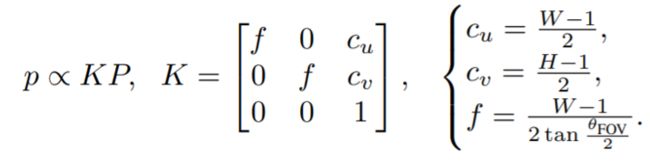
这个模型假设一个透视相机的视野(FOV) θFOV。假设物体与摄像机的标称距离约为1米。考虑到这些图像是围绕一个特定的物体剪裁的,假设一个相对狭窄的FOV,如θFOV=10°。深度图d将深度值duv与标准视图中的每个像素(u, v)关联起来,通过倒转相机模型,作者发现这与三维点相对应:
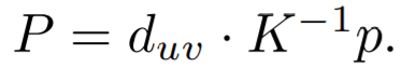
4、感知损失:上面提到的图像之间的损失对小的几何缺陷比较敏感,可能会导致模糊的重建。作者添加了一个感知损失项来缓解这个问题,在图像编码器的第k层预测一个表示e(I),这个特性编码器不必接受监督任务的训练,和上个损失函数相似,假设为高斯分布,感知损失为:
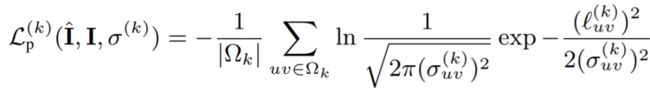
其中
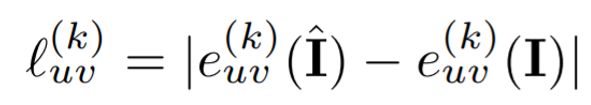
表示第k层的每个像素指数uv。更加详细的损失介绍见论文。
结果展示
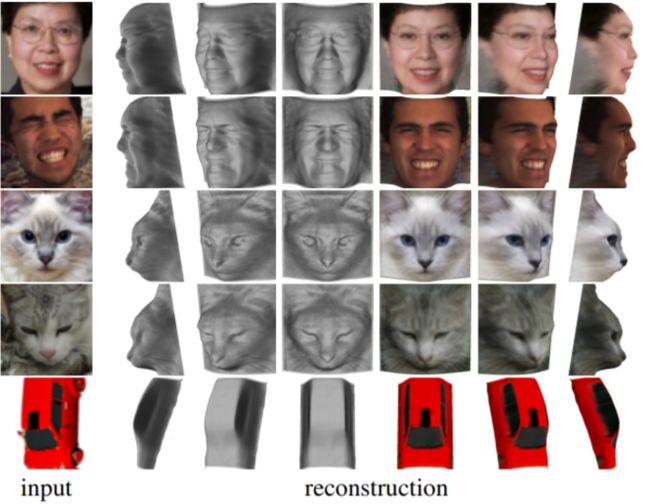
面部,猫脸和汽车的重建

人脸的重建

与SOTA的效果比较

抽象猫脸的重建效果
本文仅做学术分享,如有侵权,请联系删文。
推荐阅读:
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近1000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题