第1133期AI100_机器学习日报(2017-10-25)
AI100_机器学习日报 2017-10-25
- 文本分类实战: 传统机器学习vs深度学习算法对比(附代码)
- 如何理解深度学习分布式训练中的large batch size与learning rate的关系
- 一文读懂AlphaGo Zero算法:白话蒙特卡洛树搜索和ResNet
- 百度论文 Deep Voice 3: 2000-Speaker Neural Text-to-Speech
- ICCV 2017奖项公布
@好东西传送门 出品,由@AI100运营, 过往目录 见http://geek.ai100.com.cn
订阅:关注微信公众号 AI100(ID:rgznai100,扫二维码),回复“机器学习日报”,加你进日报群

本期话题有:
全部14 算法5 自然语言处理4 深度学习4 应用4 视觉4 会议活动4 资源3 入门1 语音1
用日报搜索找到以前分享的内容: http://ml.memect.com/search/
今日焦点 (5)
wx: 网页版 2017-10-26 06:06
会议活动 经验总结 入门 深度学习 算法 应用 自然语言处理 TFIDF 博客 分类 广告系统 行业动态 会议 决策树 特征工程 统计 信息检索 主题模型
「文本分类实战: 机器学习vs深度学习算法对比(附代码)」这几周因为在做竞赛所以没怎么看论文刷题写博客,今天抽时间把竞赛用到的东西总结一下。先试水了一个很小众的比赛–文因互联,由AI100举办,参赛队不足20个,赛题类型是文本分类。选择参赛的主要原因是其不像阿里们举办的竞赛那样,分分钟就干一件事就是特征工程和调参,然后数据又多又乱,不适合入门。其次一个原因就是目前我的研究方向就是NLP,之前也做过一个文本分类的东西,所以就参赛了。这里将主要介绍我在比赛中用到的几个模型,从理论到代码实现进行总结。大家可以到竞赛官网查看赛题并下载数据集,数据集中主要包含下面几个文件,可见数据集很小也很简单,只需要使用training.csv文件进行训练我们的文本分类模型,使用testing.csv进行预测并提交结果即可: 下面是训练集的前两行,每一行的第一个数字表示该行文本的类别,后面的描述就是要建模的文本。这个数据集是11个公司的描述数据,我们要根据4774条训练数据去预测2381条数据的类别标签。除此之外,我们还可以看到这些训练数据存在较严重的类别不平衡问题。如下图所示: 了解完数据集,接下来我们开始进行文本分类,开始提交结果。在这里插句题外话,往往这种竞赛大家喜欢一上来什么都不做先提交一个结果站站场面==也就是提交一个随机结果、均值等。因为我看到这个比赛的时候都已经快结束了,比较匆忙,所以第一次提交的也是直接用随机数生成的,后来还自作多情的按照训练集的类比占比作为每个类别概率生成随机数(结果显示确实有提高),代码如下所示:import numpy as npwith open(‘output/random_out.csv’, ‘w’) as f: for i in range(1, 2382): f.write(str(i)) f.write(‘,’) aa = np.random.random() b = 0 if aa <= 0.25: b = 3 elif aa <= 0.5: b = 4 elif aa <= 0.7: b =6 elif aa <= 0.775: b=7 elif aa <= 0.825: b = 5 elif aa <= 0.875: b = 8 elif aa <= 0.925: b = 10 elif aa <= 0.95: b = 11 elif aa <= 0.975: b = 2 elif aa <= 1: b = 9 f.write(str(b)) f.write(‘\n’) 好,接下来说正经的,我用的第一种方法就是朴素贝叶斯,可以参见我之前的一篇博客 http://blog.csdn.net/liuchonge/article/details/52204218介绍了使用CHI选择特征,TFIDF计算特征权重,朴素贝叶斯分类的整体流程。因为之前做了这样的尝试,所以这里直接套过来看看效果如何,代码入下,这里的代码都是自己实现的,太丑,其实可以直接调用gensim的接口去做,以后有时间改改代码:本文github源码地址:在公众号 datadw 里 回复 CNN 即可获取。这里我们可以为每个类选出最具代表性的十个词语看一下,从下面的特征词可以看出来,我们程序提取的特征词还是很具有类别区分度的,也可以看出第四类和第九类、第五类和第八类较为相似,可能在分类上会比较难区分:接下来调用train.py函数,就可以得到我们的预测结果,这里我使用了朴素贝叶斯、决策树、SVC三种算法,但是结果显示朴素贝叶斯效果更好,根据参数不同测试集准确率大概达到了78%~79%左右。此外还有几个地方可以调节:特征词维度的选择,即上面代码feature_select_use_new_CHI()函数中每个类别选择多少个特征词,取值范围在100-500特征权重的计算方式,即上面代码document_features()函数中对每个特征词的权重计算方式,我们可以认为只要出现就记为1,否则为零;或者使用其在该文本中出现次数作为权重;或者使用TF-IDF作为权重,或者其他方法。 分类器的选择及参数调整,其实我们应该取出500条记录作为测试集去验证模型好坏以及作为参数选择的依据,但是因为时间比较紧迫,所以我并未作这部分工作==此外,在获得了上面所说的类别特征词之后(每类取十个),我还尝试着用简单的类别匹配方法进行分类,思路很简单,就是看测试集包含哪个特征集中的单词更多,代码入下:result = [] qq = 0with open(‘data/testing.csv’, u’r’) as f: for line in f: content = “” for aain line.split(‘,’)[1:]: content += aa word_list, word_set = jieba_fenci(content, stopwords_list) label = 2 count = 0 for i, cla in enumerate(feature_words): tmp = 0 for word in word_list: if word in cla: tmp += 1 if tmp > count: count = tmp label = i+1 if count == 0: qq += 1 result.append(label)这个效果一般,准确率好像是在69%或者74%左右,记不太清了。考虑到xgboost算法在各类竞赛中都有很好的效果,我也决定使用该算法尝试一下效果如何,在网上找了一篇博客,直接套用到这里。我们使用所有的词作为特征进行one-hot编码(使用from sklearn.feature_extraction.text import CountVectorizer和 from sklearn.feature_extraction.text import TfidfTransformer),代码如下:本文github源码地址:在公众号 datadw 里 回复 CNN 即可获取。效果不错,测试集可以达到80%的准确度,出乎意料的好==然后我还尝试将提取出来的特征用到XGBoost模型上,也就是在train.py中调用xgboost模型,结果发现准确度出不多也是80%左右,没有很大提升。其实这里也应该做参数优化的工作,比如xgboost的max_depth、n_estimate、学习率等参数等应该进行调节,因为时间太紧我这部分工作也没做,而是使用的默认设置==转自:大数据挖掘DT数据分析 完整内容请点击“阅读原文” via: http://mp.weixin.qq.com/s?__biz=MzA4NDEyMzc2Mw==&mid=2649678278&idx=4&sn=32486a10e1e3920d357db2b64535ce2e&scene=0#wechat_redirect
会议活动 经验总结 入门 深度学习 算法 应用 自然语言处理 TFIDF 博客 分类 广告系统 行业动态 会议 决策树 特征工程 统计 信息检索 主题模型
「文本分类实战: 机器学习vs深度学习算法对比(附代码)」这几周因为在做竞赛所以没怎么看论文刷题写博客,今天抽时间把竞赛用到的东西总结一下。先试水了一个很小众的比赛–文因互联,由AI100举办,参赛队不足20个,赛题类型是文本分类。选择参赛的主要原因是其不像阿里们举办的竞赛那样,分分钟就干一件事就是特征工程和调参,然后数据又多又乱,不适合入门。其次一个原因就是目前我的研究方向就是NLP,之前也做过一个文本分类的东西,所以就参赛了。这里将主要介绍我在比赛中用到的几个模型,从理论到代码实现进行总结。大家可以到竞赛官网查看赛题并下载数据集,数据集中主要包含下面几个文件,可见数据集很小也很简单,只需要使用training.csv文件进行训练我们的文本分类模型,使用testing.csv进行预测并提交结果即可: 下面是训练集的前两行,每一行的第一个数字表示该行文本的类别,后面的描述就是要建模的文本。这个数据集是11个公司的描述数据,我们要根据4774条训练数据去预测2381条数据的类别标签。除此之外,我们还可以看到这些训练数据存在较严重的类别不平衡问题。如下图所示: 了解完数据集,接下来我们开始进行文本分类,开始提交结果。在这里插句题外话,往往这种竞赛大家喜欢一上来什么都不做先提交一个结果站站场面==也就是提交一个随机结果、均值等。因为我看到这个比赛的时候都已经快结束了,比较匆忙,所以第一次提交的也是直接用随机数生成的,后来还自作多情的按照训练集的类比占比作为每个类别概率生成随机数(结果显示确实有提高),代码如下所示:import numpy as npwith open(‘output/random_out.csv’, ‘w’) as f: for i in range(1, 2382): f.write(str(i)) f.write(‘,’) aa = np.random.random() b = 0 if aa <= 0.25: b = 3 elif aa <= 0.5: b = 4 elif aa <= 0.7: b =6 elif aa <= 0.775: b=7 elif aa <= 0.825: b = 5 elif aa <= 0.875: b = 8 elif aa <= 0.925: b = 10 elif aa <= 0.95: b = 11 elif aa <= 0.975: b = 2 elif aa <= 1: b = 9 f.write(str(b)) f.write(‘\n’) 好,接下来说正经的,我用的第一种方法就是朴素贝叶斯,可以参见我之前的一篇博客 http://blog.csdn.net/liuchonge/article/details/52204218介绍了使用CHI选择特征,TFIDF计算特征权重,朴素贝叶斯分类的整体流程。因为之前做了这样的尝试,所以这里直接套过来看看效果如何,代码入下,这里的代码都是自己实现的,太丑,其实可以直接调用gensim的接口去做,以后有时间改改代码:本文github源码地址:在公众号 datadw 里 回复 CNN 即可获取。这里我们可以为每个类选出最具代表性的十个词语看一下,从下面的特征词可以看出来,我们程序提取的特征词还是很具有类别区分度的,也可以看出第四类和第九类、第五类和第八类较为相似,可能在分类上会比较难区分:接下来调用train.py函数,就可以得到我们的预测结果,这里我使用了朴素贝叶斯、决策树、SVC三种算法,但是结果显示朴素贝叶斯效果更好,根据参数不同测试集准确率大概达到了78%~79%左右。此外还有几个地方可以调节:特征词维度的选择,即上面代码feature_select_use_new_CHI()函数中每个类别选择多少个特征词,取值范围在100-500特征权重的计算方式,即上面代码document_features()函数中对每个特征词的权重计算方式,我们可以认为只要出现就记为1,否则为零;或者使用其在该文本中出现次数作为权重;或者使用TF-IDF作为权重,或者其他方法。 分类器的选择及参数调整,其实我们应该取出500条记录作为测试集去验证模型好坏以及作为参数选择的依据,但是因为时间比较紧迫,所以我并未作这部分工作==此外,在获得了上面所说的类别特征词之后(每类取十个),我还尝试着用简单的类别匹配方法进行分类,思路很简单,就是看测试集包含哪个特征集中的单词更多,代码入下:result = [] qq = 0with open(‘data/testing.csv’, u’r’) as f: for line in f: content = “” for aain line.split(‘,’)[1:]: content += aa word_list, word_set = jieba_fenci(content, stopwords_list) label = 2 count = 0 for i, cla in enumerate(feature_words): tmp = 0 for word in word_list: if word in cla: tmp += 1 if tmp > count: count = tmp label = i+1 if count == 0: qq += 1 result.append(label)这个效果一般,准确率好像是在69%或者74%左右,记不太清了。考虑到xgboost算法在各类竞赛中都有很好的效果,我也决定使用该算法尝试一下效果如何,在网上找了一篇博客,直接套用到这里。我们使用所有的词作为特征进行one-hot编码(使用from sklearn.feature_extraction.text import CountVectorizer和 from sklearn.feature_extraction.text import TfidfTransformer),代码如下:本文github源码地址:在公众号 datadw 里 回复 CNN 即可获取。效果不错,测试集可以达到80%的准确度,出乎意料的好==然后我还尝试将提取出来的特征用到XGBoost模型上,也就是在train.py中调用xgboost模型,结果发现准确度出不多也是80%左右,没有很大提升。其实这里也应该做参数优化的工作,比如xgboost的max_depth、n_estimate、学习率等参数等应该进行调节,因为时间太紧我这部分工作也没做,而是使用的默认设置==转自:大数据挖掘DT数据分析 完整内容请点击“阅读原文” via: http://mp.weixin.qq.com/s?__biz=MzA4NDEyMzc2Mw==&mid=2649678278&idx=4&sn=32486a10e1e3920d357db2b64535ce2e&scene=0#wechat_redirect
 ChatbotsChina 网页版 2017-10-25 16:50
ChatbotsChina 网页版 2017-10-25 16:50
深度学习
如何理解深度学习分布式训练中的large batch size与learning rate的关系? http://t.cn/RWa6MKK

 爱可可-爱生活 网页版 2017-10-25 08:36
爱可可-爱生活 网页版 2017-10-25 08:36
算法 邓侃
《一文读懂AlphaGo Zero算法:白话蒙特卡洛树搜索和ResNet》by 邓侃 via:新智元 http://t.cn/RWiOX9O
 爱可可-爱生活 网页版 2017-10-25 04:42
爱可可-爱生活 网页版 2017-10-25 04:42
深度学习 算法 论文 神经网络
《Deep Voice 3: 2000-Speaker Neural Text-to-Speech》W Ping, K Peng, A Gibiansky, S O. Arik, A Kannan, S Narang, J Raiman, J Miller [Baidu Research & OpenAI & UC Berkeley] (2017) http://t.cn/RWiRahd

 机器之心Synced 网页版 2017-10-25 00:29
机器之心Synced 网页版 2017-10-25 00:29
会议活动 视觉 CVPR ICCV 何恺明 会议
【ICCV 2017奖项公布:最大赢家何恺明获最佳论文】今日,ICCV 2017公布了本届 ICCV 的获奖论文,Facebook AI 研究员何恺明获得最佳论文奖,同时是最佳学生论文的作者之一。算上此前在 CVPR 2009、CVPR 2016 上的两篇「最佳论文」,何恺明现在已获得了四个最佳论文称号。 http://t.cn/RWiNSe6
最新动态
2017-10-25 (7)
wx:让创新获得认可 网页版 2017-10-25 19:58
应用 资源 自然语言处理 PDF 陈义明 机器人
「回顾 | 新加坡南洋理工大学终身正教授陈义明:物流拣选机器人的未来」 本文为10月24日晚,新加坡南洋理工大学终身正教授陈义明老师在将门技术社群,分享“物流拣选机器人的未来”的内容回顾。近2个小时的分享中,陈老师讨论了对电商仓库的拣选机器人都在进行哪些新的研发,并以亚马逊机器人挑战赛为例,来研究目前最先进的拣选机器人技术和并且畅想它的未来。 获取本期完整PDF+视频回顾>>关注“将门创投”(thejiangmen)微信公众号,回复“171025”获取下载链接。 ……获取完整PDF+视频回顾>>关注“将门创投”(thejiangmen)微信公众号,回复“171025”获取下载链接。 -END-现已涵盖CV、机器人、NLP、ML、IoT等多个当下火热的技术话题。我们每周邀请来自产学研的优秀技术人进行线上分享,目前群里已汇聚数千位上述领域的技术从业者。入群方式>>关注“将门创投”(id:thejiangmen)微信公众号,在后台回复关键词“技术社群”,提交入群申请表。通过审核后,我们会在第一时间发出邀请。 将门创投让创新获得认可!微信:thejiangmenservice @thejiangmen.com via: http://mp.weixin.qq.com/s?__biz=MzAxMzc2NDAxOQ==&mid=2650364457&idx=2&sn=a0d78d9e70e6865c351efec581824cd4&scene=0#wechat_redirect
应用 资源 自然语言处理 PDF 陈义明 机器人
「回顾 | 新加坡南洋理工大学终身正教授陈义明:物流拣选机器人的未来」 本文为10月24日晚,新加坡南洋理工大学终身正教授陈义明老师在将门技术社群,分享“物流拣选机器人的未来”的内容回顾。近2个小时的分享中,陈老师讨论了对电商仓库的拣选机器人都在进行哪些新的研发,并以亚马逊机器人挑战赛为例,来研究目前最先进的拣选机器人技术和并且畅想它的未来。 获取本期完整PDF+视频回顾>>关注“将门创投”(thejiangmen)微信公众号,回复“171025”获取下载链接。 ……获取完整PDF+视频回顾>>关注“将门创投”(thejiangmen)微信公众号,回复“171025”获取下载链接。 -END-现已涵盖CV、机器人、NLP、ML、IoT等多个当下火热的技术话题。我们每周邀请来自产学研的优秀技术人进行线上分享,目前群里已汇聚数千位上述领域的技术从业者。入群方式>>关注“将门创投”(id:thejiangmen)微信公众号,在后台回复关键词“技术社群”,提交入群申请表。通过审核后,我们会在第一时间发出邀请。 将门创投让创新获得认可!微信:thejiangmenservice @thejiangmen.com via: http://mp.weixin.qq.com/s?__biz=MzAxMzc2NDAxOQ==&mid=2650364457&idx=2&sn=a0d78d9e70e6865c351efec581824cd4&scene=0#wechat_redirect
 燕北新媒体 网页版 2017-10-25 10:56
燕北新媒体 网页版 2017-10-25 10:56
视觉
【Adobe公开“cloak”人工智能软件:可自动完成视频抠像】据外媒报道,Adobe公开人工智能视频编辑软件“cloak”。其工作方式类似于PS的内容识别填充,更为复杂的是它需要通过密集跟踪、学习分析周围图像,逐帧自动抠出对象和填充背景。这项技术应用不仅适合电影后期制作的复杂任务,还可以帮助个人用户…全文: http://m.weibo.cn/1711479641/4166691783301263
wx:不灵叔 网页版 2017-10-25 08:05
会议活动 深度学习 视觉 算法 语音 资源 自然语言处理 ICCV Kaggle Rich Family 分类 会议 机器翻译 刘斌 刘群 论文 强化学习 神经网络 书籍 孙兆民 王书浩 文仕学
「直播 | 深度好奇™算法工程师:用于文档理解的面向对象神经规划 | 学术青年分享会」分享内容▼深度好奇提出了用于垂直领域文档理解的OONP框架,它使用离散的对象本体图结构作为中间状态,该状态被OONP创建、更新直至最终输出。这个解析过程被OONP转化成为按照文本阅读顺序的离散动作的决策序列,模仿了人理解文本的认知程。OONP框架提供了神经符号主义的一个实例:在OONP框架内,连续信号、表示、操作和离散信号、表示、操作紧密结合,形成信息闭环。这使得OONP可以灵活地将各种先验知识用不同形式加入到行间记忆和策略网络中。为了优化OONP,深度好奇利用监督学习和强化学习以及二者的各种混合态,以适应不同强度和形式的监督信号以训练参数。 《Object-oriented Neural Programming (OONP) for Document Understanding》 论文地址: https://arxiv.org/abs/1709.08853 We propose Object-oriented Neural Programming (OONP), a framework for semantically parsing documents in specific domains. Basically, OONP reads a document and parses it into a predesigned object-oriented data structure (referred to as ontology in this paper) that reflects the domain-specific semantics of the document. An OONP parser models semantic parsing as a decision process: a neural net-based Reader sequentially goes through the document, and during the process it builds and updates an intermediate ontology to summarize its partial understanding of the text it covers. OONP supports a rich family of operations (both symbolic and differentiable) for composing the ontology, and a big variety of forms (both symbolic and differentiable) for representing the state and the document. An OONP parser can be trained with supervision of different forms and strength, including supervised learning (SL) , reinforcement learning (RL) and hybrid of the two. Our experiments on both synthetic and real-world document parsing tasks have shown that OONP can learn to handle fairly complicated ontology with training data of modest sizes. 分享主题▼Object-oriented Neural Programming (OONP) for Document Understanding用于文档理解的面向对象神经规划 分享人简介▼郑达奇,博士期间师从中科院计算所/都柏林城市大学刘群教授,后加入深度好奇。期间作为学术带头人在深度学习用于长文本生成等项目有重要贡献,参与了面向对象的神经规划、非线性文本表示等研究项目。郑博士长期从事机器翻译及人工智能的研究,在自然语言处理和神经符号智能等领域有较深的造诣。 分享时间▼北京时间10月25日(周三) 20:00 参与方式▼扫描海报二维码,点击底部菜单 复旦Ph.D沈志强:用于目标检测的DSOD模型(ICCV 2017)极限元刘斌:深度学习在语音生成问题上的典型应用搜狗文仕学:基于深度学习的语音分离Video ++孙兆民:视频内容识别行业分析悉尼科大王超岳:基于生成对抗网络的图像编辑方法达观数据张健:文本分类方法和应用案例 清华Ph.D王书浩:基于深度学习的电商交易欺诈检测系统Twitter工程师王东:详解YOLO2与YOLO9000目标检测系统Kaggle比赛金牌团队:图像比赛的通用套路有哪些?宜远智能刘凯:显著降低模型训练成本的主动增量学习———————————————————— via: http://mp.weixin.qq.com/s?__biz=MzI5NTIxNTg0OA==&mid=2247487824&idx=4&sn=c89dcba99bea57df186cfe5d46fbe4a0&scene=0#wechat_redirect
会议活动 深度学习 视觉 算法 语音 资源 自然语言处理 ICCV Kaggle Rich Family 分类 会议 机器翻译 刘斌 刘群 论文 强化学习 神经网络 书籍 孙兆民 王书浩 文仕学
「直播 | 深度好奇™算法工程师:用于文档理解的面向对象神经规划 | 学术青年分享会」分享内容▼深度好奇提出了用于垂直领域文档理解的OONP框架,它使用离散的对象本体图结构作为中间状态,该状态被OONP创建、更新直至最终输出。这个解析过程被OONP转化成为按照文本阅读顺序的离散动作的决策序列,模仿了人理解文本的认知程。OONP框架提供了神经符号主义的一个实例:在OONP框架内,连续信号、表示、操作和离散信号、表示、操作紧密结合,形成信息闭环。这使得OONP可以灵活地将各种先验知识用不同形式加入到行间记忆和策略网络中。为了优化OONP,深度好奇利用监督学习和强化学习以及二者的各种混合态,以适应不同强度和形式的监督信号以训练参数。 《Object-oriented Neural Programming (OONP) for Document Understanding》 论文地址: https://arxiv.org/abs/1709.08853 We propose Object-oriented Neural Programming (OONP), a framework for semantically parsing documents in specific domains. Basically, OONP reads a document and parses it into a predesigned object-oriented data structure (referred to as ontology in this paper) that reflects the domain-specific semantics of the document. An OONP parser models semantic parsing as a decision process: a neural net-based Reader sequentially goes through the document, and during the process it builds and updates an intermediate ontology to summarize its partial understanding of the text it covers. OONP supports a rich family of operations (both symbolic and differentiable) for composing the ontology, and a big variety of forms (both symbolic and differentiable) for representing the state and the document. An OONP parser can be trained with supervision of different forms and strength, including supervised learning (SL) , reinforcement learning (RL) and hybrid of the two. Our experiments on both synthetic and real-world document parsing tasks have shown that OONP can learn to handle fairly complicated ontology with training data of modest sizes. 分享主题▼Object-oriented Neural Programming (OONP) for Document Understanding用于文档理解的面向对象神经规划 分享人简介▼郑达奇,博士期间师从中科院计算所/都柏林城市大学刘群教授,后加入深度好奇。期间作为学术带头人在深度学习用于长文本生成等项目有重要贡献,参与了面向对象的神经规划、非线性文本表示等研究项目。郑博士长期从事机器翻译及人工智能的研究,在自然语言处理和神经符号智能等领域有较深的造诣。 分享时间▼北京时间10月25日(周三) 20:00 参与方式▼扫描海报二维码,点击底部菜单 复旦Ph.D沈志强:用于目标检测的DSOD模型(ICCV 2017)极限元刘斌:深度学习在语音生成问题上的典型应用搜狗文仕学:基于深度学习的语音分离Video ++孙兆民:视频内容识别行业分析悉尼科大王超岳:基于生成对抗网络的图像编辑方法达观数据张健:文本分类方法和应用案例 清华Ph.D王书浩:基于深度学习的电商交易欺诈检测系统Twitter工程师王东:详解YOLO2与YOLO9000目标检测系统Kaggle比赛金牌团队:图像比赛的通用套路有哪些?宜远智能刘凯:显著降低模型训练成本的主动增量学习———————————————————— via: http://mp.weixin.qq.com/s?__biz=MzI5NTIxNTg0OA==&mid=2247487824&idx=4&sn=c89dcba99bea57df186cfe5d46fbe4a0&scene=0#wechat_redirect
 网路冷眼 网页版 2017-10-25 07:00
网路冷眼 网页版 2017-10-25 07:00
应用 代码 信息检索
【Riot – Full-text search engine in Go】 http://t.cn/RWtkgUi Riot – 用Go实现的开源,分布式,简单高效的全文搜索引擎。1M条微博500M数据28秒索引完,1.65毫秒搜索响应时间,19K搜索QPS。
 网路冷眼 网页版 2017-10-25 06:30
网路冷眼 网页版 2017-10-25 06:30
会议活动 视觉 资源 Ian Goodfellow ICCV 会议 课程
【生成对抗网络知识资料全集(论文/代码/教程/视频/文章等) 】 http://t.cn/RWfGO72 当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开幕。Google Brain 研究科学家 Ian Goodfellow 在会上作为主题为《生成对…全文: http://m.weibo.cn/1715118170/4166624699325457
爱可可-爱生活 网页版 2017-10-25 06:20
Python
【Google内部Python Notebook工具Colab对外开放】 colab.research.google.com
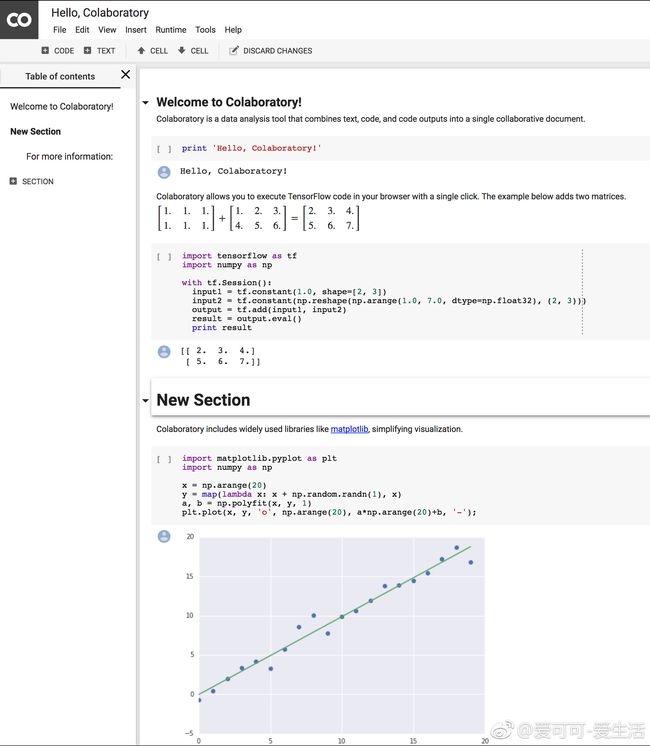 爱可可-爱生活 网页版 2017-10-25 05:38
爱可可-爱生活 网页版 2017-10-25 05:38
Jason Brownlee Python
【Python机器学习实践基础:NumPy数组索引/切片/重整】《How to Index, Slice and Reshape NumPy Arrays for Machine Learning in Python | Machine Learning Mastery》by Jason Brownlee http://t.cn/RWiEurt
