Go 协程(goroutine)与通道(channel)
协程
package main
import "time"
func main() {
go say("Hello World")
// 没有下一行,则主线程都结束了协程还没打印完说不定
time.Sleep(time.Second * 1)
}
func say(s string) {
println(s)
}
2.WaitGroup
package main
import (
"sync"
)
// 协程队列
var wg = sync.WaitGroup{}
func main() {
// 加入队列
wg.Add(1)
go say("Hello World")
// 告诉主线程等一下,等协程都执行完了在退出
wg.Wait()
}
func say(s string) {
println(s)
// 协程处理完毕 相当于 wg.Add(-1)
wg.Done()
}
同时启动多个协程的时候
package main
import (
"strconv"
"sync"
)
// 协程队列
var wg = sync.WaitGroup{}
func main() {
// 加入队列
wg.Add(5)
for i := 0; i < 5; i++ {
go say("Hello World" + strconv.Itoa(i))
}
// 告诉主线程等一下,等协程都执行完了在退出
wg.Wait()
}
func say(s string) {
println(s)
// 协程处理完毕
wg.Done()
}
看上去像是“同时执行”,其实这只是并发

并发 并行 核心数量
并发:单核CPU。同一时间只能执行一个程序,但是CPU却可以在不同程序之间快速切换
并行:多核CPU。CPU分别处理不同程序,一起执行。
// 设置核心数,模拟单核
runtime.GOMAXPROCS(1)
对于 n 个核心的情况设置 GOMAXPROCS 为 n-1 以获得最佳性能,也同样需要遵守这条规则:协程的数量 > 1 + GOMAXPROCS > 1。
用命令行指定使用的核心数量
使用 flags 包,如下:
var numCores = flag.Int("n", 2, "number of CPU cores to use")
在 main() 中:
flag.Parse()
runtime.GOMAXPROCS(*numCores)
channel
协程之间通信的渠道,消息队列
数据在通道中进行传递:在任何给定时间,一个数据被设计为只有一个协程可以对其访问,所以不会发生数据竞争。 数据的所有权(可以读写数据的能力)也因此被传递。
通常使用这样的格式来声明通道:var identifier chan datatype
- 未初始化的通道的值是nil。
- 只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface{}也可以。甚至可以(有时非常有用)创建通道的通道。
- 引用类型,使用make创建
- 先进先出(FIFO)的结构保证顺序
<-
流向通道
ch <- int1
从通道流出(三种)
int2 := <- ch int2未声明
int3 = <- ch int3已声明
// 单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证
if <- ch == 200 {
}
Eg:
package main
import (
"fmt"
"time"
)
func main() {
var ch = make(chan string)
go add(ch)
go delete(ch)
time.Sleep(time.Second * 1)
}
func add(ch chan string) {
ch <- "a"
ch <- "b"
ch <- "c"
}
func delete(ch chan string) {
var c string
for {
c = <- ch
fmt.Println(c)
}
}
通道阻塞
需求,把输出结果返回给主线程:
package main
import "strconv"
func main() {
var result = make(chan string)
for i := 0; i < 5; i++ {
go say("111" + strconv.Itoa(i), result)
}
var i = 0
for res := range result {
println(res)
// 主动关闭管道。如果不关闭,则最后会报错
// fatal error: all goroutines are asleep - deadlock!
if i >= 4 {
close(result)
}
i++
}
}
func say(s string, c chan string) {
c <- s
}
go的管道默认是阻塞的(假如你不设置缓存的话),你那边放一个,我这头才能取一个,如果你那边放了东西这边没人取,程序就会一直等下去,死锁了,同时,如果那边没人放东西,你这边取也取不到,也会发生死锁!
无缓冲通道
package main
import (
"fmt"
)
func f1(in chan int) {
fmt.Println(<-in)
}
func main() {
out := make(chan int)
out <- 2
go f1(out)
}

带缓冲的通道
ch1 := make(chan string, buf)
在缓冲满载(缓冲被全部使用)之前,给一个带缓冲的通道发送数据是不会阻塞的,而从通道读取数据也不会阻塞,直到缓冲空了。
信号量模式
协程通过在通道 ch 中放置一个值来处理结束的信号。main 协程等待 <-ch 直到从中获取到值。
package main
import "fmt"
type Empty interface {}
var empty Empty
func doSomethings(index int, value int) int {
return index * 2 + value
}
func main() {
data := make([]int, 10)
res := make([]int, 10)
sem := make(chan Empty, 10) // 信号量通道
for index, value := range data {
go func(index int, value int) {
res[index] = doSomethings(index, value)
sem <- empty
}(index, value)
}
// 在循环中从通道 sem 不停的接收数据来等待所有的协程完成。
for i := 0; i < 10; i++ {
<- sem
}
fmt.Println(res) // [0 2 4 6 8 10 12 14 16 18]
}
通道工厂模式
package main
import (
"fmt"
"time"
)
func main() {
stream := pump()
go suck(stream)
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
for-range
可以从通道中获取值:
package main
import (
"fmt"
"time"
)
func main() {
suck(pump())
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
go func() {
for v := range ch {
fmt.Println(v)
}
}()
}
通道类型 只发送或只接受
var send_only chan<- int // channel can only receive data
var recv_only <-chan int // channel can only send data
func main() {
var c = make(chan int) // 双向
go source(c)
go sink(c)
}
func source(ch chan<- int){ // 只写
for { ch <- 1 }
}
func sink(ch <-chan int) { // 只读
for { fmt.Print(<-ch) }
}
管道和选择器模式
协程处理它从通道接收的数据并发送给输出通道:
sendChan := make(chan int)
receiveChan := make(chan string)
go processChannel(sendChan, receiveChan)
func processChannel(in <-chan int, out chan<- string) {
for inValue := range in {
result := ... /// processing inValue
out <- result
}
}
Eg:打印了输出的素数,使用选择器(‘筛’)作为它的算法
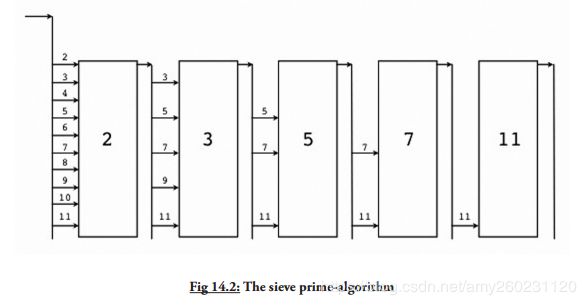
package main
import "fmt"
// 素数筛选
// 获取start~end范围内的所有数
func produceNumbers(start, end int, out chan<- int) {
for i := start; i < end ; i++ {
out <- i
}
}
// 根据筛选器筛选出合适的数放入新的chan
func selectNum(in <-chan int, out chan<- int, firstNum int) {
for number := range in {
if number % firstNum != 0 {
out <- number
}
}
}
const (
start = 2
end = 12
)
func main() {
numbers := make(chan int)
go produceNumbers(start, end, numbers)
// 如果不定义次数,那么输出的素数结束后会进入死锁
for i := 0; i < 5; i++ {
firstNum := <- numbers
fmt.Println(firstNum)
newNumbers := make(chan int)
go selectNum(numbers, newNumbers, firstNum)
numbers = newNumbers
}
}
关闭通道-测试阻塞的通道
只有在当需要告诉接收者不会再提供新的值的时候,才需要关闭通道。只有发送者需要关闭通道,接收者永远不会需要。
第一个可以通过函数 close(ch) 来完成:这个将通道标记为无法通过发送操作 <- 接受更多的值;给已经关闭的通道发送或者再次关闭都会导致运行时的 panic。在创建一个通道后使用 defer 语句是个不错的办法(类似这种情况):
ch := make(chan float64)
defer close(ch)
第二个问题可以使用逗号,ok 操作符:用来检测通道是否被关闭。
如何来检测可以收到没有被阻塞(或者通道没有被关闭)?
if v, ok := <-ch; ok {
process(v)
}
v, ok := <-ch
if !ok {
break
}
process(v)
使用 select 切换协程
你准备好了吗? 的询问机制
select {
case u:= <- ch1: // 监听ch1管道输出数据
...
case ch2 <- x: // 监听向ch2管道输入数据
...
...
default: // no value ready to be received
...
}
计时器(Ticker)
time.Ticker 结构体,这个对象以指定的时间间隔重复的向通道 C 发送时间值:
type Ticker struct {
C <-chan Time // the channel on which the ticks are delivered.
// contains filtered or unexported fields
...
}
ticker := time.NewTicker(updateInterval) // 工厂创建ticker
defer ticker.Stop()
...
select {
case u:= <-ch1:
...
case v:= <-ch2:
...
case <-ticker.C: // 当向管道输入数时,log
logState(status) // call some logging function logState
default: // no value ready to be received
...
}
当你想返回一个通道而不必关闭它的时候这个函数非常有用:
time.Tick() 函数声明为 Tick(d Duration) <-chan Time
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(1e8) // 每一秒操作一次
boom := time.After(5e8) // 5秒后
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(5e7)
}
}
}
简单超时模式
package main
import (
"fmt"
"time"
)
func main() {
timeout := make(chan bool, 1)
go func() {
time.Sleep(2e9)
timeout <- true
}()
ch := make(chan int)
go func() {
time.Sleep(3e9)
ch <- 1
}()
select {
case value := <- ch:
fmt.Println("read for ch", value)
case value := <- timeout: // 如果在timeout之前没收到ch管道里的数据,那么超时
fmt.Println("read from timeout", value)
break;
}
}
协程和恢复(recover)
一个用到 recover 的程序停掉了服务器内部一个失败的协程而不影响其他协程的工作。
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work) // start the goroutine for that work
}
}
func safelyDo(work *Work) {
defer func() {
if err := recover(); err != nil {
log.Printf("Work failed with %s in %v", err, work)
}
}()
do(work)
}
该使用锁还是通道
假设我们需要处理很多任务;一个worker处理一项任务。任务可以被定义为一个结构体
- 用锁:为了同步各个worker以及避免资源竞争,我们需要对任务池进行加锁保护
type Pool struct {
Mu sync.Mutex
Tasks []*Task
}
func Worker(pool *Pool) {
for {
pool.Mu.Lock()
// begin critical section:
task := pool.Tasks[0] // take the first task
pool.Tasks = pool.Tasks[1:] // update the pool of tasks
// end critical section
pool.Mu.Unlock()
process(task)
}
}
- 使用通道:使用一个通道接受需要处理的任务,一个通道接受处理完成的任务(及其结果)。worker数量为N
func main() {
pending, done := make(chan *Task), make(chan *Task)
go sendWork(pending) // put tasks with work on the channel
for i := 0; i < N; i++ { // start N goroutines to do work
go Worker(pending, done)
}
consumeWork(done) // continue with the processed tasks
}
worker的逻辑比较简单:从pending通道拿任务,处理后将其放到done通道中:
func Worker(in, out chan *Task) {
for {
t := <-in
process(t)
out <- t
}
}
使用锁的情景:
- 访问共享数据结构中的缓存信息
- 保存应用程序上下文和状态信息数据
- 使用通道的情景:
使用通道的情景:
- 与异步操作的结果进行交互
- 分发任务
- 传递数据所有权
实现 Futures 模式
有时候在你使用某一个值之前需要先对其进行计算。这种情况下,你就可以在另一个处理器上进行该值的计算,到使用时,该值就已经计算完毕了。
也就是并行處理
链式协程
package main
import (
"flag"
"fmt"
)
var ngoroutine = flag.Int("n", 100000, "how many goroutines")
func f(left, right chan int) { left <- 1 + <-right }
func main() {
flag.Parse()
leftmost := make(chan int)
var left, right chan int = nil, leftmost
for i := 0; i < *ngoroutine; i++ {
left, right = right, make(chan int)
go f(left, right)
}
right <- 0 // bang!
x := <-leftmost // wait for completion
fmt.Println(x) // 100000, ongeveer 1,5 s
}

并行化处理大量数据
让每一个处理步骤作为一个协程独立工作。每一个步骤从上一步的输出通道中获得输入数据。这种方式仅有极少数时间会被浪费,而大部分时间所有的步骤都在一直执行中:
func ParallelProcessData (in <-chan *Data, out chan<- *Data) {
// make channels:
preOut := make(chan *Data, 100)
stepAOut := make(chan *Data, 100)
stepBOut := make(chan *Data, 100)
stepCOut := make(chan *Data, 100)
// start parallel computations:
go PreprocessData(in, preOut)
go ProcessStepA(preOut,StepAOut)
go ProcessStepB(StepAOut,StepBOut)
go ProcessStepC(StepBOut,StepCOut)
go PostProcessData(StepCOut,out)
}
对Go协程进行基准测试
使用testing.Benchmark