数据库期末复习提纲
数据库期末复习提纲
高频单词
- Integrity 完整
- Constraint 约束
- property 性质
- Schema 模式
- Entity 实体
- tuple 元组
- domain 域
- Algebra 代数
- specify 指定,列举
- denote 表示,指示
- Operand 运算对象
- duplicate 复制
- Cartesian Product 笛卡尔积
- Intersection 交集
- Derived 衍生的
- Aggregation 聚合关系
- Restriction 限制
- Explicit 明确的
- comprise 包含
- mandatory 强制的
- authorization 授权
- audit 审计
- plain text 明文
- cipher text 密文
- encryption key 密钥
- cascade 级联
- serial 连续的
- equivalent 等价的
- Atomicity 原子性
- Consistency 一致性
- Isolation 隔离性
- Durability 持久性
01-Introduction
数据是较低的抽象层次; 是信息的载体,信息是数据的解释
数据操作的主要类别:
- 数据管理——数据库
- 数据处理——电脑程序
- 数据传输——计算机网络
数据管理任务
数据存储
组织数据并将其存储到硬盘等存储设备中;
数据维护
插入新值,删除无效数据或修改旧数据;
数据查询和数据统计
从数据存储中检索信息

将数据存储很长一段时间要求应用
- 大容量(上百GB)
- 防止崩溃
- 防止未经授权的使用
- 允许多个(100个,1000个)用户同时访问数据
- 允许管理员更改模式
S(tructured) Q(uery) L(anguage)
数据库的优点
- 隔离并发访问
- 防止脏数据的使用
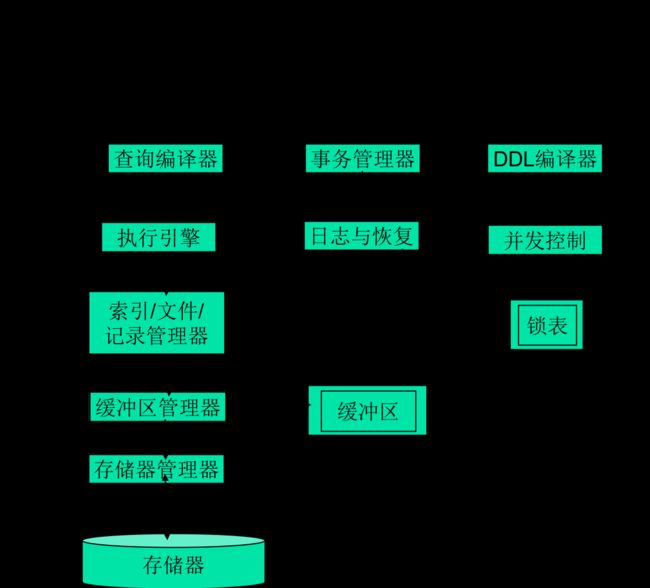
ACID
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必须要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的,交易过程极可能达不到交易方的要求。
02-Data Model (ER model)
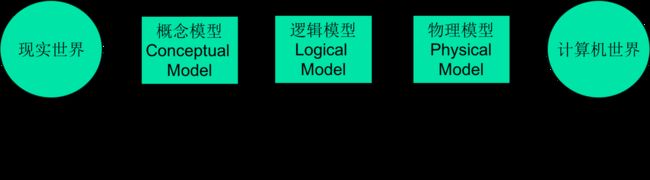
概念模型
记录和组织职能和技术人员之间的沟通数据
逻辑模型
描述数据库中的数据语义,数据关系,数据约束和数据操作
物理模型
描述数据在存储设备中的组织方式

对于二元关系集合,映射基数必须是以下类型之一:
- One to one
- One to many
- Many to one
- Many to many
基数约束的替代表示法

03-ER Model (Cont.)
查找约束是建模过程的一部分。
常用约束:
- key:居民身份证号码唯一标识一个人。
- 单值约束:一个人只能有一个父亲。
- 参照完整性约束:如果你为公司工作,它必须存在于数据库中。
- 域限制:人们的年龄在0到150之间。
- 一般限制:所有其他人(最多50名学生参加班级)
弱实体集
- 没有主键的实体集被称为弱实体集。
- 一个弱实体集的存在取决于一个识别实体集的存在
- 弱实体集合的鉴别符(或部分关键字)是区分弱实体集合中依赖于一个特定强实体的所有实体的属性集合。
- 弱实体集的主键由弱实体集依赖于存在的强实体集的主键和弱实体集的鉴别器构成。
设计技术
- 避免冗余
- 限制弱实体集的使用
- 当属性执行时不要使用实体集
什么时候我们需要弱实体集
- 通常的原因是没有能够创建唯一ID的全局权威字段。
- 例如:在世界上所有足球队中都不可能有一个协议来分配唯一的球员号码。
04-Relation Model
Logical Data Model
- 表示业务领域的抽象信息结构
- 对模型的定义明确无误
- 在DBMS中实施,进行调整以实现计算系统的效率。
- 逻辑数据模型的三个要素:
- 数据结构
- 数据操作
- 数据限制

ER Model vs. Relational Model
- 两者都用于模拟数据
- ER模型有许多概念
- 实体,关系,属性等
- 非常适合捕获应用程序需求
- 不太适合计算机实施(甚至没有对其结构进行操作)
- 关系模型
- 只有一个概念:关系
- 世界是由一系列表格来表示的
- 非常适合在计算机上进行高效操作
Schemas vs. instances
类比编程语言:
Schema = type
Instance = value
Schema
对应于类型定义的编程语言概念
关系模式:关系名称和属性名称
数据库模式:一组关系模式
长时间稳定
Instance
对应于变量值的编程语言概念
不断变化,因为数据被插入/更新/删除

Updates
数据库维护当前的数据库状态。
数据更新:
- 添加一个元组
- 删除一个元组
- 修改元组中的属性
数据更新发生得非常频繁。
对Schema的更新:比较少见。
Relation’s features
- 不允许具有相同值的元组
- 关系无序(元组和属性的顺序都是无关紧要的)
- 属性值必须符合域约束(同一属性名下的各个属性值必须来自同一个域,是同一类型的数据)
- 每个属性必须具有不同的名称
- 不同的属性可以使用同一个域
- 属性值必须是原子的、不可分割的
05-Relational Model (Cont.)
将实体集合E的关系与关于从E到另一个实体集合的多对一关系的关系R组合起来是可以的。
弱实体集合的关系必须包括其完整关键字(包括属于其他实体集合的关键字)的属性以及它自己的非关键属性。
Integrity Constraints(完整性约束)
目的:防止数据中的语义不一致
Entity Integrity Constraints(实体完整性约束)
- 由主键定义
- 主键是唯一指定行的列的组合
- 主键不能允许空值。 (您不能在允许空值的列上定义主键。)
- 每个表最多只能有一个主键。
唯一键约束
- 唯一键可唯一标识表中的每一行。 也就是说,表中没有两个不同的行可以在由唯一键约束的列中具有相同的值(或值的组合)。
- 一个唯一的键可以允许空值。 (您可以在允许空值的列上定义唯一键。)
- 每个表可以有多个唯一键。
Referential Integrity Constraints(参照完整性约束)
- 参照完整性是数据的一种属性,当满足时,要求关系(表)的一个属性(列)的每个值作为不同(或相同)关系(表)中的另一个属性的值存在。
- 为了保持关系数据库中的参照完整性,声明为外键的表中的任何字段只能包含来自父表的主键或候选键的值
06-Relational Algebra
查询数据库
使用高级查询语言:
- 理论:关系代数,Datalog
- 实用:SQL
- 关系代数:提供基本原则的关系操作的基本集合
五种基本关系代数运算
集合操作
union(并集)
在R1或R2中所有元组,没有重复元组
符号: R1UR2 R 1 U R 2
R1 R 1 , R2 R 2 必须具有相同的模式, R1UR2 R 1 U R 2 与 R1 R 1 , R2 R 2 具有相同的模式
Difference(差集)
所有在 R1 R 1 但不在 R2 R 2 的元组
符号: R1–R2 R 1 – R 2
R1 R 1 , R2 R 2 必须具有相同的模式, R1−R2 R 1 − R 2 与 R1 R 1 , R2 R 2 具有相同的模式
Selection(选择)
返回满足条件的所有元组
符号: σc(R) σ c ( R ) , c c 是一个条件:=,<,>,与,或,非
输出模式与输入模式相同
Projection(投影)
一元操作:返回某些列
符号: ∏A1,…,An(R) ∏ A 1 , … , A n ( R )
Cartesian Product(笛卡尔积)
符号: R1×R2 R 1 × R 2
输入模式: R1(A1,…,An),R2(B1,…,Bm) R 1 ( A 1 , … , A n ) , R 2 ( B 1 , … , B m )
输出模式: S(A1,…,An,B1,…,Bm) S ( A 1 , … , A n , B 1 , … , B m )
衍生的关系代数运算
Intersection(交集)
同时被 R1 R 1 、 R2 R 2 包含的元组
符号: R1∩R2 R 1 ∩ R 2
R1 R 1 , R2 R 2 必须具有相同的模式, R1∩R2 R 1 ∩ R 2 与 R1 R 1 , R2 R 2 具有相同的模式
R1∩R2=R1–(R1–R2) R 1 ∩ R 2 = R 1 – ( R 1 – R 2 )
join(连接)
θ θ 连接
涉及谓词的连接
符号: R1⋈θR2 R 1 ⋈ θ R 2 , θ θ 是一个条件
输入模式: R1(A1,…,An),R2(B1,…,Bm) R 1 ( A 1 , … , A n ) , R 2 ( B 1 , … , B m )
输出模式: S(A1,…,An,B1,…,Bm) S ( A 1 , … , A n , B 1 , … , B m )
自然连接
符号: R1⋈R2 R 1 ⋈ R 2
输入模式: R1(A1,…,An),R2(B1,…,Bm) R 1 ( A 1 , … , A n ) , R 2 ( B 1 , … , B m )
输出模式: S(C1,…,Cp) S ( C 1 , … , C p ) where C1,…,Cp=A1,…,AnUB1,…,Bm C 1 , … , C p = A 1 , … , A n U B 1 , … , B m
含义:将R1和R2中的所有元组进行合并,以确定属性: A1,...,AnB1,...,Bm A 1 , . . . , A n B 1 , . . . , B m (称为连接属性)
等值连接
符号: R1⋈A=BR2 R 1 ⋈ A = B R 2
自然连接是一种特殊的等值连接
外连接
左外连接 = 自然连接 + 左侧表中失配的元组。
右外连接 = 自然连接 + 右侧表中失配的元组。
全外连接 = 自然连接 + 两侧表中失配的元组。
Division(除运算)
设 R(X,Y) R ( X , Y ) 和 S(Y) S ( Y ) 是两个关系,则 R÷S=∏X(R)−∏X((∏X(R)×S)−R) R ÷ S = ∏ X ( R ) − ∏ X ( ( ∏ X ( R ) × S ) − R )
符号: R÷S R ÷ S

构建复杂的表达式
代数允许我们以自然的方式表达操作序列。
关系代数有局限性
不能计算传递闭包
07-SQL
- DDL(Data Definition Language), 数据定义语言,用于定义数据库模式
- Query Language 数据查询语言,根据用户需求从数据库中提取数据
- DML(Data Manipulation language), ,数据操纵语言,修改数据库实例,即插入,更新或删除数据
- DCL(Data Control language),数据控制语言,包括数据库约束,用户认证等。
Select-From-Where
略
between-and
范围比较
in
IN <值表>
<值表>:用逗号分隔的一组取值
like
- s LIKE p: pattern matching on strings
- p may contain two special symbols:
- % = any sequence of characters
- _ = any single character
- 转义符\
Order by
使用’Order by’子句来指定查询结果的字母顺序
对于每个属性,我们可以指定desc为降序或asc为升序, 升序是默认的。
注意:Order by只能用作select语句的最后一部分
NULL value
SQL关系中的元组可以具有NULL作为一个或多个组件的值。意义取决于上下文。 有两种常见情况:
- 缺失值:我们知道乔的酒吧有一些地址,但我们不知道它是什么。
- 不适用:例如,未婚人士的属性配偶的价值。
逻辑上不属于true或false,属于unknown
聚合关系
可以将SUM,AVG,COUNT,MIN和MAX应用于SELECT子句中的列以在该列上生成该聚合。
另外,COUNT(*)计算元组的数量。
DISTINCT短语:在计算时要取消指定列中的重复值
ALL短语:不取消重复值,ALL为缺省值
NULL从不贡献于总和,平均值或计数,并且绝不能是列的最小值或最大值。
但是,如果列中不存在非NULL值,那么聚合的结果为NULL。
Grouping
我们可以通过GROUP BY和一系列属性来跟踪SELECT-FROM-WHERE表达式。
SELECT-FROM-WHERE产生的关系根据所有这些属性的值进行分组,并且任何聚合仅应用于每个组中。
having
HAVING 可以在GROUP BY子句后。如果是这样,则该条件适用于每个组,并且不满足该条件的组被消除。
08-SQL cont
create table
PRIMARY KEY
UNIQUE
增加属性
ALTER TABLE ADD
; 删除属性
ALTER TABLE
DROP ; 插入元组
INSERT INTO
VALUES ( of
values> );删除元组
DELETE FROM
WHERE ; 删除所有元组
DELETE FROM ; 更新属性
UPDATE
SET of
attribute assignments>
WHERE on tuples>; 视图
一个视图是一个“虚拟表”,这个关系是根据其他表和视图的内容定义的。与此相反,其值真正存储在数据库中的关系称为基本表。
创建视图:
CREATE VIEW AS ; 以SELECT *方式创建的视图可扩充性差,应尽可能避免
索引
语句格式
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);- 用
<表名>指定要建索引的基本表名字 - 索引可以建立在该表的一列或多列上,各列名之间用逗号分隔
- 用
<次序>指定索引值的排列次序,升序:ASC,降序:DESC。缺省值:ASC UNIQUE表明此索引的每一个索引值只对应唯一的数据记录,对于已含重复值的属性列不能建UNIQUE索引
,对某个列建立UNIQUE索引后,插入新记录时DBMS会自动检查新记录在该列上是否取了重复值。这相当于增加了一个UNIQUE约束CLUSTER表示要建立的索引是聚簇索引,建立聚簇索引后,基表中数据也需要按指定的聚簇属性值的升序或降序存放。也即聚簇索引的索引项顺序与表中记录的物理顺序一致
聚簇索引
- 在一个基本表上最多只能建立一个聚簇索引
- 聚簇索引的用途:对于基于聚簇索引列的查询(特别是范围查询),可以提高查询效率
- 聚簇索引的适用范围
- 聚簇索引列存在大量非重复值
- 很少对基表进行增删操作
- 很少对其中的变长列进行修改操作
09-规范化理论
First Normal Form(第一范式)
定义:如果关系模式 R R ,其所有的属性均为简单属性,即每个属性都是不可再分的,则称R属于第一范式,简称 1NF 1 N F ,记作 R∈1NF R ∈ 1 N F 。
在讨论关系的性质时,我们把满足这个条件的关系称为规范化关系。
在关系数据库系统中只讨论规范化的关系,凡是非规范化的关系模式必须化成规范化的关系。
在非规范化的关系中去掉组合项就能化成规范化的关系。
每个规范化的关系都属于1NF,这也是它之所以称为“第一”的原因。
Second Normal Form(第二范式)
定义:如果关系模式 R∈1NF R ∈ 1 N F ,且每个非主属性都完全函数依赖于 R R 的每个关系键,则称R属于第二范式,简称 2NF 2 N F ,记作 R∈2NF R ∈ 2 N F 。
关系键:设关系模式R的属性集是 U U , X X 是 U U 的一个子集。如果 X→U X → U 在 R R 上成立,那么称 X X 是 R R 的一个超键。如果 X→U X → U 在 R R 上成立,但对于X的任一真子集 X1 X 1 都有 X1→U X 1 → U 不成立,那么称 X X 是 R R 上的一个候选键。可任意指定一个候选键为主键。在任一候选键中出现过的属性成为主属性。
经以上分析,可以得到两个结论:
- 从 1NF 1 N F 关系中消除非主属性对关系键的部分函数依赖,则可得到 2NF 2 N F 关系。
- 如果R的关系键为单属性,或 R R 的全体属性均为主属性,则 R∈2NF R ∈ 2 N F 。
2NF 2 N F 的关系模式解决了 1NF 1 N F 中存在的一些问题, 2NF 2 N F 规范化的程度比 1NF 1 N F 前进了一步,但2NF的关系模式在进行数据操作时,仍然存在着一些问题:
- 数据冗余。每个系名和系主任的名字存储的次数等于该系的学生人数。
- 插入异常。当一个新系没有招生时,有关该系的信息无法插入。
- 删除异常。某系学生全部毕业而没有招生时,删除全部学生的记录也随之删除了该系的有关信息。
- 更新异常。更换系主任时,仍需改动较多的学生记录。
Third Normal Form(第三范式)
定义:如果关系模式 R∈2NF R ∈ 2 N F ,且每个非主属性都不传递依赖于 R R 的每个关系键,则称 R R 属于第三范式(Third Normal Form),简称 3NF 3 N F ,记作 R∈3NF R ∈ 3 N F 。
如果 R∈3NF R ∈ 3 N F ,则 R R 也是 2NF 2 N F ,如果 R∈2NF R ∈ 2 N F ,则 R R 不一定是 3NF 3 N F 。
3NF 3 N F 规范化是指把 2NF 2 N F 关系模式通过投影分解转换成 3NF 3 N F 关系模式的集合。
和 2NF 2 N F 的规范化时遵循的原则相同,即“一事一表”,让一个关系只描述一个实体或者实体间的联系。
但是,3NF只限制了非主属性对键的依赖关系,而没有限制主属性对键的依赖关系。如果发生了这种依赖,仍有可能存在数据冗余、插入异常、删除异常和修改异常。这时,则需对3NF进一步规范化,消除主属性对键的依赖关系,为了解决这种问题,Boyce与Codd共同提出了一个新范式的定义,这就是Boyce-Codd范式,通常简称BCNF或BC范式。它弥补了3NF的不足。
BC范式
定义:如果关系模式 R∈1NF R ∈ 1 N F ,且所有的函数依赖 X→Y(Y∉X) X → Y ( Y ∉ X ) ,决定因素 X X 都包含了 R R 的一个候选键,则称 R R 属于BC范式(Boyce-Codd Normal Form),记作 R∈BCNF R ∈ B C N F 。
BCNF具有如下性质:
- 满足BCNF的关系将消除任何属性(主属性或非主属性)对键的部分函数依赖和传递函数依赖。也就是说,如果 R∈BCNF R ∈ B C N F ,则 R R 也是 3NF 3 N F 。
- 如果 R∈3NF R ∈ 3 N F ,则 R R 不一定是 BCNF B C N F 。
BCNF规范化是指把3NF关系模式通过投影分解转换成BCNF关系模式的集合。
关系模式的规范化
规范化的基本原则就是遵从概念单一化“一事一表”的原则,即一个关系只描述一个实体或者实体间的联系。
关系模式规范化的步骤,规范化就是对原关系进行投影,消除决定属性不是候选键的任何函数依赖。具体可以分为以下几步:
- 对1NF关系进行投影,消除原关系中非主属性对键的部分函数依赖,将1NF关系转换成若干个2NF关系。
- 对2NF关系进行投影,消除原关系中非主属性对键的传递函数依赖,将2NF关系转换成若干个3NF关系。
- 对3NF关系进行投影,消除原关系中主属性对键的部分函数依赖和传递函数依赖,也就是说使决定因素都包含一个候选键。得到一组BCNF关系。
关系模式规范化的要求:
- 关系模式的规范化过程是通过对关系模式的投影分解来实现的,但是投影分解方法不是唯一的,不同的投影分解会得到不同的结果。
- 在这些分解方法中,只有能够保证分解后的关系模式与原关系模式等价的方法才是有意义的。
无损连接性(Lossless Join):设关系模式 R(U,F) R ( U , F ) 被分解为若干个关系模式 R1(U1,F1),R2(U2,F2),…,Rn(Un,Fn) R 1 ( U 1 , F 1 ) , R 2 ( U 2 , F 2 ) , … , R n ( U n , F n ) ,其中 U=U1U2…UN U = U 1 U 2 … U N ,且不存在 UNUj U N U j 式, Fi F i 为 F F 在 Uj U j 上的投影,如果 R R 与 R1,R2,…,Rn R 1 , R 2 , … , R n 自然连接的结果相等,则称关系模式 R R 的分解具有无损连接性。
函数依赖保持性(Preserve Dependency):设关系模式 R(U,F) R ( U , F ) 被分解为若干个关系模式 R1(U1,F1),R2(U2,F2),…,Rn(Un,Fn) R 1 ( U 1 , F 1 ) , R 2 ( U 2 , F 2 ) , … , R n ( U n , F n ) ,其中 U=U1U2…UN U = U 1 U 2 … U N ,且不存在 UNUj U N U j 式, Fi F i 为 F F 在 Uj U j 上的投影;如果 F F 所蕴含的任意一个函数依赖一定也由 (F1∪F2…∪Fn) ( F 1 ∪ F 2 … ∪ F n ) 所蕴含,则称关系模式 R R 的分解具有函数依赖保持性。
判断对关系模式的一个分解是否与原关系模式等价可以有三种不同的标准:
- 分解要具有无损连接性。
- 分解要具有函数依赖保持性。
- 分解既要具有无损连接性,又要具有函数依赖保持性。
如果一个分解具有无损连接性,则能够保证不丢失信息。如果一个分解具有函数依赖保持性,则可以减轻或解决各种异常情况。
分解具有无损连接性和函数依赖保持性是两个相互独立的标准。具有无损连接性的分解不一定具有函数依赖保持性。同样,具有函数依赖保持性的分解也不一定具有无损连接性。
规范化理论提供了一套完整的模式分解方法,按照这套算法可以做到:如果要求分解既具有无损连接性,又具有函数依赖保持性,则分解一定能够达到3NF,但不一定能够达到BCNF。所以在3NF的规范化中,既要检查分解是否具有无损连接性,又要检查分解是否具有函数依赖保持性。只有这两条都满足,才能保证分解的正确性和有效性,才既不会发生信息丢失,又保证关系中的数据满足完整性约束。
非规范化设计
- 许多数据库应用强调性能优先
- 规范化设计有时会导致数据库运行效率的下降
- 在特殊条件和要求下,适当地降低甚至抛弃关系模式的范式,不再要求一个表只描述一个实体或者实体间的一种联系。其主要目的在于提高数据库的运行效率。
- 一般认为,在下列情况下可以考虑进行非规范化处理:
- 大量频繁的查询过程所涉及的表都需要进行连接
- 主要的应用程序在执行时要将表连接起来进行查询
- 对数据的计算需要临时表或进行复杂的查询
- 非规范化处理的主要技术包括增加冗余或派生列,对表进行合并、分割或增加重复表。增加派生列指增加的列来自其它表中的数据,由它们计算生成。它的作用是在查询时减少连接操作,避免使用集函数。派生列也具有与冗余列同样的缺点。
有时对表做分割可以提高性能。表分割有水平分割和垂直分割两种方式。
水平分割:根据一列或多列数据的值把数据行放到两个独立的表中。
水平分割通常在下面的情况下使用。
- 表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
- 表中的数据本来就有独立性,例如表中分别记录各个地区的数据或不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
- 需要把数据存放到多个介质上。
水平分割会给应用增加复杂度,它通常在查询时需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点。
垂直分割:把主键和一些列放到一个表,然后把主键和另外的列放到另一个表中。
如果一个表中某些列常用,而另外一些列不常用,则可以采用垂直分割加快查询速度。其缺点是需要管理冗余列,查询所有数据需要join操作。
非规范化设计的主要优点:
- 减少了查询操作所需的连接
- 减少了外部键和索引的数量
- 可以预先进行统计计算,提高了查询时的响应速度
非规范化存在的主要问题:
- 增加了数据冗余
- 影响数据库的完整性
- 降低了数据更新的速度
- 增加了存储表所占用的物理空间
无论使用何种非规范化技术,都需要一定的管理来维护数据的完整性。管理方式有很多,最好的是用触发器来实现。对数据的任何修改立即触发对复制列或派生列的相应修改。触发器是实时的,而且相应的处理逻辑只在一个地方出现,易于维护。
10-规范化理论(续)
规范化问题的提出
关系数据库的规范化理论主要包括三个方面的内容:
- 函数信赖
- 范式(Normal Form)
- 模式设计
其中,函数信赖起着核心的作用,是模式分解和模式设计的基础,范式是模式分解的标准。
函数依赖的定义:设关系模式 R(U,F) R ( U , F ) , U U 是属性全集, F F 是 U U 上的函数依赖集, X X 和 Y Y 是 U U 的子集,如果对于 R(U) R ( U ) 的任意一个可能的关系 r r ,对于 X X 的每一个具体值, Y Y 都有唯一的具体值与之对应,则称 X X 决定函数 Y Y ,或 Y Y 函数依赖于 X X ,记作 X→Y X → Y 。我们称 X X 为决定因素, Y Y 为依赖因素。当 Y Y 不函数依赖于X时,记作: X↛Y X ↛ Y 。当 X\toY X \toY 且 Y→X Y → X 时,则记作: X↔Y X ↔ Y 。
当属性集 Y Y 是属性集 X X 的子集时,则必然存在着函数依赖 X→Y X → Y ,这种类型的函数依赖称为平凡的函数依赖。如果 Y Y 不是 X X 的子集,则称 X→Y X → Y 为非平凡的函数依赖。若不特别声明,我们讨论的都是非平凡的函数依赖。
函数依赖关系的存在与时间无关,而只与数据之间的语义规定有关。
函数依赖的定义及性质
函数依赖的基本性质:
投影性
根据平凡的函数依赖的定义可知,一组属性函数决定它的所有子集。
扩张性
若 X→Y X → Y 且 W→Z W → Z ,则 (X,W)→(Y,Z) ( X , W ) → ( Y , Z ) 。
合并性
若 X→Y X → Y 且 X→Z X → Z 则必有 X→(Y,Z) X → ( Y , Z ) 。
分解性
若 X→(Y,Z) X → ( Y , Z ) ,则 X→Y X → Y 且 X→Z X → Z 。很显然,分解性为合并性的逆过程。
由合并性和分解性,很容易得到以下事实:
X→A1,A2,…,An成立的充分必要条件是X→Ai(i=1,2,…,n)成立。
完全函数依赖与部分函数依赖

只有当决定因素是组合属性时,讨论部分函数依赖才有意义,当决定因素是单属性时,只能是完全函数依赖。
传递函数依赖

函数依赖分为完全函数依赖、部分函数依赖和传递函数依赖三类,它们是规范化理论的依据和规范化程度的准则。
11-需求分析
数据库设计内容
数据库设计包括数据库的结构设计和数据库的行为设计两方面的内容。
数据库的结构设计
数据库的结构设计是指根据给定的应用环境,进行数据库的模式的设计。
它包括数据库的概念设计、逻辑设计和物理设计。
数据库模式是各应用程序共享的结构,是静态的、稳定的,一经形成后通常情况下是不容易改变的,所以结构设计又称为静态模型设计。
数据库的行为设计
数据库的行为设计是指确定数据库用户的行为和动作。而在数据库系统中,用户的行为和动作指用户对数据库的操作,这些要通过应用程序来实现,所以数据库的行为设计就是应用程序的设计。
用户的行为总是使数据库的内容发生变化,所以行为设计是动态的,行为设计又称为动态模型设计。
数据库设计方法
数据库设计方法主要有直观设计法和规范设计法
直观设计法也叫手工试凑法,它是最早使用的数据库设计方法。这种方法依赖于设计者的经验和技巧,缺乏科学理论和工程原则的支持,设计的质量很难保证,常常是数据库运行一段时间后又发现各种问题,这样再重新进行修改,增加了系统维护的代价。因此这种方法越来越不适应信息管理发展的需要。
下面简单介绍几种常用的规范设计方法:
基于E-R模型的数据库设计方法
其基本思想是在需求分析的基础上,用E-R(实体—联系)图构造一个反映现实世界实体之间联系的企业模式,然后再将此企业模式转换成基于某一特定的DBMS的概念模式。
基于3NF的数据库设计方法
其基本思想是在需求分析的基础上,确定数据库模式中的全部属性和属性间的依赖关系,将它们组织在一个单一的关系模式中,然后再分析模式中不符合3NF的约束条件,将其进行投影分解,规范成若干个3NF关系模式的集合。
其具体设计步骤分为五个阶段:
- 设计企业模式,利用规范化得到的3NF关系模式画出企业模式;
- 设计数据库的概念模式,把企业模式转换成DBMS所能接受的概念模式,并根据概念模式导出各个应用的外模式;
- 设计数据库的物理模式(存储模式);
- 对物理模式进行评价;
- 实现数据库。
基于视图的数据库设计方法
此方法先从分析各个应用的数据着手,其基本思想是为每个应用建立自己的视图,然后再把这些视图汇总起来合并成整个数据库的概念模式。合并过程中要解决以下问题:
- 消除命名冲突;
- 消除冗余的实体和联系;
- 进行模式重构,在消除了命名冲突和冗余后,需要对整个汇总模式进行调整,使其满足全部完整性约束条件。
数据库设计的步骤
按规范设计法可将数据库设计分为六个阶段:
- 系统需求分析阶段
- 概念结构设计阶段
- 逻辑结构设计阶段
- 物理设计阶段
- 数据库实施阶段
- 数据库运行与维护阶段
前两个阶段是面向用户的应用要求,面向具体的问题;中间两个阶段是面向数据库管理系统;最后两个阶段是面向具体的实现方法。前四个阶段可统称为“分析和设计阶段”,后两个阶段称为“实现和运行阶段”。
需求分析
需求分析的重点是调查、收集与分析用户在数据管理中的信息要求、处理要求、安全性与完整性要求。
分析和表达用户的需求的常用方法
- 自顶向下的结构化分析方法(Structured Analysis,简称SA方法)
- 面向对象的分析方法
SA方法从最上层的系统组织机构入手,采用逐层分解的方式分析系统,并用数据流图和数据字典描述系统。
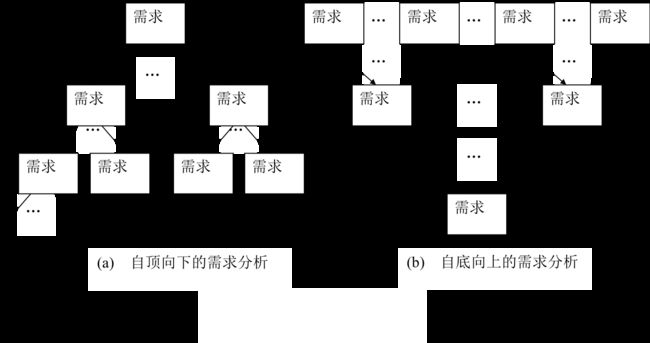
数据流图的画法
自顶向下,逐步求精的方法
- 顶层图:描述系统的范围和边界
- 底层图:描述一个简单的独立功能
- 中间图:描述上一层的某个处理,分解成几个独立的功能
由外向里的原则:在绘制顶层图时先考虑整个系统的输入和输出数据流,然后再考虑系统内部的其他元素。
数据库面向对象技术
模型是现实世界特征的模拟和抽象。数据模型则是现实世界数据特征的抽象。
数据模型应满足三个方面的要求:
- 能比较真实地模拟现实世界
- 容易为人理解
- 便于在计算机上实现
数据模型分类
三个层次的数据模型
概念数据模型
按用户的观点来对数据和信息建模,如E-R模型
逻辑数据模型
从计算机实现的观点来对数据建模
物理数据模型
从计算机的物理存储角度对数据建模
数据操作是对系统动态特性的描述,用于描述施加于数据之上的各种操作,即对数据库中对象的实例允许执行的操作的集合,包括操作及操作规则。一般有检索、更新(插入、删除、修改)操作。数据模型要定义操作含义、操作符号、操作规则,以及实现操作的语言。
数据的约束条件是完整性规则的集合,规定数据库状态及状态变化所应满足的条件,以保证数据的正确、有效、相容。
关系模型的优缺点
优点:
- 坚实的理论基础。(以集合论中的“关系”概念为基础)
- 简单,表的概念直观,用户易理解。
- 简单的结构带来了高效的数据操作效率,并有完善的数据完整性和安全性保证措施。
- 描述的一致性,不仅用关系描述实体本身,也用关系- 描述实体之间的联系。
- 可描述多对多联系。
- 统一的,强大的非过程式操作语言:SQL
- 非过程化的数据请求,数据请求可以不指明路径。
- 数据独立性,用户只需提出“做什么”,无须说明“怎么做”。称为联想访问
缺点:
有限的数据类型
难以处理多媒体数据等复杂结构的数据,不支持数据与操作的绑定
不能清晰表达复杂对象和对象之间的关系
关系型模型必须遵守第一范式,在第一范式约束下,难以简洁有效的表达多值属性、组合属性、聚集等概念
缺少对象身份标识
现实世界中每个数据实体都有唯一的、区别于其它的身份标识。身份标识是抽象概念,应独立于实体的外在表现
关系型数据库用主键来标识数据实体,但存在很多缺点
- 通常选取某个属性做为主键。但属性值常会发生变动,这与数据实体的确定不变性矛盾
- 主键只在一定范围内有效,而数据实体往往是全局的
对象持久化
对象持久化是指将内存中的对象存储到非易失介质上以便下次程序启动的时候读取,并向其它应用程序共享。
对象序列化(Object Serialization)是最简单的对象持久化方法,对象序列化将整个对象数据转换成字节流的形式,然后可以从文件中存取该字节流。缺点是无法对对象进行结构化存取。
阻抗失配(Impedance mismatc):
- 大多数系统使用关系数据库进行数据管理,并使用面向对象的语言开发上层应用
- 进行数据存取的时候必须在对象与二维表间建立映射关系。也就是说对象数据只能扁平化为关系表后才能存储
- 关系模型建模能力有限,面向对象方法无法贯彻到关系数据库中
- 应用程序必须嵌入SQL语言才能操纵数据库
- 将对象映射到表会遇到很大困难,特别是:
- 对象含有复杂结构
- 存在大的非结构化的对象
- 存在类继承
- 映射的结果很可能是:表存取的效率很差;或在表中检索对象很困难
阻抗失配的解决方法:
ORMapping(O-R映射)
用户开发和维护一个中间件层,该层负责将对象数据映射到关系数据库的表中。系统中其它模块可以通过OR映射层以操作对象的方法操作关系表中的数据
OR映射没有改变数据库本质
数据模型改进
通过采用新型数据模型来彻底改造数据库,使之适应对象数据的存储,是一种很自然的想法
面向对象模型和对象关系模型应运而生
- OODB:用面向对象数据模型代替关系数据模型
- ORDB:将关系数据模型扩展为对象关系数据模型
- 都实现了在数据库领域应用面向对象思想方法的目的
对象关系数据库使用与开发
面向对象增加了系统的灵活性。用户可以定义和应用系统有关的数据类型。利用面向对象建模,更加自然地表达客观世界的事物和事物之间的关联
数据库系统自身也可以定义常用的扩展类型,如空间数据类型、XML数据类型等
对象关系数据模型
- 通过引入面向对象及处理复杂数据类型的构造来扩展关系数据模型.
- 允许元组属性具有复杂类型, 包括非原子值(如嵌套关系).
- 保持关系基础, 尤其是对数据的描述性存取, 同时扩展建模能力.
- 与现有关系语言向上兼容.