Hive学习—静态动态分区
一个人胸中没有学问,就像手中没有钱,供学习HSQL的童鞋们参考!
Hive分区(Partitions):用指定分区的列的值在hdfs中创建文件夹,并以此将表数据划分到不同的文件夹,即在表目录下再创建细分文件夹
作用:提高查询性能(查询时自动过滤不在条件的分区)
分类:动态分区和静态分区
静态分区
步骤:
1.建表时即指定分区(可以指定多个,即多分区)
分区字段不能与表中其他字段重复 否则会报错 ↓ ↓ ↓
create table student(id int,name string,age int)
partitioned by(gender string)
row format delimited fields terminated by ',';
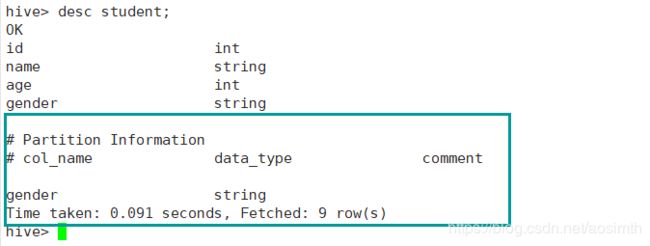
desc查看下表结构,已出现分区信息
2.插入数据
必须插入数据到对应的分区
insert into table student partition(gender='male') values(1,'zs',18);
insert into table student partition(gender='female') values(2,'ff',28);
批量插入
load data local inpath '/opt/aa' overwrite into table student partition(gender='male');
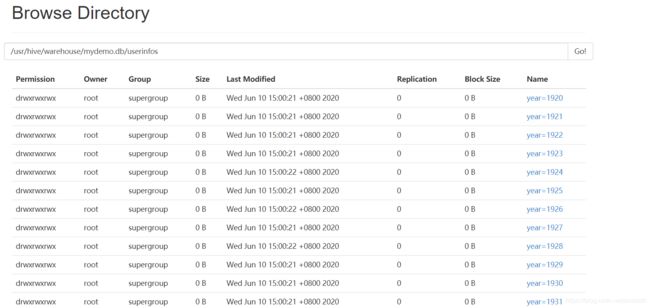
web页面显示

3.增加分区
alter table student add partition(gender='unknow');
4.删除分区
alter table student drop partition(gender='unknow');
由上面代码可以看出,静态分区的数据往往需要程序员手动插入数据到对应的分区,比较麻烦,这时候就可以考虑动态分区
动态分区
系统能根据插入的数据和分区字段自动分区
1.建表
create table userinfos(
useid int,
username string,
age int,
gender string
)
partitioned by(year int,month int)
row format delimited fields terminated by ','
2.开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
3.导入数据
load data local inpath '/opt/bb' overwrite into table userinfos partition(year,month);
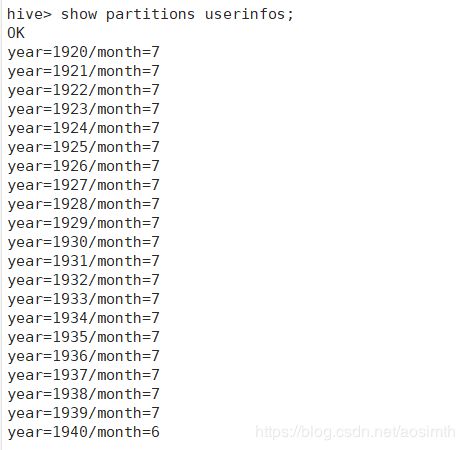
查看分区信息
show partitions userinfos;
web页面显示
分区默认不超过100个,超过会报错,解决方法为增大分区默认数

将开启动态分区的参数调整为如下:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.created.files=10000;