【C#】2020年6月11日 C# 面试题
2020年6月11日 C# 面试题
总结失败与不足,多反思一下。有些是自己写的,肯定有错误,请大家批评指正。
(语法基础题)
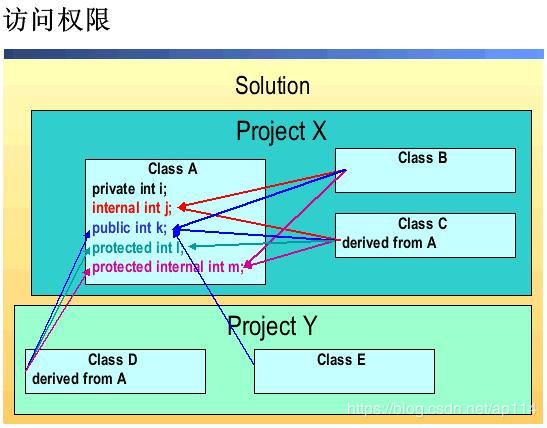
1.C#访问权限修饰符
有以下四类:public,private,protected,internal。默认为internal
类型成员的修饰符,除了上面四个还可以有一种组合形式:protected internal,默认为private
权限从大到小依次展示
| 说明 | |
| public | 任何地方该类都可以被访问到 |
| private | |
| protected | |
| internal | 只有在同一程序集内,该类才可以被访问到 |
2.字符串中使用“+”和StringBuilder的区别
先说String
1.它是引用类型,在堆上分配内存
2.运算时会产生一个新的实例
3.String 对象一旦生成不可改变(Immutable)
4.定义相等运算符(== 和 !=)是为了比较 String 对象的值(而不是引用
再说StringBuilder
String是不可变类,StringBuilder是可变类。
StringBuilder类则不同,每次操作都是对自身对象进行操作,而不是生成新的对象,其所占空间会随着内容的增加而扩充,这样,在做大量的修改操作时,不会因生成大量匿名对象而影响系统性能。
使用“+”是动态分配内存的,使用StringBuilder是静态分配的。
3.List和T[]的区别
当有一组数据需要存放,到底是使用T[]呢,还是选择List
先来看数组。
所有的数组类型都隐式地从System.Array这个抽象类派生,而System.Array又派生自System.Object。也就是说数组是引用类型。通过如下方式创建数组:
int[] arrInt = new int[10];
以上,在托管堆上分配了可以容纳10个未装箱int对象所需要的内存块(这个内存块除了容纳数组元素所占的内存,还包括数组元素对象的类型对象指针、同步块索引等额外成员),然后内存块地址被返回并保存到线程栈上的arrInt变量中。
而List
总结:如果数据的容量是动态变化的,需要操作,比如插入或删除元素,就使用List
转载:https://www.cnblogs.com/darrenji/p/4522353.html
4.引用类型和值类型的区别
1.值类型的数据存储在内存的栈中;引用类型的数据存储在内存的堆中,而内存单元中只存放堆中对象的地址。
2.值类型存取速度快,引用类型存取速度慢。
3. 值类型表示实际数据,引用类型表示指向存储在内存堆中的数据的指针或引用
4.值类型继承自System.ValueType,引用类型继承自System.Object
5.栈的内存分配是自动释放;而堆在.NET中会有GC来释放
6. 值类型的变量直接存放实际的数据,而引用类型的变量存放的则是数据的地址,即对象的引用。
7.值类型变量直接把变量的值保存在堆栈中,引用类型的变量把实际数据的地址保存在堆栈中,而实际数据则保存在堆中。
注意,堆和堆栈是两个不同的概念,在内存中的存储位置也不相同,堆一般用于存储可变长度的数据,如字符串类型;而堆栈则用于存储固定长度的数据,如整型类型的数据int(每个int变量占用四个字节)。由数据存储的位置可以得知,当把一个值变量赋给另一个值变量时,会在堆栈中保存两个完全相同的值;而把一个引用变量赋给另一个引用变量,则会在堆栈中保存对同一个堆位置的两个引用,即在堆栈中保存的是同一个堆的地址。在进行数据操作时,对于值类型,由于每个变量都有自己的值,因此对一个变量的操作不会影响到其它变量;对于引用类型的变量,对一个变量的数据进行操作就是对这个变量在堆中的数据进行操作,如果两个引用类型的变量引用同一个对象,实际含义就是它们在堆栈中保存的堆的地址相同,因此对一个变量的操作就会影响到引用同一个对象的另一个变量。
5.接口和抽象类的区别
接口中所有的方法都不能有实现,并且不能指定方法的修饰符
抽象类中可以有方法的实现,也可以指定方法的访问修饰符
第一个继承接口的类必须实现接口里的所有方法
而抽象类中抽象方法的实现是由第一个非抽象的派生类来实现
C#中的深拷贝与浅拷贝
深拷贝:又称深度克隆,它完全是新对象的产生,不仅复制所有的非静态值类型成员,而且复制所有引用类型成员的实际对象。(即栈上和堆上的成员均进行复制)
浅拷贝:又称影子克隆,只复制原始对象中的所有的非静态的值类型成员和所有引用类型成员的引用,就是说,原始对象和新对象共享所有引用类型成员的对象实例。(即只复制栈上的成员)
(数据结构)
6.堆和栈的区别
堆是一个完全二叉树。
堆是从下往上分配,所以已用的空间在自由空间下面,C#中所有引用类型的对象分配在托管堆上,托管堆在内存上是连续分配的,并且内存对象的释放受垃圾收集机制的管理,效率相对于栈来说要低的多。
栈,先进后出,后进先出,反正不能从中间取数据。
栈是自上向下进行填充,即由高内存地址指向低内存地址,并且内存分配是连续的,C#中所有的值类型和引用类型的引用都分配在栈上,栈根据后进先出的原则,依次对分配和释放内存对象。
栈空间比较小,但是读取速度快
堆空间比较大,但是读取速度慢
(sql)
7.举例索引类型,及其使用方式
为什么加索引
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
数据库分为:唯一索引、主键索引和聚集索引
唯一索引: UNIQUE 例如:create unique index stusno on student(sno);
表明此索引的每一个索引值只对应唯一的数据记录,对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。
主键索引: primary key
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引(也叫聚簇索引):cluster
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
8.内连接和外连接是干嘛的,使用方式
https://blog.csdn.net/plg17/article/details/78758593
这篇写的非常好。
总结:
inner join 内连接:也就是返回两个表的交集(阴影)部分。
外连接:连接结果不仅包含符合连接条件的行同时也包含自身不符合条件的行。包括左外连接、右外连接和全外连接。
MySql中多表查询只提供了内连接,左外连接与右外连接,没有直接的外连接。(https://blog.csdn.net/tayngh/article/details/99692541)
交叉连接:笛卡尔积,开发中应避免出现笛卡尔积,因为会出现指数级的冗余数据。
(asp.net)
9.get和post的区别
Http定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。
GET 是会被浏览器主动缓存的,一般在url是明文形式,问号+参数名+内容“?parameter=xxx”,长度有限制。
POST,无长度限制,请求数据一般附加在HttpContext。
10.asp.net 有几大内置对象
七个
Response、Request、Application、Session、Server、Cookie、Cache
11.webserver、webapi了解程度
1、webservice是基于SOAP协议的,数据格式是XML,webapi遵循的http协议,它的Response可以被而Web API的MediaTypeFormatter转换成Json、XML 或者任何你想转换的格式。
2、webservice它只能部署在IIS上,而webapi可以寄宿在不同的宿主上(寄宿的本质就是利用一个具体的应用程序为Web Api提供一个运行的环境,并解决请求的接收和响应的回复),如Web Host,Self Host方式
3、webservice 也可以通过ajax访问。
4、webapi无状态,相对webservice更轻量级。webapi支持如get,post等http操作,并且对限制带宽的设备,比如智能手机等支持的很好。
这样对比的话webservice貌似并不好用。但是我们为什么要用它呢,理由如下:
1、很好的跨编程语言和跨操作系统
2、可移植性:传统的WebService只是利用了HTTP通道,进行独立的交互,但是这个交互协议可以移植到其他协议下运作
12.常见通讯、传输协议
TCP/IP UDP HTTP FTP
套接字Socket :计算机之间通信、约定的一种方式。
MQTT:用于物联网的,发布订阅式消息协议。
(态度)
13.你对公司了解多少
14.公司到家的路程是多少、能否接受
15.即使入职但效绩不好也会被裁能否接受
16.入职有考察期能否接受
(给你20分钟,你能答上多少 /狗头)
结尾你有没有要问HR的,当时面傻掉了,我说没有,但其实有很多要问的。不要小瞧这些问题,问清了能极大避免以后的误会。
实习时间、转正时间、调薪周期、上下班时间、加班工资、是否996、会不会缴纳5险一金、公司主要是干嘛的,技术框架是什么,主要做哪些方面的应用,入职需要尽快熟悉哪些技术、最迟多久会收到面试成功的消息,需不需要自己带电脑。
还好碰到个超级nice的HR,我没问,他主动耐心的给我说了这些问题,非常感谢。sql最基础的问题直接不会,面的一塌糊涂。
额外转载一条 Winform面试题 https://blog.csdn.net/qq_25371059/article/details/78678657