爬虫提高知识总结
selenium如何使用
功能:请求页面,提取数据,能够执行其中的js
from selenium import webdriver
driver = webdriver.PhantomJS() # 实例化driver
driver.get(url) # 发送请求
driver.quit() # 关闭浏览器selenium定位元素的方法
find_element # 返回元素,没有会报错
find_elements # 返回包含元素的列表,没有就是空列表
find_elements_by_xpath()
find_elements_class_name()
find_elements_by_id()
element.text # 元素获取文本
element.get_attribute("href") # 元素获取属性值selenium如何处理frame
driver.switch_to.frame(id,name,element) # id或name或element都行mongodb的服务端和客户端启动方法
服务端启动
sudo service mongod start
sudo mongod --config /ect/mongod.conf &客户端启动
mongomongodb中数据库的方法
db 查看当前所在的数据库
show dbs 查看所有的数据库
use db_name 使用数据库
db.dropDatabase() 删除数据库
mongodb中集合的方法
show collections 查看所有的集合
db.collection.find() 查看集合中所有的元素
db.collection.drop() 删除集合
mongodb的增删改查的方法
插入
insert() 插入数据,_id相同会报错
save() _id相同会更新
删除
db.collection.remove({条件},{justOne:flase}) # 全部删除满足条件的数据
更新
db.collection.update({条件},{$set:{name:10086}},{multi:true}) # 默认更新一条,multi为true会更新全部
比较运算符
小于:$lt (less than)
小于等于:$lte (less than equal)
大于:$gt (greater than)
大于等于:$gte
不等于:$ne
逻辑运算符
and:{name:"",age:""} 此时name和age表示and的逻辑
or: {$or:[{条件1},{条件2}]} 条件1和条件2之前属于or关系
范围运算符
$in:在范围内 {age:{$in:[19,20,30]}}
$nin:不在范围内
mongodb中的计数,去重,排序
计数
db.col.count({条件})
db.col.find({条件}).count()
去重
db.col.distinct("字段",{条件})
排序
db.col.find().sort({})
投影:输出指定数据内容的字段
db.col.find({条件},{_id:0,name:1}) 返回数据中只会包含name字段,_id不会显示
mongodb的分组
分组
-
按照一个字段分组
db.stu.aggregate({$group:{_id:"$hometown",count:{$sum:1},total_age:{$sum:"$age"},avg_age:{$avg:"$age"}}})
-
按照多个字段分组,_id的值是一个json
db.col.aggregate({$group:{_id:{gender:"$gender",hometown:"$hometown"},count:{$sum:1}}})
参数说明:
_id分组的依据
$age 取age对应的值
$sum:1 把每条数据作为1进行统计,统计的是个数
$sum:"$age" 统计年龄对应的和
$group对应的字典中的键是输出数据的键
不分组,统计整个文档
db.stu.aggregate({$group:{_id:null,count:{$sum:1}}})
mongodb中$match过滤
db.col.aggregate({$match:{age:{$gt:18}}})
mongodb中$project
投影,修改文档的输入输出结构
db.col.aggregate({$project:{_id:0,name:1,new_age:"$age",x:"$a.b"}})
数据透视$push:
把不同行的数据,放到一行来展示
db.stu.aggregate({$group:{_id:"$gender",name:{$push:"$name"},hometown:{$push:"$hometown"}}})
$skip $limit $sort
db.stu.aggregate(
{$group:{_id:"$hometown",count:{$sum:1}}},
{$sort:{count:-1}},
{$skip:1},
{$limit:2}
)mongodb索引
创建索引
db.col.ensureIndex({name:1})
db.col.createIndex()
查看索引
db.col.getIndexes()
删除索引
db.col.dropIndex({name:1})
建立联合索引
db.col.ensureIndex({name:1,age:-1})
建立唯一索引
db.col.ensureIndex({name:1},{unique:true})
mongodb备份和恢复
备份
mongodump -h host -d database -o output_path
恢复
mongorestore -h host -d database --dir 恢复的路径
pymongo的使用
from pymongo import MongoClient
# 实例化client
client = MongoClient(host,port)
# 选择集合
collection = client["db"]["collection"]
# 查询
collection.find() # 返回全部的数据,返回cursor对象,只能获取其中内容一次
collection.find_one() # 返回一条
# 插入
collection.isnert_one()
collection.insert_many()
# 更新
collection.update_one({name:"a"},{"$set":{"name":"noob"}})
collection.update_many()
# 删除
collection.delete_one()
collection.delete_many()scrapy 的数据传递的流程
调度器 request对象--->引擎--->下载器中间件--->下载器
下载器发送请求,获取response--->下载器中间件--->引擎--->爬虫中间件--->爬虫
爬虫--->提取url,组成一个request对象--->爬虫中间件--->引擎--->调取器
爬虫--->提取数据--->爬虫中间件--->引擎--->管道
管道实现数据的处理和保存
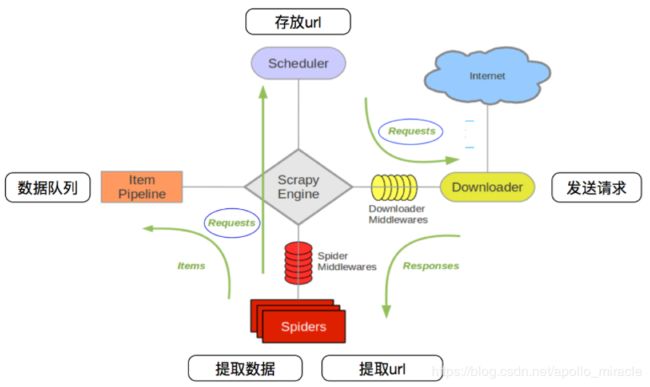
scrapy的项目流程
创建项目:scrapy startproject 项目名
创建爬虫:cd 项目名,scrapy genspider 爬虫名 allowed_domains
完善爬虫:提取数据,提取url地址组成request
完善管道:数据的处理和保存
scrapy如何构造请求
scrapy.Request(url,callback,meta,dont_filter)
url:详情页、下一页的url(完整的url)
callback:url地址响应的处理函数
meta:在不同的函数中传递数据
dont_filter:默认值false,过滤请求,请求过的不会再被请求,为True,表示会被继续请求
yield scrapy.Request(url, callback, meta, dont_filter)
不完整的url使用response.follow()
scrapy的Item如何使用
# 定义
class Item(scrapy.Item):
name = scrapy.Field() # 使用
导入。使用name字典
scrapy中parse函数是做什么的
处理start_urls中的url地址的响应
scrapy shell 如何使用,能干什么
scrapy shell url 能够进入交互式终端
查看scrapy中模块的属性
测试xpath
response对象有哪些常见属性
response.body 能够获取响应bytes字符串
response.url
response.request.url
response.headers
response.request.headers
resposne.text 能够获取响应str字符串
open_spider 和close_spider
open_spider(spider) # 能够在爬虫开启的时候执行一次
close_spdier(spider) # 能够在爬虫关闭的时候执行一次
在和数据库建立连接和断开连接的时候使用上述方法
deepcopy的使用,代码中为什么需要deepcopy
a = deepcopy(b) # 强制传值
代码数据重复
scrapy中的内容是异步执行的,解析函数可能同时在执行,操作的同一个item,
大分类下的所有的图书用的是一个item字典
crwalspider如何创建爬虫
创建命令:Scrapy genspider -t crawl 爬虫名 允许爬取的范围
crwalspdier中rules的编写
rules 元组,元素是Rule
Rule(LinkExtractor(allow="正则"), follow=True,callback="str")
LinkExtractor:传入正则匹配url地址
follow:为True表示提取出来的响应还会经过rules中的规则进行url地址的提取
callback:表示提取出来的响应还会经过callback处理
crwalspider中不同的解析函数间如何传递数据,如果不能应该如何操作?
在前一个Rule的callback中实现手动构造请求
yield scrapy.Request(url, callback, meta)下载器中间件
class TestMid:
def process_request(self,request,spdier):
# 处理请求
request.headers["User-Agent"] = "" # 使用ua
request.meta["proxy"] = "协议+ip+端口" # 使用代理
return None # 请求继续被下载器执行
return Request # request通过引擎交给调度器
return Response # response直接返回给引擎交给爬虫
def process_response(self,request,response,spider):
# 处理响应
return response # 通过引擎交给爬虫
return request # 通过引擎交给调度器模拟登陆之携带cookie
cookie字典传递给请求的cookies参数
yield scrapy.Request(
url,
callback=self.parse,
cookies=cookie_dict,
# headers = {"Cookie":cookies_str} # 不能使用
)模拟登陆之发送post请求
yield scrapy.FormRequest(
"https://github.com/session", # url
formdata=formdata, # 请求体
callback=self.parse_login
)模拟登录之表单提交
#发送请求
yield scrapy.FormRequest.from_response(
response,
formdata=formdata,
callback = self.parse_login
)正则匹配忽略大小写
re.I/re.IGNORECASE
scrapy_redis为什么能够实现去重和请求的持久化以及分布式爬虫
scrapy_redis把指纹和request对象存储在了redis,下一次程序启动起来之后会从之前的redis中读取数据
实现分布式:过个服务器上的爬虫公用一个redis
scray_redis中dmoz给我们展示了一个什么样的爬虫
增量式的爬虫:基于request对象的增量
scrapy_redis中如何实现一个增量式的爬虫
settings中进行配置,指定去重的类,调度器的类,添加上redis_url
#指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#制定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#调度器的内容是否持久化
SCHEDULER_PERSIST = True
#redis的url地址
REDIS_URL = "redis://192.168.150.145:6379"
# 或者使用下面的方式
REDIS_HOST = "192.168.15.69"
REDIS_PORT = 6379scrapy 实现生成指纹的方法
默认使用sha1加密了请求方法,请求体,和请求url地址,得到16进制字符串
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
cache[include_headers] = fp.hexdigest() # 指纹要查看数据是否存在于redis的集合中,如果不存在就插入
added = self.server.sadd(self.key, fp)
# added = 0 表示存在
# added != 0 表示不存在,并且已经插入
return added == 0scrapy_redis和scrapy中request入队的条件
request对象没见过,新的request
dont_filter = True 不过滤的情况下会反复抓取
start_urls 中的url能够被反复抓取
Redisspider中如何实现一个分布式的爬虫
class BookSpider(RedisSpider): # 继承自父类为RedisSpider
name = 'book'
allowed_domains = ['dangdang.com'] # 手动指定allow_domains
# start_urls = ['http://dangdang.com/'] # 没有start_urls
redis_key = "myspider:start_urls" # 增加了一个redis_key的键Redisspider的爬虫和scrapy.spider的区别
Redisspider 分布式爬虫,请求的持久化,去重的持久化
区别
redisspider继承的父类是RedisSpider
redisspider没有start_url,有redis_key
redis_key表示redis中存放start_url地址的键
创建爬虫
scrapy genspider 爬虫名 允许爬取的范围
修改父类名
添加redis_key
启动爬虫
让爬虫就绪 scrapy crawl 爬虫
redis中存入url地址:lpush redis_key url 爬虫会启动
RedisCrawlSpider的爬虫和crwalspdier的区别
RedisCrawlSpider 分布式爬虫,请求的持久化,去重的持久化
区别
RedisCrawlSpider继承的父类是RedisCrawlSpider
RedisCrawlSpider没有start_url,有redis_key
redis_key表示redis中存放start_url地址的键
settings 中多了几行配置
创建爬虫
scrapy genspider -t crwal 爬虫名 允许爬取的范围
修改父类名
添加redis_key
启动爬虫
让爬虫就绪:scrapy crawl 爬虫名
redis中存入url地址:lpush redis_key url 爬虫会启动
crontab使用的方法
分钟 小时 日 月 星期 命令
30 9 8 * * ls # 每个月的8号的9:30执行ls命令在爬虫中使用crontab
1. 爬虫启动命令写入脚本文件
cd dirname $0
scrapy crawl 爬虫名 >> run.log 2>&1
2. 给脚本添加可执行权限
chmod +x run.sh
3. 把脚本文件添加到crontab的配置中
30 6 * * * /home/python/myspider/run.sh