航空公司客户价值分析(上)
本案例来自《Python数据分析与挖掘实战》一书,相关数据集可以在本书的电子资料中找到,下面的一些内容很多都是吸收了书上的内容然后加以改变。简单的介绍一下挖掘的背景与目标,挖掘的背景就是航空公司面临着客户流失、竞争力下降等问题,目标是需要建立一个合理的客户价值评估模型,对客户进行分类区分有价值客户与无价值客户,从而来重新分配资源。
本次项目的全部代码和数据集均在Github上有。
数据集在data目录下,air_data.csv。
分析方法
本次案例的目标是客户价值识别,即通过航空公司客户数据来识别不同价值的客户。识别客户价值应用的最广泛的模型是RFM模型,即通过Recency(最近消费时间间隔),Frequency(消费频率),Monetary(消费金额)来进行客户划分。本案例则是通过在此基础上再加上两个指标来训练模型,即是LRFMC模型,增加的两个指标为:L(客户关系长度)、C(平均折扣系数)。本次是运用聚类的方法对客户群进行分类,采用的聚类算法是K-Means方法。
数据探索
本次的数据探索主要是对数据进行缺失值分析与异常值分析,目的是为了分析出数据的规律以及异常值。查找每列属性观测值中空值个数、最大值、最小值,代码如下:
import pandas as pd
#读取数据
input_file = '../data/air_data.csv'
output_file = '../tmp/explore.xls'
data = pd.read_csv(input_file,encoding='utf-8')
explore = data.describe(percentiles=[],include='all').T
#统计空值数
explore['null'] = len(data) - explore['count']
explore = explore[['null','max','min']]
explore.columns = ['空值数','最大值','最小值']
#导出
explore.to_excel(output_file)
查看票价、折扣、总里程几个特征:
import pandas as pd
data = pd.read_excel("../tmp/explore.xls",index_col='属性')
print(data.loc[['SUM_YR_1','SUM_YR_2','avg_discount','SEG_KM_SUM']])
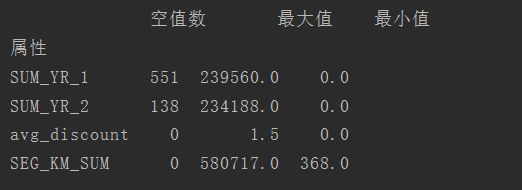
可以看到原始数据中存在票价为空值,票价最小值为0,折扣最小值为0,总飞行公里数大于0的数据。根据乘机的一些相关常识可知,票价为空代表客户可能不存在乘机记录,其他的数据可能是客户乘坐0折机票或积分里程兑换产生的。
数据预处理
本次案例主要采用数据清洗、属性规约和数据变换的预处理方法。
1、数据清洗
通过数据探索分析结果,可以看出数据中存在着一部分的缺失值,还有就是票价为0,折扣不为0,总公里数大于0的记录。但是由于数据集比较大,这部分数据所占比例很小,对建模影响不大,所以对于这部分数据进行丢弃处理,具体代码如下:
import pandas as pd
#读取数据
input_file = '../data/air_data.csv'
output_file = '../tmp/cleaned.xls'
data = pd.read_csv(input_file,encoding='utf-8')
#过滤掉票价为空的数据
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()]
#过滤掉票价为0,折扣不为0,总里程大于0的数据
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['avg_discount'] == 0 ) & (data['SEG_KM_SUM'] == 0)
data = data[index1 | index2 | index3]
#导出
data.to_excel(output_file)
处理后,查看是否还有空值和异常数据:
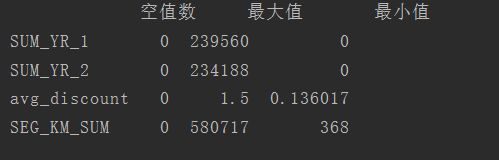
如上图所示票价等特征已经不存在空值了,也不存在票价为0,折扣不为0,总公里大于0的数据了。
2、属性规约与数据表换
由于原数据集中的特征太多,而在分析方法中我们已经谈到,只需要LRFMC,这样即是只需要保留6个特征即L = LOAD_TIME - FFP_DATE,R = LAST_TO_END,F = FLIGHT_COUNT,M = SEG_KM_SUM,C = avg_discount,代码如下。
import pandas as pd
from function import str_to_datetime
input_file = '../tmp/cleaned.xls'
output_file = '../tmp/processed.xls'
#读取数据
data = pd.read_excel(input_file)
# 转换格式
data['LOAD_TIME'] = str_to_datetime(data['LOAD_TIME'])
data['FFP_DATE'] = str_to_datetime(data['FFP_DATE'])
data['L'] = data['LOAD_TIME'] - data['FFP_DATE']
#特征提取,只选L,LAST_TO_END,SEG_KM_SUM,avg_discount
#即入会时间离观测结束的天数,最近一次乘机离..的月数,观测窗口的飞行次数,总飞行里程,折扣
data = data[['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
#重命名属性
data.columns = ['L','R','F','M','C']
#导出
data.to_excel(output_file)
查看一下L、R、F、M、C的取值范围:
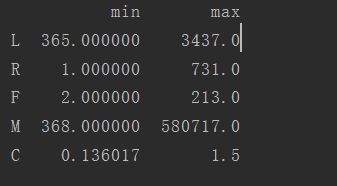
可以看到5个指标的取值范围差异比较大,为了消除这样的影响,需要对数据进行标准化处理,代码如下:
import pandas as pd
input_file = '../tmp/processed.xls'
output_file = '../tmp/std2.xls'
data = pd.read_excel(input_file)
data = data[['L','R','F','M','C']]
data = (data - data.mean(axis=0))/(data.std(axis=0))
data.to_excel(output_file,index=None)
查看一部分处理后的数据集如下:
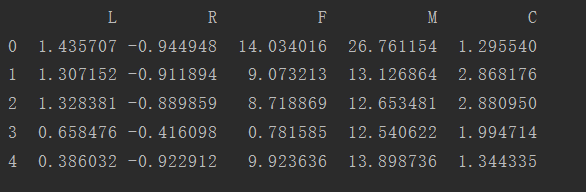
总结
现在把能够用来构建模型的数据集处理好了,所谓万事具备只欠东风了。接下来,需要做的就是进行模型的构建,以及客户群体的分析,得出最后的客户价值分析结果。