【论文解读 AAAI 2020 | Bi-GCN】Rumor Detection on Social Media with Bi-Directional GCN

论文题目:Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks
论文来源:AAAI 2020 清华大学, 腾讯AI
论文链接:https://arxiv.org/abs/2001.06362
代码链接:https://github.com/TianBian95/BiGCN
关键词:谣言检测,社交媒体,GCN
文章目录
- 1 摘要
- 2 引言
- 3 Preliminaries
- 4 Bi-GCN谣言检测模型
- 5 实验
- 6 总结
- 参考文献
1 摘要
本文解决的是社交媒体上的谣言检测问题。
已有一些研究使用深度学习的方法,通过谣言的传播方式检测出谣言。例如RvNN(Recursive Neural Network)。但是这些深度学习方法在谣言检测中只考虑到了传播的深度,却忽视了广泛散布(wide dispersion)的结构。
实际上传播(propagation)和散布(dispersion)是谣言的两个关键特征。本文提出Bi-GCN(Bi-Directional Graph Convolutional Networks)图模型,从谣言自顶向下(top-down)和自底向上(bottom-up)的传播方向上发掘这两个特征。模型中使用到了两个GCN,一个GCN使用了谣言传播的top-down的有向图以学习到谣言的传播模式;另一个GCN使用了相反的有向图以捕获到谣言的散布模式。此外,GCN的每一层中都利用到了源帖子的信息,以增强谣言根源的影响。
作者在一些benchmarks上进行实验,结果显示本文的方法实现了SOTA。
2 引言
(1)传统的谣言检测方法
传统的检测方法主要采用了人工设计的特征,例如用户特征、本文内容和传播模式,来训练有监督的分类器,例如决策树、随机森林、SVM。也有一些研究应用了更多的有效特征,例如用户评论、时序结构特征、帖子的情感属性等。
但是,这些方法主要依赖于特征工程,耗时耗力。而且这些人为设计的特征通常缺乏从谣言传播和散布中抽取出来的高阶(high-level)表示。
(2)最近的研究
近期有的研究使用深度学习方法从传播路径/树或者网络中,挖掘出高阶的表示以进行谣言的识别。通常使用到的模型都是可以捕获到谣言随时间传播的序列特征的模型,例如LSTM, GRU, RvNN。
但是这些模型有一定的局限性,因为时序结构特征只关注到了谣言的传播序列,而忽视了谣言散布的影响。谣言散布的结构也隐含了谣言传播行为的信息。
因此,一些研究尝试通过使用基于CNN的方法,从谣言扩散的结构中获得信息。基于CNN的方法可以得到局部邻域内的相关特征,但是不能处理图或树上的全局结构关联。也就是说,基于CNN的方法忽视了谣言散布的全局结构特征。而且,实际上CNN的设计目的并不是为了从结构数据中学习到高阶表示,但这是GCN的设计目的。
(3)本文提出
GCN已经在社交网络、物理系统、化学制药发现等领域取得了成功。本文使用GCN用于谣言检测。

正如图 1(a)所示,GCN也可称为是无向的GCN(UD-GCN)。GCN只依赖于相关帖子间的关系进行信息的聚合,但丢失了序列顺序信息。尽管UD-GCN可以处理谣言散布的全局结构特征,但是谣言传播的方向也是谣言检测的重要线索,仍需要考虑谣言传播的方向。谣言的两个主要特性是:沿着关系链的深层传播和跨社交社区的宽度散布。好的方法应该同时考虑到这两个特性。
为了处理谣言的传播和散布特性,本文提出Bi-GCN方法,在谣言top-down和bottom-up传播上进行操作。模型由两部分组成,即TD-GCN(Top-Down graph convolutional Networks)和BU-GCN(Bottom-Up graph convolutional Networks),分别如图 1(b)和图 1©所示。TD-GCNH中信息从父节点出发向外散布,正如谣言的传播过程;BU-GCN中信息从子节点向父节点聚合。然后通过全连接层将TD-GCN和BU-GCN的传播和分散表示合并到一起,得到最终的结果。
此外,为了增强谣言根源的影响,作者在GCN每一层都将谣言树根节点的特征和该层的隐层特征拼接起来。作者还在训练时使用到了DropEdge以避免过拟合。
(4)本文主要贡献
1)是第一个将GCN用于社交媒体上谣言检测的工作;
2)提出了Bi-GCN模型,不仅考虑了谣言沿关系链自上而下传播的因果特征,还通过自下而上的聚集得到了社区内谣言散布的结构特征。
3)将源帖子的特征和GCN中每一层的其他帖子的特征相拼接,以广泛使用根特征的信息,并且有助于在谣言检测中实现较好的性能。
在三个真实世界的数据集上使用本文的Bi-GCN方法进行了实验,并超越了几个SOTA方法。
3 Preliminaries
介绍本文方法用到的重要概念和有关定义。
(1)定义
令 C = { c 1 , c 2 , . . . , c m } C={\{c_1, c_2, ..., c_m}\} C={c1,c2,...,cm}表示谣言检测数据集, m m m是事件总数。 c i = { r i , w 1 i , w 2 i , . . . , w n i − 1 i , G i } c_i = {\{r_i, w^i_1, w^i_2, ..., w^i_{n_i-1}, G_i}\} ci={ri,w1i,w2i,...,wni−1i,Gi}, n i n_i ni表示 c i c_i ci中的帖子数, r i r_i ri表示源贴, w j i w^i_j wji表示第 j j j个相关的响应贴, G i G_i Gi表示传播结构。
G i G_i Gi定义为图 < V i , E i >
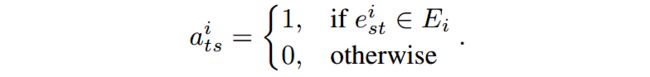
定义 X i = [ x 0 i T , x 1 i T , . . . , x n i − 1 i T ] T \mathbf{X_i} = [\mathbf{x^i_0}^T, \mathbf{x^i_1}^T, ..., \mathbf{x^i_{n_i-1}}^T]^T Xi=[x0iT,x1iT,...,xni−1iT]T为从 c i c_i ci中的帖子中抽取出的特征矩阵,其中 x 0 i T \mathbf{x^i_0}^T x0iT表示 r i r_i ri的特征向量,矩阵的每一行 x j i T \mathbf{x^i_j}^T xjiT表示 w j i w^i_j wji的特征向量。
此外,每个事件 c i c_i ci都有ground truth标签 y i ∈ { F , T } y_i \in {\{F, T}\} yi∈{F,T},表明其是否是谣言。在某些情况下, y i ∈ { N , F , T , U } y_i\in {\{N, F, T, U}\} yi∈{N,F,T,U},分别表示Non-rumor, False Rumor, True Rumor, Unverified Rumor。
给定数据集后,谣言检测的目标是学习到分类器 f f f。基于本文内容、用户信息以及从事件中构建出来的相关帖子组成的传播结构,对事件的标签进行预测。
其中 C , Y C, Y C,Y分别表示事件集合和标签集合。
(2)GCN
将卷积应用到图领域中引起了学者们的关注,其中GCN是最有效的卷积方法之一,GCN的卷积操作可以看成是消息传递结构:
其中 H k ∈ R n × v k \mathbf{H_k}\in \mathbb{R}^{n\times v_k} Hk∈Rn×vk是第 k k k个图卷积层计算出的隐层特征矩阵, M M M是消息传播函数,邻接矩阵 A \mathbf{A} A、隐层特征矩阵 H k − 1 \mathbf{H_{k-1}} Hk−1以及参数 W k − 1 \mathbf{W_{k-1}} Wk−1都是 M M M的参数。
有许多种用于GCN的消息传递函数 M M M,其中定义在一阶近似的ChebNet(1stChebNet)中的消息传播函数如下:
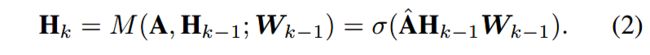
其中 A ^ = D ~ − 1 2 A ~ D ~ − 1 2 \hat{\mathbf{A}} = \tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} A^=D~−21A~D~−21是归一化的邻接矩阵,其中 A ~ = A + I N \tilde{\mathbf{A}} = \mathbf{A} + \mathbf{I}_N A~=A+IN,也就是添加了自环。
(3)DropEdge
DropEdge是发表在ICLR 2020上的文章[1],用于缓解基于GCN的模型的过拟合问题。在每次训练epoch中,将会以一定的比率随机地从原始图中删除掉一些边。这一方法可以增强输入数据的随机性和多样性,就想对图片的随机旋转和翻转一样。
假定图 A \mathbf{A} A中的边总数是 N e N_e Ne,随机删除率是 p p p,则DropEdge之后的邻接矩阵 A ′ \mathbf{A}^{'} A′计算如下,其中 A d r o p \mathbf{A}_{drop} Adrop是从原始边集中随机采样 N e × p N_e\times p Ne×p条边构建出来的。
4 Bi-GCN谣言检测模型
Bi-GCN的核心思想是从谣言传播和谣言散布中学习得到高阶的表示。Bi-GCN模型中使用到了两层的1stChebNet作为基本的GCN组件。如图 2所示,我们将Bi-GCN模型的执行流程分为4步。

我们首先将讨论如何将Bi-GCN模型应用到一个事件上。
(1)构建传播和散布图(Construct Propagation and Dispersion Graphs)
基于回复和转发关系,我们为谣言事件 c i c_i ci构建传播结构 < V . E >
在每次训练epoch中,有 p p p比例的边根据式(3)从原始图中删除以形成 A ′ \mathbf{A}^{'} A′,从而避免过拟合。基于 A ′ \mathbf{A}^{'} A′和 X \mathbf{X} X,我们可以构建Bi-GCN模型。
Bi-GCN模型由TD-GCN和BU-GCN组成。这两个组件使用的邻接矩阵是不同的。对于TD-GCN来说,邻接矩阵为 A T D = A ′ \mathbf{A}^{TD}=\mathbf{A}^{'} ATD=A′;对于BU-GCN来说,邻接矩阵为 A B U = A ′ T \mathbf{A}^{BU}=\mathbf{A}^{'T} ABU=A′T。TD-GCN和BU-GCN使用相同的特征矩阵 X \mathbf{X} X。
(2)计算高阶的节点表示
在DropEdge操作之后,可以使用TD-GCN和BU-GCN分别得到top-down传播特征和bottom-up传播特征。
对式(2)进行更改,得到TD-GCN两层的隐层表示:

其中 H 1 T D ∈ R n × v 1 \mathbf{H}^{TD}_1\in \mathbb{R}^{n\times v_1} H1TD∈Rn×v1和 H 2 T D ∈ R n × v 3 \mathbf{H}^{TD}_2\in \mathbb{R}^{n\times v_3} H2TD∈Rn×v3是TD-GCN两层的隐层特征表示, W 0 T D ∈ R d × v 1 \mathbf{W}^{TD}_0\in \mathbb{R}^{d\times v_1} W0TD∈Rd×v1和 W 1 T D ∈ R v 1 × v 2 \mathbf{W}^{TD}_1\in \mathbb{R}^{v_1\times v_2} W1TD∈Rv1×v2是TD-GCN的卷积核参数矩阵。作者使用ReLU函数作为激活函数。
和式(4)式(5)中的计算类似,可以得到BU-GCN的隐层特征 H 1 B U \mathbf{H}^{BU}_1 H1BU和 H 2 B U \mathbf{H}^{BU}_2 H2BU。
(3)谣言根源特征的增强
谣言事件的根源帖子总是包含足够的信息以产生更广范围的影响。
处了TD-GCN和BU-GCN的隐层特征之外,我们还提出了使用根源特征的增强以提高模型进行谣言检测的性能。
针对TD-GCN的第 k k k层GCL,我们将每个节点的隐层特征向量和第 ( k − 1 ) (k-1) (k−1)层GCL的根节点的隐层特征向量拼接起来,构成一个新的特征矩阵:

其中 H 0 T D = X \mathbf{H}^{TD}_0 = \mathbf{X} H0TD=X。我们用根节点特征增强后的隐层特征 H ~ 1 T D \tilde{\mathbf{H}}^{TD}_1 H~1TD替换式(5)中的 H 1 T D \mathbf{H}^{TD}_1 H1TD。于是得到 H ~ 2 T D \tilde{\mathbf{H}}^{TD}_2 H~2TD:

和式(4)式(5)中的计算类似,可以得到BU-GCN的隐层特征 H ~ 1 B U \tilde{\mathbf{H}}^{BU}_1 H~1BU和 H ~ 2 B U \tilde{\mathbf{H}}^{BU}_2 H~2BU。
(4)用于谣言分类的传播和扩散的表示
分别对TD-GCN和BU-GCN中的节点表示进行聚合,就可以得到传播和扩散的表示。
作者使用了mean-pooling操作以聚合这两组节点表示,形式如下:
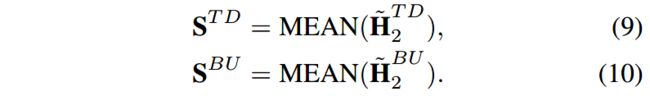
然后,我们将传播和扩散的表示进行拼接来将两者的信息融合:
最后,使用一些全连接层和softmax层,得到事件的预测标签 y ^ \hat{\mathbf{y}} y^。其中 y ^ ∈ R 1 × C \hat{\mathbf{y}}\in \mathbb{R}^{1\times C} y^∈R1×C是所有标签类别对应的概率组成的向量。
使用交叉熵作为训练过程中的损失函数。
5 实验
(1)数据集
- Weibo[2]
- Twitter15[3]
- Twitter16[3]
其中,节点代表用户,边代表转发和回复关系,特征是根据TF-IDF值抽取的top-5000个单词。
Weibo数据集的标签是二元的,分为False Rumor(F)和True Rumor(T)。Twitter15和Twitter16数据集包括4个标签:Non-rumor (N), False Rumor (F), True Rumor (T), 和Unverified Rumor (U)。
表 1展示了三个数据集的统计数据:

(2)对比方法
- DTC:基于多样的人工特征使用决策树分类进行谣言检测的方法;
- SVM-RBF:使用RBF核的基于SVM的模型,使用了基于帖子的所有统计特征设计的人工特征;
- SVM-TS:线性SVM分类器,利用了人工特征以构建时间连续(time-series)的模型;
- SVM-TK:基于谣言传播结构,使用传播树核的SVM分类器;
- RvNN:使用树结构的带有GRU单元的RNN进行谣言的检测,通过传播结构学习到谣言的表示;
- PPC_RNN+CNN:结合了RNN和CNN的谣言检测模型,通过谣言传播路径上的用户特性,学习到了谣言的表示;
- Bi-GCN:本文的基于GCN的谣言检测模型,使用到了双向的传播结构。
(3)实验结果
表 2和表 3展示了不同方法在三个数据集上的对比结果。


1)首先,可以看出基于深度学习的方法普遍比其他的使用人工特征的方法效果好。深度学习方法可以捕获到有效的特征,学习到谣言的高阶表示。
2)其次,本文提出的Bi-GCN在所有指标上都超越了PPC-RNN+CNN方法,这体现了合并谣言扩散结构对于谣言检测的有效性。RNN和CNN方法不能处理图结构的数据,因此忽视了谣言扩散中重要的结构特征。
3)最后,Bi-GCN由于RvNN模型。因为RvNN只用到了所有叶子节点的隐层特征向量,因此受最后的帖子的影响较大。然而,最后的帖子往往缺少信息(例如 评论信息),并且仅仅跟随于先前的帖子。本文提出的Bi-GCN模型使用了根节点特征的增强,给与了根源帖子更多的关注,有助于提高模型的性能。
(4)消融实验
为了分析Bi-GCN每个变形的影响,我们将其和TD-GCN, BU-GCNhe UD-GCN以及不使用根节点特征增强的变形进行了比较。实验结果如图 3所示。

(5)谣言早期检测
目的是在谣言传播的早期将其检测出来,这也是度量谣言检测方法一种指标。为了构建谣言早期检测任务,作者建立了一系列检测deadlines并只使用deadlines前发布的帖子,从而评估本文的方法和baselines方法的准确性。
由于PPC_RNN+CNN不能处理变长的数据,因此没有将其应用到这个实验中。
图 4展示了不同方法的结果。可以看出,本文提出的Bi-GCN方法在源初始广播后的很早期就达到了较高的精度。

6 总结
本文提出了基于GCN的模型Bi-GCN,用于社交媒体上的谣言检测。
GCN使得模型有处理图/树结构数据的能力,并且可以学习到更有助于谣言检测的高阶的表示。此外,作者还在GCN的每层GCL中将根源帖子的特征和该层的隐层特征拼接起来,加强了根源帖子的影响。同时,作者还构建了Bi-GCN的变型以建模传播模式,例如UD-GCN, TD-GCN, BU-GCN。
在三个数据集上进行了实验,证明了基于GCN的方法优于SOTA baselines。
Bi-GCN模型实现了最好的效果,是因为考虑到了自顶向下的谣言传播模式中关系链的因果特征,以及自底向上的不同社区聚合来的谣言散布的结构特征。
本文解决的问题是谣言检测,提出了Bi-GCN模型,模型简单清晰。并且实验结果显示该模型在谣言的早期检测中也起到了很好的效果。
本文的亮点和要点在于:
(1)第一个使用基于GCN的方法进行了谣言检测任务。
(2)和以往方法不同的是,模型考虑到了自顶向下的谣言传播(propagation)结构,和自底向上的来自不同社区的谣言散布(dispersion)结构。具体表现为Bi-GCN由TD-GCN(top-down GCN)和BU-GCN(bottom-up GCN)两个组件所构成。以往的方法大多只使用到了自顶向下的谣言传播结构。有基于CNN的方法考虑到了散布结构,但是由于其不能处理图结构的数据,因此不能捕获全局的结构信息。
(3)模型还使用到了根源帖子特征的增强。具体来说是在GCN每层GCL中,对于每个节点,将根源帖子在上一层的隐层特征表示和节点在该层的隐层特征表示向拼接起来,作为节点在该层的最终隐层特征表示。这种方法增强了谣言根源帖子对于学习到其他帖子节点表示的影响力,可帮助模型学习得到更有助于谣言检测的节点表示。
(4)还使用到了较新的DropEdge方法[1],以缓解基于GCN的模型的过拟合问题。
参考文献
[1] Rong Y, Huang W, Xu T, et al. Dropedge: Towards deep graph convolutional networks on node classification[C]//International Conference on Learning Representations. https://openreview. net/forum. 2020.
[2] Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B. J.; Wong, K.-F.; and Cha, M. 2016. Detecting rumors from microblogs with recurrent neural networks. In Ijcai, 3818–3824.
[3] Ma, J.; Gao, W.; and Wong, K.-F. 2017. Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 708–717.