LwIP协议栈的学习与应用
LwIP协议栈的学习与应用
lwip官网API
前言
LWIP(Light Weight Internet Protoco1)是瑞士计算机科学院(Swedish Institute of Computer Science)AdamDunkels等人开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。LWIP的含义是Light Weight(轻型)IP协议。LWIP可以移植到操作系统上,也可以在无操作系统的情况下独立运行。LWIP TCP/IP实现的重点是在保持TCP协议主要功能的基础上减少对RAM的占用。一般它只需要几十KB的RAM和40 KB左右的ROM就可以运行,这使LWIP协议栈适合在小型嵌入式系统中使用。
LwIP的主要特性如下:
(1)支持多网络接口下的IP转发;
(2) 支持ICMP协议;
(3) 包括实验性扩展的的UDP(用户数据报协议);
(4)包括阻塞控制,RTT估算和快速恢复和快速转发的TCP(传输控制协议);
(5)提供专门的内部回调接口(Raw API)用于提高应用程序性能;
(6)可选择的Berkeley接口API(多线程情况下);
(7)在最新的版本中支持ppp;
(8)新版本中增加了的IP fragment的支持;
(9) 支持DHCP协议,动态分配ip地址。
(
已实现的部分有:
1. 标准的TCP/IP协议栈实现,包括TCP、UDP、ICMP、IP、ARP、DHCP;
ICMP(Internet control message protocol):网络维护和调试。
UDP(User datagram protocol)
DHCP(Dynamic host configuration protocol)
ARP(Address resolution protocol)
2.非标准Socket接口,lwip提供了一套Socket API,这套API的标准与正常操作系统下的Socket API的形式不是很一致,我们先前已经在这套API上实现了Web Server,已测试在没有Mobile IP环境下工作正常。
)
下面我们就一个lwip典型的UDP协议工作过程作为对lwip的简单介绍。
第一部分协议栈的移植
第一章 准备工作
本文的硬件环境采用LPC2468作为主控MCU,LPC24xx是NXP半导体公司(由Philips公司创建) 推出的基于ARM7TDMI-S内核的微控制器,它在片上集成了10 Mbps/100 Mbps以太网控制器。PHY芯片采用DM9161AEP。 操作系统方面,我们选用的μC/OS II 2.88。开发环境采用KEIL MDK3.8。
第二章操作系统适配层
为了使lwIP便于移植,与操作系统有关的功能函数调用和数据结构没有在代码中直接使用。而是当需要这样的函数时,操作系统适配层将加以使用。操作系统适配层向诸如定时器、处理同步、消息传送机制等的操作系统服务提供一套统一的接口。原则上,移植lwIP到其他操作系统时,仅仅需要实现适合该操作系统的操作系统模拟层。
操作系统适配层提供了由TCP使用的定时器功能。操作系统适配层提供的定时器是一次性的定时器,当超时发生时,调用一个已注册函数至少要200ms的间隔。
进程同步机制仅提供了信号量。即使在操作系统底层中信号量不可用,也可以通过其他信号原语像条件变量或互锁来模拟。
信息传递的实现使用一种简单机制,用一种称为“邮箱”的抽象方法。邮箱做两种操作:邮寄和提取。邮寄操作不会阻塞进程;邮寄到邮箱的消息由操作系统模拟层排入队列直到另一个进程来提取它们。即使操作系统底层对邮箱机制不支持,也容易用信号量实现。
信号量多用于任务间同步和互斥。 邮箱用于大数据的传送。 队列多用于处理有序的事件。 做比较“粗俗”的比喻,信号量就是中央政府发给官人做一方大员的官印,有很多种官印但是不能一印多发,得到官印者才能掌权鱼肉一方百姓(任务得到信号量才能运行),否则你就只要等官跑官。邮箱,就好给比当差的下达的抄家、拆房、收监等红头文件,拿到啥样的文件就干啥。消息队列,就是给任务发了一连串的邮件,官员(任务)拿到这一大摞文件,可以从底部或者顶部(LIFO or FIFO)一个一个拆开处理。(注:来自www.ouravr.com)
操作系统适配层的移植主要是在sys_arch.c里面,主要有以下几部分:
信号量相关:
sys_sem_t sys_sem_new(u8_t count)
创建一个新的信号量,并给信号量赋予初值 count。
void sys_sem_signal(sys_sem_tsem)
向指定的信号量发送信号。
void sys_sem_free(sys_sem_tsem)
释放指定的信号量
u32_t sys_arch_sem_wait(sys_sem_t sem, u32_t timeout)
邮箱(MailBox)相关:
sys_mbox_t sys_mbox_new(intsize) 函数
建立一个空的邮箱,如果创建成功,则返回邮箱的地址,如果创建失败则返回为空。
void sys_mbox_free(sys_mbox_tmbox)函数
void sys_mbox_post(sys_mbox_t mbox, void*msg) 函数
err_tsys_mbox_trypost(sys_mbox_t mbox, void *msg)函数
u32_t sys_arch_mbox_fetch(sys_mbox_t mbox,void **msg, u32_t timeout)
u32_tsys_arch_mbox_tryfetch(sys_mbox_t mbox, void **msg) 函数
这个函数是1.3后新有的,
第二章 网卡驱动层
网卡的驱动层主要分为2个方面:MAC和PHY的初始化,数据的收发控制。下面先介绍MAC和PHY的初始化:
以太网接口的自适应能力由DM9161AEP的自动协商功能体现出来。自动协商功能提供了一种在网络连接的两端之间交换配置信息的机制,在该机制下,这两端将自动选择最优的配置,DM9161AEP支持4种不同的以太网工作方式(10 Mbps半双工、10 Mbps全双工、100 Mbps半双工和100 Mbps全双工),自动协商功能在芯片配置的基础上自动选择性能最高的工作方式。
为了进行数据高效率的收发,我们设计了接收和发送两个线程进行并发处理。数据接收线程采用信号量机制,一直在等待ISR的数据接收信号。
第三章应用示例
LwIP的应用程序接口
通常情况下TCP/IP协议栈的数据处理流程一般有几种方式:
(1) TCP/IP协议的每一层是一个单独进程。链路层是一个进程,IP层是一个进程,TCP层是一个进程。这样的好处是网络协议的每一层都非常清晰,代码的调试和理解都非常容易。但是最大的坏处数据跨层传递时会引起上下文切换(context switch)。对于接收一个TCP segment要引起3次context switch(从网卡驱动程序到链路层进程,从链路层进程到ip层进程,从ip层进程到TCP进程)。通常对于操作系统来说,任务切换是要浪费时间的。过频的context swich是不可取的。
(2) TCP/IP协议栈在操作系统内核当中。应用程序通过操作系统的系统调用(system call)和协议栈来进行通讯。这样TCP/IP的协议栈就限定于特定的操作系统内核了。如windows就是这种方式。
(3) TCP/IP协议栈都在一个进程当中。这样TCP/IP协议栈就和操作系统内核分开了。而应用层程序既可以是单独的进程也可以驻留在TCP/IP进程中。如果应用程序是单独的进程可以通过操作系统的邮箱,消息队列等和TCP/IP进程进行通讯。
LwIP采用的是第三种的实现方式,更具体的,LwIP提供以下三种应用程序接口:
(1)RAW API。应用程序直接调用TCP/IP协议栈中的回调函数,应用程序和协议栈代码集成在同一个任务中,这样相对于普通的BSD API来说,速度更快,内存消耗更少。LwIP的后两种API的实现也是基于RAW API。RAWAPI的缺点是编程较为复杂;
(2)正式的API。这种实现方式是在系统中单独建立了一个TCP/IP任务,由这个任务调用RAW API来处理网络通信,其它的网络任务都是利用消息机制与这个任务通信来收发数据。这也是本文中使用的方法;
(3)BSD API。这种API非常像BSD标准UNIX中的socket API,和普通的socket API一样是基于open-read-write-close模型的,这种API是对正式的API又一层的封装,效率较低,资源消耗较多,但是使用BSD API的应用程序有较好的移植性。
第四章性能调优
第二部分代码剖析
第一章总揽
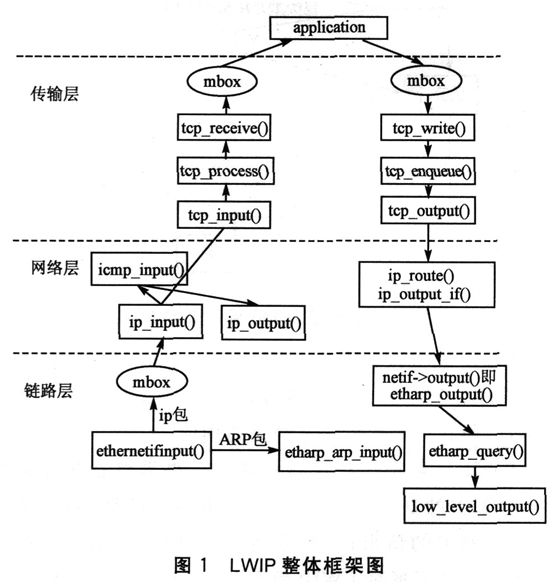
第二章基础组件
内存管理
LwIP内存管理部分(mem.h mem.c)比较灵活,支持多种分配策略,有运行时库自带的内存分配(MEM_LIBC_MALLOC),有内存池分配(MEM_USE_POOLS),有动态内存堆分配,这些分配策略可以通过宏定义来更改。在嵌入式系统里面,C运行时库自带的内存分配一般情况下很少用,更多的是后面二者,下面就这两种分配策略进行简单的分析:
动态内存堆分配
其原理就是在一个事先定义好大小的内存块中进行管理,其内存分配的策略是采用最快合适(First Fit[user1] )方式,只要找到一个比所请求的内存大的空闲块,就从中切割出合适的块,并把剩余的部分返回到动态内存堆中。在分配的内存块前大约有12字节会存放内存分配器管理用的私有数据,该数据区不能被用户程序修改,否则导致致命问题。
内存释放的过程是相反的过程,但分配器会查看该节点前后相邻的内存块是否空闲,如果空闲则合并成一个大的内存空闲块。
采用这种分配策略,其优点就是内存浪费小,比较简单,适合用于小内存的管理,其缺点就是如果频繁的动态分配和释放,可能会造成严重的内存碎片,如果在碎片情况严重的话,可能会导致内存分配不成功。对于动态内存的使用,比较推荐的方法就是分配->释放->分配->释放,这种使用方法能够减少内存碎片。
mem_init( )内存堆的初始化,主要是告知内存堆的起止地址,以及初始化空闲列表,由lwip初始化时自己调用,该接口为内部私有接口,不对用户层开放。
mem_malloc( )申请分配内存。将总共需要的字节数作为参数传递给该函数,返回值是指向最新分配的内存的指针,而如果内存没有分配好,则返回值是NULL,分配的空间大小会收到内存对齐的影响,可能会比申请的略大。返回的内存是“没有“初始化的。这块内存可能包含任何随机的垃圾,你可以马上用有效数据或者至少是用零来初始化这块内存。内存的分配和释放,不能在中断函数里面进行。内存堆是全局变量,因此内存的申请、释放操作做了线程安全保护,如果有多个线程在同时进行内存申请和释放,那么可能会因为信号量的等待而导致申请耗时较长。
mem_calloc( )是对mem_malloc( )函数的简单包装,他有两个参数,分别为元素的数目和每个元素的大小,这两个参数的乘积就是要分配的内存空间的大小,与mem_malloc()不同的是它会把动态分配的内存清零。有经验的程序员更喜欢使用mem_malloc(),因为这样的话新分配内存的内容就不会有什么问题,调用mem_malloc ()肯定会清0,并且可以避免调用memset()。
mem_realloc( ) 函数
Opt.h文件的宏MEM_SIZE是表示初始内存堆的大小。
动态内存池分配
说实话,我也不知道这个说法对不对,反正从源代码里面看,前者叫heap,后者叫pool。欢迎专家指正。
动态内存分配方式只能在内存池与内存堆中二选一。他们对外部的接口都是一样,只不过内部工作原理不太一样。动态内存池分配部分底层实现是在memp.c,memp.h 文件里面实现。
采用内存池进行内存管理可以有效防止内存碎片的产生,而且相比之下内存的分配、释放效率更高,不过,他会浪费部分内存。
需要启用宏MEM_USE_POOLS和MEM_USE_CUSTOM_POOLS,另外还要做类似如下定义:
LWIP_MALLOC_MEMPOOL_START
LWIP_MALLOC_MEMPOOL(20, 256)
LWIP_MALLOC_MEMPOOL(10, 512)
LWIP_MALLOC_MEMPOOL(5, 1512)
LWIP_MALLOC_MEMPOOL_END
上面的意思就是分配20个256字节长度的内存块,10个512字节的内存块,5个1512字节的内存块。内存池管理会根据以上的宏自动在内存中静态定义一个大片内存用于内存池。在内存分配申请的时候,自动根据所请求的大小,选择最适合他长度的池里面去申请,如果启用宏MEM_USE_POOLS_TRY_BIGGER_POOL,那么,如果上述的最适合长度的池中没有空间可以用了,分配器将从更大长度的池中去申请,不过这样会浪费更多的内存。
此外,LwIP为内部的一些结构设计了专用的内存池,比如netconn,协议控制块,数据包等,这些都是在memp.c/memp.h里用内存池进行管理的。
这个模块里面LwIP把C语言的宏用到了极致,它大量采用了C语言的宏特性,设计上面也非常的精妙,看上去也很优雅,不过对于初学者来说猛的看上去很头大,下面就且听我给你介绍,我们先看几个静态变量数组:
memp_memory[]
这是内存池容器,他的大小由编译期决定,他是各个组件的结构用量的累加。
我们来看代码:

这是内存池的具体定义,通过147行,我们可以看出内存池的大小由各个组件的 num*size的累加。如下图所示,每个组件的num 就是下列阴影区的宏定义(在memp_std.h文件)

size的大小就是各个结构的大小,如下图阴影区所示。

整个内存池的大小又可以根据组件的需要而调整,比如,如果你不需要UDP,那么只要把LWIP_UDP定义为0。用宏定义来实现用起来方便,改起来容易,就是看起来头大。
memp_num
这个静态数组用于保存各个组件的成员数目,与memp_memory类似也是用宏实现的。
memp_sizes
这个静态数组用于保存各个组件的结构大小,与memp_memory类似也是用宏实现的。
memp_init
内存池的初始化,主要是为每种内存池建立链表memp_tab,其链表是逆序的,此外,如果有统计功能使能的话,也把记录了各种内存池的数目。
memp_malloc
如果相应的memp_tab链表还有空闲的节点,则从中切出一个节点返回,否则返回空。
memp_free
把释放的节点添加到相应的链表memp_tab头上。
pbuf
pbuf是lwIP包的内部表示,被设计为最小化栈的特殊需要。pbufs类似于BSD实现中的mbufs。pbuf结构支持为包内容动态分配内存和让包数据驻留在静态内存中。pbufs能被一个称为pbuf链的链接到一个链表中,以至一个包能跨越多个pbufs。
pbufs有三种类型:PBUF_RAM,PBUF_ROM和PBUF_POOL。图1表示PBUF_RAM类型,包含有存在内存中由pbuf子系统管理的包数据。图2显示了一个pbuf链表,第1个是PBUF_RAM类型,第2个是PBUF_ROM类型,意味着它包含有不被pubf子系统管理的内存数据。图3描述了PBUF_POOL,其包含有从固定大小pbuf池中分配来的pbuf。一个pbuf链可以包含多个不同类型的pbuf。
这三种类型有不同的用处。PBUF_POOL类型主要由网络设备驱动使用,因为分配单个pbuf快速且适合中断句柄使用。PBUF_ROM类型由应用程序发送那些在应用程序内存空间中的数据时使用。这些数据不会在pbuf递交给TCP/IP栈后被修改,因此这个类型主要用于当数据在ROM中时。PBUF_ROM中指向数据的头部被存在链表中其前一个PUBF_RAM类型的pbuf中,如图2所示。
PBUF_RAM类型也用于应用程序发送动态产生的数据。这情况下,pbuf系统不仅为应用程序数据分配内存,也为将指向(prepend)数据的头部分配内存。如图1所示。pbuf系统不能预知哪种头部将指向(prepend)那些数据,只假定最坏的情况。头部的大小在编译时确定。
本质上,进来的pbuf是PBUF_POOL类型,而出去的pbuf是PBUF_ROM或PBUF_RAM类型。
从图1,图2可以看出pbuf的内部结构。pbuf结构包含有两个指针,两个长度字段,一个标志字段,和一个参考计数。next字段指向统一链表中的下一个pbuf。有效载荷指针指向该pbuf中数据的起始点。Len字段包含有该pbuf数据内同的长度。tot_len字段是当前pbuf和所有链表接下来中的len字段值的总和。简单说,tot_len字段是len字段及下一个pbuf中tot_len字段值的总和。flags字段表示pbuf类型而ref字段包含一个参考计数。next和payload字段是本地指针,其大小由处理器体系结构决定。两个长度字段是16位无符号整数,而flags和ref字段都是4比特大小。pbuf的总大小决定于使用的处理器体系结构。在32位指针和4字节校正的体系结构上,总大小是16字节,而在16位指针和1自己校正的体系结构上,总大小是9字节。
pbuf模块提供了操作pbuf的函数:
pbuf_alloc()可以分配前面提到的三种类型的pbuf。
pbuf_ref()增加引用计数,
pbuf_free()释放分配的空间,它先减少引用计数,当引用计数为0时就释放pbuf。
pbuf_realloc()收缩空间以使pbuf只占用刚好的空间保存数据。
pbuf_header()调整payload指针和长度字段,以使一个头部指向pbuf中的数据。pbuf_chain()和pbuf_dechain()用于链表化pbuf。
第二章 ARP
ARP协议(AddressResolutionProtocol),或称地址解析协议。ARP协议的基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。他是IPv4中网络层必不可少的协议,不过在IPv6中已不再适用,并被icmp v6所替代。
功能
在局域网中,网络中实际传输的是“帧”(frame),帧里面是有目标主机的MAC地址的。在以太网中,一个主机要和另一个主机进行直接通信,必须要知道目标主机的MAC地址,但这个目标MAC地址是通过地址解析协议获得的。所谓“地址解析”就是主机在发送帧前将目标IP地址转换成目标MAC地址的过程。
原理
在每台安装有TCP/IP协议的电脑或 route 里都有一个ARP缓存表,表里的IP地址与MAC地址是一对应的,如表甲所示。
| 主机名称 |
IP地址 |
MAC地址 |
| A |
192.168.38.10 |
00-AA-00-62-D2-02 |
| B |
192.168.38.11 |
00-BB-00-62-C2-02 |
| C |
192.168.38.12 |
00-CC-00-62-C2-02 |
| D |
192.168.38.13 |
00-DD-00-62-C2-02 |
| E |
192.168.38.14 |
00-EE-00-62-C2-02 |
| ... |
... |
以主机A(192.168.38.10)向主机B(192.168.38.11)发送数据为例。当发送数据时,主机A会在自己的ARP缓存表中寻找是否有目标IP地址。如果找到了,也就知道了目标MAC地址为(00-BB-00-62-C2-02),直接把目标MAC地址写入帧里面发送就可以了;如果在ARP缓存表中没有找到相对应的IP地址,主机A就会在网络上发送一个广播(ARPrequest),目标MAC地址是“FF.FF.FF.FF.FF.FF”,这表示向同一网段内的所有主机发出这样的询问:“192.168.38.11的MAC地址是什么?”网络上其他主机并不响应ARP询问,只有主机B接收到这个帧时,才向主机A做出这样的回应(ARP response):“192.168.38.11的MAC地址是(00-BB-00-62-C2-02)”。这样,主机A就知道了主机B的MAC地址,它就可以向主机B发送信息了。同时它还更新了自己的ARP缓存表,下次再向主机B发送信息时,直接从ARP缓存表里查找就可以了。ARP缓存表采用了老化机制,在一段时间内如果表中的某一行没有使用,就会被删除,这样可以大大减少ARP缓存表的长度,加快查询速度。
ARP协议是一个网络层的协议,实现的功能是网络设备的MAC地址到IP地址的映射。在以太网中每个网络设备都有一个唯一的48位(6字节)MAC地址,数据报都是按照MAC地址发送的,其地址范围是由相关组织按照不同设备制造商统一分配的,这样保证了网络上设备地址不会冲突。但是TCP/IP协议是以32位(4字节)IP地址作为通讯地址的,怎样使MAC地址和IP地址对应上呢,这里就用到了ARP协议。
ARP的工作过程大致是这样的:比如网络中的一台主机想要知道MAC地址为01:02:03:04:05:06的机器的IP地址,于是它就向网上发送一个ARP查询数据报(目标MAC全为FF的广播报文),网络上的所有机器收到这个广播后将查询的MAC与自己的MAC比对,如果不一致,则不回应该报文。若一致则向该主机发出ARP回复数据报(这时就是只针对发送方的单播报文了),告诉主机自己的IP(比如192.9.200.128)。这样主机就会在ARP映射表中记录这一项192.9.200.128-----〉01:02:03:04:05:06。以后,发往这个IP地址的IP/TCP/UDP等数据报就会对应到它的MAC地址。在Windows命令提示符窗口输入arp -a查询ARP表项可以看到 MAC-〉IP的映射。
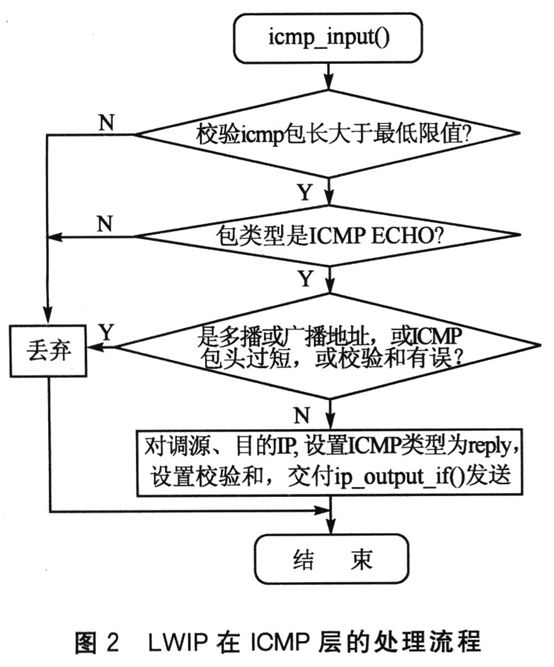
第三章 ICMP
第四章 IP分片
以太网对数据帧长度有一个最大限制,通常是1500字节,这个特性称作MTU,最大传输单元。如果IP层有一个数据包的长度比MTU还大,那么IP层就需要进行分包,有时也称之为分片,把数据包分成若干片,这样每一片都小于MTU。
分片和重新组装的过程对传输层是透明的,其原因是当IP数据报进行分片之后,只有当它到达目的站时,才可进行重新组装,且它是由目的端的IP层来完成的。分片之后的数据报根据需要也可以再次进行分片。
IP分片和完整IP报文差不多拥有相同的IP头,ID域对于每个分片都是一致的,这样才能在重新组装的时候识别出来自同一个IP报文的分片。在IP头里面,16位识别号唯一记录了一个IP包的ID,具有同一个ID的IP分片将会重新组装;而13位片偏移则记录了某IP片相对整个包的位置;而这两个表中间的3位标志则标志着该分片后面是否还有新的分片。这三个标志就组成了IP分片的所有信息(将在后面介绍),接受方就可以利用这些信息对IP数据进行重新组织。
第五章协议栈分析
SOCKET的实现
Lwip协议栈的实现目的,无非是要上层用来实现app的socket编程。好,我们就从socket开始。为了兼容性,lwip的socket应该也是提供标准的socket接口函数,恩,没错,在src\include\lwip\socket.h文件中可以看到下面的宏定义:
#if LWIP_COMPAT_SOCKETS
#define accept(a,b,c) lwip_accept(a,b,c)
#define bind(a,b,c) lwip_bind(a,b,c)
#define shutdown(a,b) lwip_shutdown(a,b)
#define closesocket(s) lwip_close(s)
#define connect(a,b,c) lwip_connect(a,b,c)
#define getsockname(a,b,c) lwip_getsockname(a,b,c)
#define getpeername(a,b,c) lwip_getpeername(a,b,c)
#define setsockopt(a,b,c,d,e)lwip_setsockopt(a,b,c,d,e)
#define getsockopt(a,b,c,d,e)lwip_getsockopt(a,b,c,d,e)
#define listen(a,b) lwip_listen(a,b)
#define recv(a,b,c,d) lwip_recv(a,b,c,d)
#define recvfrom(a,b,c,d,e,f)lwip_recvfrom(a,b,c,d,e,f)
#define send(a,b,c,d) lwip_send(a,b,c,d)
#define sendto(a,b,c,d,e,f) lwip_sendto(a,b,c,d,e,f)
#define socket(a,b,c) lwip_socket(a,b,c)
#define select(a,b,c,d,e) lwip_select(a,b,c,d,e)
#define ioctlsocket(a,b,c) lwip_ioctl(a,b,c)
#if LWIP_POSIX_SOCKETS_IO_NAMES
#define read(a,b,c) lwip_read(a,b,c)
#define write(a,b,c) lwip_write(a,b,c)
#define close(s) lwip_close(s)
先不说实际的实现函数,光看这些定义的宏,就是标准socket所必须有的接口。
接着看这些实际的函数实现。这些函数实现在src\api\socket.c中。先看下接受连接的函数,这个是tcp的
原型:int lwip_accept(int s, struct sockaddr*addr, socklen_t *addrlen)
可以看到这里的socket类型参数 s,实际上是个int型
在这个函数中的第一个函数调用是sock = get_socket(s);
这里的sock变量类型是lwip_socket,定义如下:
/** Contains all internal pointers and statesused for a socket */
struct lwip_socket {
/**sockets currently are built on netconns, each socket has one netconn */
structnetconn *conn;
/**data that was left from the previous read */
structnetbuf *lastdata;
/**offset in the data that was left from the previous read */
u16_tlastoffset;
/**number of times data was received, set by event_callback(),
tested by the receive and select functions */
u16_trcvevent;
/**number of times data was received, set by event_callback(),
tested by select */
u16_tsendevent;
/**socket flags (currently, only used for O_NONBLOCK) */
u16_tflags;
/**last error that occurred on this socket */
interr;
};
好,这个结构先不管它,接着看下get_socket函数的实现【也是在src\api\socket.c文件中】,在这里我们看到这样一条语句sock =&sockets[s];很明显,返回值也是这个sock,它是根据传进来的序列号在sockets数组中找到对应的元素并返回该元素的地址。好了,那么这个sockets数组是在哪里被赋值了这些元素的呢?
进行到这里似乎应该从标准的socket编程的开始,也就是socket函数讲起,那我们就顺便看一下。它对应的实际实现是下面这个函数
Int lwip_socket(int domain, int type, intprotocol)【src\api\socket.c】
这个函数根据不同的协议类型,也就是函数中的type参数,创建了一个netconn结构体的指针,接着就是用这个指针作为参数调用了alloc_socket函数,下面具体看下这个函数的实现
static int alloc_socket(struct netconn*newconn)
{
int i;
/*Protect socket array */
sys_sem_wait(socksem);
/*allocate a new socket identifier */
for (i= 0; i < NUM_SOCKETS; ++i) {
if(!sockets[i].conn) {
sockets[i].conn = newconn;
sockets[i].lastdata = NULL;
sockets[i].lastoffset = 0;
sockets[i].rcvevent = 0;
sockets[i].sendevent = 1; /* TCPsend buf is empty */
sockets[i].flags = 0;
sockets[i].err = 0;
sys_sem_signal(socksem);
return i;
}
}
sys_sem_signal(socksem);
return-1;
}
对了,就是这个时候对全局变量sockets数组的元素赋值的。
既然都来到这里了,那就顺便看下netconn结构的情况吧。它的学名叫netconn descriptor
/** A netconn descriptor */
struct netconn
{
/** type of the netconn (TCP, UDP or RAW) */
enumnetconn_type type;
/** current state of the netconn */
enumnetconn_state state;
/** the lwIP internal protocolcontrol block */
union{
struct ip_pcb *ip;
struct tcp_pcb *tcp;
struct udp_pcb *udp;
struct raw_pcb *raw;
} pcb;
/** the last error this netconn had*/
err_terr;
/** sem that is used to synchroneously execute functions in the corecontext */
sys_sem_t op_completed;
/** mbox where received packets arestored until they are fetched
bythe netconn application thread (can grow quite big) */
sys_mbox_t recvmbox;
/** mbox where new connections are stored until processed
bythe application thread */
sys_mbox_t acceptmbox;
/** only used for socket layer */
intsocket;
#if LWIP_SO_RCVTIMEO
/**timeout to wait for new data to be received
(or connections to arrive for listening netconns) */
intrecv_timeout;
#endif /* LWIP_SO_RCVTIMEO */
#if LWIP_SO_RCVBUF
/**maximum amount of bytes queued in recvmbox */
intrecv_bufsize;
#endif /* LWIP_SO_RCVBUF */
u16_trecv_avail;
/**TCP: when data passed to netconn_write doesn't fit into the send buffer,
this temporarily stores the message. */
structapi_msg_msg *write_msg;
/**TCP: when data passed to netconn_write doesn't fit into the send buffer,
this temporarily stores how much is already sent. */
intwrite_offset;
#if LWIP_TCPIP_CORE_LOCKING
/**TCP: when data passed to netconn_write doesn't fit into the send buffer,
this temporarily stores whether to wake up the original application task
ifdata couldn't be sent in the first try. */
u8_twrite_delayed;
#endif /* LWIP_TCPIP_CORE_LOCKING */
/** Acallback function that is informed about events for this netconn */
netconn_callback callback;
};【src\include\lwip\api.h】
到此,对这个结构都有些什么,做了一个大概的了解。
下面以SOCK_STREAM类型为例,看下netconn的new过程:
在lwip_socket函数中有
case SOCK_DGRAM:
conn = netconn_new_with_callback( (protocol == IPPROTO_UDPLITE) ?
NETCONN_UDPLITE : NETCONN_UDP,event_callback);
#define netconn_new_with_callback(t, c)netconn_new_with_proto_and_callback(t, 0, c)
简略实现如下:
struct netconn*
netconn_new_with_proto_and_callback(enumnetconn_type t, u8_t proto, netconn_callback callback)
{
structnetconn *conn;
structapi_msg msg;
conn =netconn_alloc(t, callback);
if(conn != NULL )
{
msg.function = do_newconn;
msg.msg.msg.n.proto = proto;
msg.msg.conn = conn;
TCPIP_APIMSG(&msg);
}
return conn;
}
主要就看TCPIP_APIMSG了,这个宏有两个定义,一个是LWIP_TCPIP_CORE_LOCKING的,一个非locking的。分别分析这两个不同类型的函数
* Call the lower part of a netconn_* function
* This function has exclusive access to lwIPcore code by locking it
* before the function is called.
err_t tcpip_apimsg_lock(struct api_msg*apimsg)【这个是可以locking的】
{
LOCK_TCPIP_CORE();
apimsg->function(&(apimsg->msg));
UNLOCK_TCPIP_CORE();
returnERR_OK;
}
* Call the lower part of a netconn_* function
* This function is then running in the threadcontext
* of tcpip_thread and has exclusive access tolwIP core code.
err_t tcpip_apimsg(struct api_msg *apimsg)【此为非locking的】
{
structtcpip_msg msg;
if(mbox != SYS_MBOX_NULL) {
msg.type = TCPIP_MSG_API;
msg.msg.apimsg = apimsg;
sys_mbox_post(mbox, &msg);
sys_arch_sem_wait(apimsg->msg.conn->op_completed, 0);
return ERR_OK;
}
returnERR_VAL;
}
其实,功能都是一样的,都是要对apimsg->function函数的调用。只是途径不一样而已。看看它们的功能说明就知道了。这么来说apimsg->function的调用很重要了。从netconn_new_with_proto_and_callback函数的实现,可以知道这个function就是do_newconn
Void do_newconn(struct api_msg_msg *msg)
{
if(msg->conn->pcb.tcp == NULL) {
pcb_new(msg);
}
/*Else? This "new" connection already has a PCB allocated. */
/* Isthis an error condition? Should it be deleted? */
/* Wecurrently just are happy and return. */
TCPIP_APIMSG_ACK(msg);
}
还是看TCP的,在pcb_new函数中有如下代码:
case NETCONN_TCP:
msg->conn->pcb.tcp = tcp_new();
if(msg->conn->pcb.tcp == NULL) {
msg->conn->err = ERR_MEM;
break;
}
setup_tcp(msg->conn);
break;
我们知道在这里建立了这个tcp的连接。至于这个超级牛的函数,以后再做介绍。
嗯,还是回过头来接着看accept函数吧。
Sock获得了,接着就是newconn =netconn_accept(sock->conn);通过mbox取得新的连接。粗略的估计了一下,这个新的连接应该和listen有关系。那就再次打断一下,看看那个listen操作。
lwip_listen --à netconn_listen_with_backlog--à do_listen--à
tcp_arg(msg->conn->pcb.tcp,msg->conn);
tcp_accept(msg->conn->pcb.tcp,accept_function);//注册了一个接受函数
* Accept callback function for TCP netconns.
* Allocates a new netconn and posts that toconn->acceptmbox.
static err_t accept_function(void *arg, structtcp_pcb *newpcb, err_t err)
{
structnetconn *newconn;
structnetconn *conn;
conn =(struct netconn *)arg;
/* Wehave to set the callback here even though
* thenew socket is unknown. conn->socket is marked as -1. */
newconn = netconn_alloc(conn->type, conn->callback);
if(newconn == NULL) {
return ERR_MEM;
}
newconn->pcb.tcp = newpcb;
setup_tcp(newconn);
newconn->err = err;
/*Register event with callback */
API_EVENT(conn, NETCONN_EVT_RCVPLUS, 0);
if (sys_mbox_trypost(conn->acceptmbox, newconn) != ERR_OK)
{
/*When returning != ERR_OK, the connection is aborted in tcp_process(),
so do nothing here! */
newconn->pcb.tcp= NULL;
netconn_free(newconn);
return ERR_MEM;
}
returnERR_OK;
}
对了,accept函数中从mbox中获取的连接就是这里放进去的。
再回到accept中来,取得了新的连接,接下来就是分配sock了,再然后,再然后?再然后就等用户来使用接收、发送数据了。
到此整个APP层,也就是传输层以上对socket的封装讲完了。在最后再总结一些整个路径的调用情况吧

API_MSG结构及其实现
如果要评起到最关键作用的一个结构体,那么struct api_msg当之无愧。先看下它的定义:
/** This struct contains a function to executein another thread context and
astruct api_msg_msg that serves as an argument for this function.
Thisis passed to tcpip_apimsg to execute functions in tcpip_thread context. */
struct api_msg
{
/** function to execute intcpip_thread context */
void(* function)(struct api_msg_msg *msg);
/** arguments for this function */
structapi_msg_msg msg;
};
功能说的很清楚。但是具体怎么个操作法还是不知道,没关系,接着看它的调用。
举一个例子,刚好是上一篇中调用,但是没有看具体实现的
err_t netconn_getaddr(struct netconn *conn,struct ip_addr *addr, u16_t *port, u8_t local)
{
structapi_msg msg;
msg.function = do_getaddr;
msg.msg.conn = conn;
msg.msg.msg.ad.ipaddr = addr;
msg.msg.msg.ad.port = port;
msg.msg.msg.ad.local = local;
TCPIP_APIMSG(&msg);
returnconn->err;
}
说明一下,api_msg结构几乎都是在netconn_xxx函数中被调用,方式千篇一律,除了msg.funcion的赋值不一样外。上面的调用很简单,对该结构体变量赋值,接着就是调用TCPIP_APIMSG,这个函数上面讲过,可过去看下。既然如此,就不得不说mbox及其相关函数了。
static sys_mbox_t mbox = SYS_MBOX_NULL;【tcp.c】
再看sys_mbox_t的定义,在【src\include\lwip\sys.h】中
/* For a totally minimal and standalone system,we provide null
definitions of the sys_ functions. */
typedef u8_t sys_sem_t;
typedef u8_t sys_mbox_t;
typedef u8_t sys_prot_t;
可以看到这里只是简单的定义成了u8类型,注意上面的红色字体的说明,很明显这个是可移植的一部分,需要根据不同的平台,不同的操作系统具体定义。可以借鉴焦海波大侠的关于ucos上对lwip的移植笔记来看。
我们可以看到在api_msg结构的处理过程中,所有的信息都是包含在api_msg_msg结构体中的,api_msg只是将其和function简单的组合了。下面看下这个牛结构的定义:
/** This struct includes everything that isnecessary to execute a function
for anetconn in another thread context (mainly used to process netconns
inthe tcpip_thread context to be thread safe). */
struct api_msg_msg
{
/** The netconn which to process - always needed: it includes thesemaphore
which is used to block the application thread until the functionfinished. */
structnetconn *conn;
/** Depending on the executed function, one of these union members is used*/
union
{
/** used for do_send */
struct netbuf *b;
/** used for do_newconn */
struct {
u8_t proto;
} n;
/** used for do_bind and do_connect */
struct {
struct ip_addr *ipaddr;
u16_t port;
}bc;
/** used for do_getaddr */
struct {
struct ip_addr *ipaddr;
u16_t *port;
u8_t local;
}ad;
/** used for do_write */
struct {
const void *dataptr;
int len;
u8_t apiflags;
} w;
/** used ofr do_recv */
struct {
u16_t len;
} r;
#if LWIP_IGMP
/**used for do_join_leave_group */
struct {
struct ip_addr *multiaddr;
struct ip_addr *interface;
enum netconn_igmp join_or_leave;
}jl;
#endif /* LWIP_IGMP */
#if TCP_LISTEN_BACKLOG
struct {
u8_t backlog;
}lb;
#endif /* TCP_LISTEN_BACKLOG */
} msg;
};
一个很合理的设计,至少笔者是这么认为的。关键在于msg union的设计。
TCP层发送相关
现在我们正式开始进入对TCP的研究,它属于传输层协议,它为应用程序提供了可靠的字节流服务。在LWIP中基本的TCP处理过程被分割为六个功能函数的实现:tcp_input(), tcp_process(), tcp_receive()【与TCP输入有关】, tcp_write(), tcp_enqueue(), tcp_output()【用于TCP输出】。这些是从大的方面来划分的。
现在先从小部tcp.c文件来分析一下:我们知道这里的函数都是被socket那一层的最终调用的。为了利于分析,我选择lwip_send函数来分析,具体不多说,最终调用到了
static err_t do_writemore(struct netconn*conn)这个函数,当然这期间也做了不少工作,最主要的就是把发送数据的指针放到了msg的指定变量中
msg.msg.msg.w.dataptr = dataptr;//指针
msg.msg.msg.w.len = size; //长度
这些又经过转化放到了netconn的write_msg中
最后就是对do_writemore的调用了,下面详细分析这个函数。
这个函数的最直接调用有以下几个:
available = tcp_sndbuf(conn->pcb.tcp);
err = tcp_write(conn->pcb.tcp, dataptr,len, conn->write_msg->msg.w.apiflags);
err = tcp_output_nagle(conn->pcb.tcp);
err = tcp_output(conn->pcb.tcp);
好,先看tcp_sndbuf这个。从其参数,我们应该想像pcb的重要性。
#define tcp_sndbuf(pcb) ((pcb)->snd_buf)//由下面分析得这里直接返回buf大小
那就继续跟踪这个pcb好了。是的,这还得从lwip_socket开始,在创建连接netconn的时候调用了do_newconn,它接着调用了pcb_new,在这个函数中如果是tcp的话有以下代码
msg->conn->pcb.tcp = tcp_new();
哈哈,还记得吧,在前面我讨论到了这里,就没有再讨论了。嗯,现在开始吧。
* Creates a new TCP protocol control block butdoesn't place it on
* any of the TCP PCB lists.
* The pcb is not put on any list until bindingusing tcp_bind().
struct tcp_pcb * tcp_new(void)
{
returntcp_alloc(TCP_PRIO_NORMAL);
}
也许注释的意义更大一些吧,哈哈,至此,我们从注释可以知道,tcp_bind的作用是把tcp的pcb放入list中,至少是某一个list
×××××××××××××××××××××××××××××××××××××××既然都提到了,似乎不说说有点过意不去啊。Lwid_bind函数最终会调用到tcp_bind【当然是tcp为例进行分析】。这个函数也比较有意思,在进入正题之前先来了下面这么个调用
if (port == 0)
{
port = tcp_new_port();
}
意思很明显,就是分配个新的端口号,有意思的就是这个端口号的分配函数tcp_new_port
static u16_t
tcp_new_port(void)
{
struct tcp_pcb *pcb;
#ifndef TCP_LOCAL_PORT_RANGE_START
#define TCP_LOCAL_PORT_RANGE_START 4096
#define TCP_LOCAL_PORT_RANGE_END 0x7fff
#endif
static u16_t port = TCP_LOCAL_PORT_RANGE_START;
again:
if(++port > TCP_LOCAL_PORT_RANGE_END) {
port = TCP_LOCAL_PORT_RANGE_START;
}
for(pcb = tcp_active_pcbs; pcb != NULL; pcb = pcb->next) {
if(pcb->local_port == port) {
goto again;
}
}
for(pcb = tcp_tw_pcbs; pcb != NULL; pcb = pcb->next) {
if(pcb->local_port == port) {
goto again;
}
}
for(pcb = (struct tcp_pcb *)tcp_listen_pcbs.pcbs; pcb != NULL; pcb =pcb->next) {
if (pcb->local_port == port) {
goto again;
}
}
return port;
}分别检查了3个pcb链表,本来我不想把这个函数的实现列在这里的,但是这里告诉了我们一些东西,至少我们知道有3个pcb的链表,分别是tcp_active_pcbs【处于接受发送数据状态的pcbs】、tcp_tw_pcbs【处于时间等待状态的pcbs】、tcp_listen_pcbs【处于监听状态的pcbs】。
似乎tcp_bind函数更有意思,它分别检查了4个pcbs链表,除了上面的三个还有一个tcp_bound_pcbs【处于已经绑定但还没有连接或者监听pcbs】。作用是是否有与目前pcb的ipaddr相同的pcb存在。不过这些都不是最重要的,TCP_REG(&tcp_bound_pcbs, pcb);才是我们的目的,果然如此,直接加入到了tcp_bound_pcbs链表中了。
×××××××××××××××××××××××××××××××××××××××
struct tcp_pcb * tcp_alloc(u8_t prio)//是的,你没看错,这个参数是学名是叫优先级
{
pcb= memp_malloc(MEMP_TCP_PCB);
if (pcb != NULL)
{
memset(pcb, 0, sizeof(struct tcp_pcb));
pcb->prio = TCP_PRIO_NORMAL;
pcb->snd_buf = TCP_SND_BUF;//对的,别的可以先不管,这就是我们要找的东西
pcb->snd_queuelen = 0;
pcb->rcv_wnd = TCP_WND;
pcb->rcv_ann_wnd = TCP_WND;
pcb->tos = 0;
pcb->ttl = TCP_TTL;
/* The send MSS is updated when an MSS optionis received. */
pcb->mss = (TCP_MSS > 536) ? 536 :TCP_MSS;
pcb->rto = 3000 / TCP_SLOW_INTERVAL;
pcb->sa = 0;
pcb->sv= 3000 / TCP_SLOW_INTERVAL;
pcb->rtime = -1;
pcb->cwnd = 1;
iss = tcp_next_iss();
pcb->snd_wl2 = iss;
pcb->snd_nxt = iss;
pcb->snd_max = iss;
pcb->lastack = iss;
pcb->snd_lbb = iss;
pcb->tmr = tcp_ticks;
pcb->polltmr = 0;
#if LWIP_CALLBACK_API
pcb->recv = tcp_recv_null;
#endif /* LWIP_CALLBACK_API */
/* Init KEEPALIVE timer */
pcb->keep_idle = TCP_KEEPIDLE_DEFAULT;
#if LWIP_TCP_KEEPALIVE
pcb->keep_intvl = TCP_KEEPINTVL_DEFAULT;
pcb->keep_cnt = TCP_KEEPCNT_DEFAULT;
#endif /* LWIP_TCP_KEEPALIVE */
pcb->keep_cnt_sent = 0;
}
return pcb;
}就是一个tcp_pcb的结构体初始化过程,使用默认值填充该结构
好了,下面接着走,该轮到tcp_write了吧
* Write data for sending (but does not send it immediately).
* Itwaits in the expectation of more data being sent soon (as
* it cansend them more efficiently by combining them together).
* Toprompt the system to send data now, call tcp_output() after
*calling tcp_write().
【src\core\tcp_out.c】
err_t tcp_write(struct tcp_pcb *pcb, constvoid *data, u16_t len, u8_t apiflags)
{
/*connection is in valid state for data transmission? */
if(pcb->state == ESTABLISHED ||
pcb->state == CLOSE_WAIT ||
pcb->state == SYN_SENT ||
pcb->state == SYN_RCVD)
{
if (len > 0)
{
return tcp_enqueue(pcb, (void *)data, len, 0, apiflags, NULL, 0);
}
return ERR_OK;
}
else
{
return ERR_CONN;
}
}
这个函数确实够简单的了,检查pcb状态,直接入队列。嗯,还是觉得看注释比看函数实现过瘾。
下面的这个tcp_enqueue才是个大头函数,lwip协议栈的设计与实现文档中是这么介绍的:应用层调用tcp_write()函数以实现发送数据,接着tcp_write()函数再将控制权交给tcp_enqueue(),这个函数会在必要时将数据分割为适当大小的TCP段,然后再把这些TCP段放到所属连接的传输队列中【pcb->unsent】。函数的注释是这样写的:
* Enqueue either data or TCP options (but not both) for tranmission
* Calledby tcp_connect(), tcp_listen_input(), tcp_send_ctrl() and tcp_write().
咱们接着上面往下看,tcp_output_nagle这个函数实际上是个宏,通过预判断以决定是否调用tcp_output。也就是说最后的执行是tcp_output来实现的。这个函数或许比tcp_enqueue还要恐怖,从体积上来看。这里也只做一个简单介绍,具体请参阅tcp_out.c文档。该函数的注释是这么说的:Find out what we can send and send it。文档是这么解释的:tcp_output函数会检查现在是不是能够发送数据,也就是判断接收器窗口是否拥有足够大的空间,阻塞窗口是否也足够大,如果条件满足,它先填充未被tcp_enqueue函数填充的tcp报头字段,接着就使用ip_route或者ip_output_if函数发送数据。
TCP层接收相关
既然定了这么个标题,当然是要从socket的recv来讲了。这里主要涉及到lwip_recvfrom这个函数。它的大致过程是,先通过netconn_recv(sock->conn);从netconn的recvmbox中收取数据,在这里有个do_recv的调用,而do_recv又调用了tcp_recved,关于这个函数的注释如下:
* This function should be called by theapplication when it has
* processed the data. The purpose is toadvertise a larger window
* when the data has been processed.
知道了,这里的do_recv只是起到一个知会的作用,可能的话会对接收条件做一些调整。
回到主题,lwip_recvfrom从netconn接收完数据就是要copy the contents of the received buffer into the supplied memory pointermem,这一步是通过netbuf_copy_partial函数来完成的。
接着往下走,我们发现,数据的来源是在netconn的recvmbox,刚才提到过的。好了,那么是在什么地方,什么时候这个recvmbox被填充的呢?
在工程中搜索recvmbox,发现在recv_tcp函数有这样一句:
sys_mbox_trypost(conn->recvmbox, p)
ok,就是它了。看看函数的原型:
* Receive callback function for TCP netconns.
* Posts the packet to conn->recvmbox, butdoesn't delete it on errors.
static err_t recv_tcp(void *arg, structtcp_pcb *pcb, struct pbuf *p, err_t err)
好的,p是个输入参数,并且这是个静态函数,是作为tcp的接收回调用的。
嗯接着看recv_tcp的caller:
* Setup a tcp_pcb with the correct callbackfunction pointers
* and their arguments.
* @param conn the TCP netconn to setup
static void setup_tcp(struct netconn *conn)
{
structtcp_pcb *pcb;
pcb =conn->pcb.tcp;
tcp_arg(pcb, conn);
tcp_recv(pcb, recv_tcp);
tcp_sent(pcb, sent_tcp);
tcp_poll(pcb, poll_tcp, 4);
tcp_err(pcb, err_tcp);
}
哈哈,可谓是一网打尽啊。对于这个函数中的几个调用,我们看一个就好了,别的实现也差不多,就是个赋值的过程
Void tcp_recv(struct tcp_pcb *pcb,
err_t(* recv)(void *arg, struct tcp_pcb *tpcb, struct pbuf *p, err_t err))
{
pcb->recv = recv;
}
setup_tcp上面也有讲过,是在newconn的时候被调用的,创建完pcb,就是调用的这个函数,以配置连接的各个回调函数。
然而到这里似乎走了一个死胡同里了,貌似没有什么地方对pcb->recv有调用的,而唯一有的就是接收TCP事件TCP_EVENT_RECV的宏定义中。同时,其他的几个函数也是类似的情况,例如send_tcp函数。
真是“山穷水尽疑无路,柳暗花明又一村”啊。原来上面的也不只是死胡同。这里就要从tcp的三大接收处理函数说起了。
最底层的(在tcp层)就是tcp_input,它是直接被ip层调用的,该函数的定义注释是这么写的:
* The initial input processing of TCP. Itverifies the TCP header, demultiplexes
* the segment between the PCBs and passes it onto tcp_process(), which implements
* the TCP finite state machine. This functionis called by the IP layer (in ip_input()).
Tcp_input又调用了tcp_process函数做进一步的处理,它的定义注释如下:
* Implements the TCP state machine. Called bytcp_input. In some
* states tcp_receive() is called to receivedata. The tcp_seg
* argument will be freed by the caller(tcp_input()) unless the
* recv_data pointer in the pcb is set.
是的,下面是tcp_receive函数,被tcp_process调用
* Called by tcp_process. Checks if the givensegment is an ACK for outstanding
* data, and if so frees the memory of thebuffered data. Next, is places the
* segment on any of the receive queues(pcb->recved or pcb->ooseq). If the segment
* is buffered, the pbuf is referenced bypbuf_ref so that it will not be freed until
* i it has been removed from the buffer.
然而光有这些调用顺序是不行的,最重要的是下面两个变量【都在tcp_in.c中】
static u8_t recv_flags;
static struct pbuf *recv_data;
在tcp_receive中有以下主要几句
if (inseg.p->tot_len > 0)
{
recv_data = inseg.p;
}
if (cseg->p->tot_len > 0)
{
/*Chain this pbuf onto the pbuf that we will pass to
theapplication. */
if(recv_data)
{
pbuf_cat(recv_data, cseg->p);
}
else
{
recv_data = cseg->p;
}
cseg->p = NULL;
}
下面的这个是tcp_input中的,是在tcp_process处理完之后的
if (recv_data != NULL)
{
if(flags & TCP_PSH)
{
recv_data->flags |= PBUF_FLAG_PUSH;
}
/* Notify application that data has been received. */
TCP_EVENT_RECV(pcb, recv_data, ERR_OK, err);
}
看最后一条语句就好了,很熟悉是吧,对了,就是上面传说中的死胡同,到此也解开了。
IP层实现
这一部分的实现都是在ip.c文件中【src\cor\ipv4】,可以看到在这个文件中主要实现了3个函数,ip_input;ip_route;ip_output以及ip_output_if。下面分别来介绍它们。
这些函数可以分成两大类:接收和发送。下面就先从发送开始,首先要说的就是ip_output函数,这个也是发送过程中最重要的一个,它是被tcp层调用的,详细可参见以上章节。
* Simple interface to ip_output_if. It findsthe outgoing network
* interface and calls upon ip_output_if to dothe actual work.
err_t ip_output(struct pbuf *p, struct ip_addr *src, struct ip_addr *dest,
u8_t ttl, u8_t tos, u8_t proto)
{
structnetif *netif;
if((netif = ip_route(dest)) == NULL) {
return ERR_RTE;
}
returnip_output_if(p, src, dest, ttl, tos, proto, netif);
}
可以看到该函数的实现就像注释所说的一样,直接调用了ip_route和ip_outputif两个函数。根据以往的经验,先看下netif这个结构的实现情况:
* Generic data structure used for all lwIPnetwork interfaces.
* The following fields should be filled in bythe initialization
* function for the device driver: hwaddr_len,hwaddr[], mtu, flags//这几个是要用驱动层填写的
struct netif
{
/**pointer to next in linked list */
structnetif *next;
/** IPaddress configuration in network byte order */
structip_addr ip_addr;
structip_addr netmask;
structip_addr gw;
/**This function is called by the network device driver
* to pass a packet up the TCP/IPstack. */
err_t(* input)(struct pbuf *p, struct netif *inp);
/**This function is called by the IP module when it wants
* to send a packet on theinterface. This function typically
* first resolves the hardwareaddress, then sends the packet. */
err_t(* output)(struct netif *netif, struct pbuf *p, struct ip_addr *ipaddr);
/**This function is called by the ARP module when it wants
* to send a packet on theinterface. This function outputs
* the pbuf as-is on the linkmedium. */
err_t(* linkoutput)(struct netif *netif, struct pbuf *p);
#if LWIP_NETIF_STATUS_CALLBACK
/**This function is called when the netif state is set to up or down
*/
void(* status_callback)(struct netif *netif);
#endif /* LWIP_NETIF_STATUS_CALLBACK */
#if LWIP_NETIF_LINK_CALLBACK
/**This function is called when the netif link is set to up or down
*/
void(* link_callback)(struct netif *netif);
#endif /* LWIP_NETIF_LINK_CALLBACK */
/**This field can be set by the device driver and could point
* to state information for thedevice. */
void*state;
#if LWIP_DHCP
/**the DHCP client state information for this netif */
structdhcp *dhcp;
#endif /* LWIP_DHCP */
#if LWIP_AUTOIP
/**the AutoIP client state information for this netif */
structautoip *autoip;
#endif
#if LWIP_NETIF_HOSTNAME
/* thehostname for this netif, NULL is a valid value */
char* hostname;
#endif /* LWIP_NETIF_HOSTNAME */
/**number of bytes used in hwaddr */
u8_thwaddr_len;
/**link level hardware address of this interface */
u8_thwaddr[NETIF_MAX_HWADDR_LEN];
/**maximum transfer unit (in bytes) */
u16_tmtu;
/**flags (see NETIF_FLAG_ above) */
u8_tflags;
/**descriptive abbreviation */
charname[2];
/**number of this interface */
u8_tnum;
#if LWIP_SNMP
/**link type (from "snmp_ifType" enum from snmp.h) */
u8_tlink_type;
/**(estimate) link speed */
u32_tlink_speed;
/**timestamp at last change made (up/down) */
u32_tts;
/**counters */
u32_tifinoctets;
u32_tifinucastpkts;
u32_tifinnucastpkts;
u32_tifindiscards;
u32_tifoutoctets;
u32_tifoutucastpkts;
u32_tifoutnucastpkts;
u32_tifoutdiscards;
#endif /* LWIP_SNMP */
#if LWIP_IGMP
/* This function could be called to add ordelete a entry in the multicast filter table of the ethernet MAC.*/
err_t(*igmp_mac_filter)( struct netif *netif, struct ip_addr *group, u8_t action);
#endif /* LWIP_IGMP */
#if LWIP_NETIF_HWADDRHINT
u8_t*addr_hint;
#endif /* LWIP_NETIF_HWADDRHINT */
};
该结构体实现在【src\include\lwip\netif.h】,注意到该结构体成员中有3个函数指针变量。好了,这个结构体先做一大体了解。用到的时候再详细讲。
接下来先看下ip_route函数的实现:
* Finds the appropriate network interface for agiven IP address. It
* searches the list of network interfaceslinearly. A match is found
* if the masked IP address of the networkinterface equals the masked
* IP address given to the function.
struct netif * ip_route(struct ip_addr *dest)
{
structnetif *netif;
/*iterate through netifs */
for(netif = netif_list; netif != NULL; netif = netif->next) {
/*network mask matches? */
if(netif_is_up(netif)) {
if(ip_addr_netcmp(dest, &(netif->ip_addr), &(netif->netmask))) {
/* return netif on which to forward IP packet */
return netif;
}
}
}
if((netif_default == NULL) || (!netif_is_up(netif_default)))
{
snmp_inc_ipoutnoroutes();
return NULL;
}
/* nomatching netif found, use default netif */
returnnetif_default;
}
可以说这个函数的实现很简单,且作用也很容易看懂,就像其注释所说的一样。不过在这个函数中我们还是发现了一些什么,对了,就是struct netif *netif_list;【src\core\netif.c】的使用。既然这里都使用了这个网络接口链表,那它是在哪里被初始化的呢?
好了,首先我们发现在netif_add函数中有对netif_list的调用,netif_add是被do_netifapi_netif_add函数调用的,而do_netifapi_netif_add是在netifapi_netif_add中通过netifapi_msg被TCPIP_NETIFAPI调用的。问题似乎很清楚,只要找到nnetifapi_netif_add是被谁调用的就好了,然而,搜遍整个工程也没有发现这个函数的影子,除了一个声明一个实现外。My god,又进入死胡同了?好吧,这里先标识一下,待解【见下面的解释】
我们接着看ip_output_if这个函数,具体函数可参考【src\core\ipv4\ip.c】。它的函数定义注释如下:
* Sends an IP packet on a network interface. This function constructs
* the IPheader and calculates the IP header checksum. If the source
* IPaddress is NULL, the IP address of the outgoing network
*interface is filled in as source address.
* If thedestination IP address is IP_HDRINCL, p is assumed to already
*include an IP header and p->payload points to it instead of the data.
再看最后一句:return netif->output(netif, p, dest);
嗯,看来这个netif还是关键啊,如果估计不错的话,接收的时候也要用到这个结构的。那就看它在什么地方被赋值的吧。又经过一番搜索,看来在目前的代码中是找不到的了。查看lwip协议栈的设计与实现,特别是网络接口层的那一节,终于明白了,原来这些是要有设备驱动来参与的:【一下为引用】
当收到一个信息包时,设备驱动程序调用input指针指向的函数。网络接口通过output指针连接到设备驱动。这个指针指向设备驱动中一个向物理网络发送信息包的函数,当信息包包被发送时由IP层调用,这个字段由设备驱动的初始设置函数填充。
嗯,那就这样吧,到这里我们可以说IP层的发送流程已经走完了。
接下来就是ip层的接收过程了。刚才上面也有提到驱动设备收到包,丢给netif的input函数,这个input函数也是设备驱动层来设置的。无非有两个可能,一个是ip_input,另外一个就是tcpip_input。因为tcpip_input函数的处理是最终调用到了ip_input【在tcpip_thread中】。按照正常情况下应该是ip_input函数的,我们先来看下这个函数。
* This function is called by the network interface device driver when
* an IPpacket is received. The function does the basic checks of the
* IPheader such as packet size being at least larger than the header
* sizeetc. If the packet was not destined for us, the packet is
*forwarded (using ip_forward). The IP checksum is always checked.
原型:err_t ip_input(struct pbuf *p, structnetif *inp)
该函数大致的处理过程是:处理ip包头;找到对应的netif;检查如果是广播或多播包,则丢掉;如果是tcp协议的话就直接调用了tcp_input函数处理数据。
到此,ip层的东西大致就说完了。最后,由于tcp和ip层的东西都说完了,所以此时我们顺便看下,tcpip的整体实现,这个主要是在src\api\tcpip.c文件中实现。我们知道发送过程是由socket直接调用的,所以这个文件中不涉及,说白了,这个文件主要是涉及到整个接收过程。这里实现的函数有tcpip_input,和tcpip_thread以及tcpip_init函数。
Tcpip_init函数很简单就是创建系统线程(sys_thread_new)tcpip_thread。
Tcpip_thread函数的注释如下:
* The main lwIP thread. This thread has exclusive access to lwIP corefunctions
* (unless access to them is not locked).Other threads communicate with this
* thread usingmessage boxes.
它的整个过程就是一直从mbox中取出msg,对各种msg的一个处理过程。
Tcpip_input函数,是在tcpip_thread中被调用的处理设备驱动接收到的信息包,并调用
ip_input来进一步处理。
整个启动过程:
main---> vlwIPInit()
void vlwIPInit( void )
{
/* Initialize lwIP and its interface layer. */
sys_init();
mem_init();
memp_init();
pbuf_init();
netif_init();
ip_init();
sys_set_state(( signed portCHAR * ) "lwIP",lwipTCP_STACK_SIZE);
tcpip_init( NULL, NULL );
sys_set_default_state();
}
从上面我们知道,tcpip_init创建tcpip_thread
在tcpip_thread的开始有如下代码:
(void)arg;
ip_init();
#if LWIP_UDP
udp_init();
#endif
#if LWIP_TCP
tcp_init();
#endif
#if IP_REASSEMBLY
sys_timeout(1000, ip_timer, NULL);
#endif
if (tcpip_init_done != NULL)
{
tcpip_init_done(tcpip_init_done_arg);
}
下面是tcp_init的实现
Void tcp_init(void)
{
/*Clear globals. */
tcp_listen_pcbs.listen_pcbs = NULL;
tcp_active_pcbs = NULL;
tcp_tw_pcbs = NULL;
tcp_tmp_pcb = NULL;
/*initialize timer */
tcp_ticks = 0;
tcp_timer = 0;
}
底层结构(物理层)
们前面讲到说是ip层的发送和接收都是直接调用了底层,也就是设备驱动层的函数实现,在这里暂且称之为物理层吧。下面就接着ip层的讲,不过由于这里的设备驱动各平台的都不一样,为此,我们选择ARM9_STR91X_IAR这个Demo作为实例,该平台的网络设备驱动在\library\source\91x_enet.c文件中。而ethernetif.c文件就是我们需要的,它是连接设备驱动程序与ip层的桥梁。
Ethernetif.c文件中提供的函数主要有以下这么几个:
(1) low_level_init
(2) low_level_input
(3) low_level_output
(4) ethernetif_init
(5) ethernetif_input
(6) ethernetif_output
这里对外的接口只有ethernetif_init函数,它是main函数中通过
netif_add( &EMAC_if, &xIpAddr,&xNetMast, &xGateway, NULL, ethernetif_init, tcpip_input );来被调用的。我们可以清楚的看到,tcpip_input的使用,它就是被用来当有数据接收的时候被调用的以使接收到的数据进入tcpip协议栈。
在netif_add函数中,我们可以看到
netif->input = input;
if (init(netif) != ERR_OK)
{
return NULL;
}
Ok,从这里就进入到ethernetif_init函数了,在这个函数中,我们主要看以下几句:
netif->output = ethernetif_output;
netif->linkoutput = low_level_output;
low_level_init(netif);
etharp_init();
可以看到,netif->output 和netif->linkoutput被赋值了,这个很重要的,等会再说。
好,再接着看low_level_init函数
s_pxNetIf = netif;//对全局变量s_pxNetIf赋初值
ENET_InitClocksGPIO();
ENET_Init();
ENET_Start();//这3句是对网络设备的寄存等的配置
xTaskCreate( ethernetif_input, ( signedportCHAR * ) "ETH_INT", netifINTERFACE_TASK_STACK_SIZE, NULL,netifINTERFACE_TASK_PRIORITY, NULL );
以ethernet_input创建task,这个函数也很有意思,首先可以看到的是一个无限循环,在循环体中有以下调用:
p = low_level_input( s_pxNetIf );
s_pxNetIf->input(p, s_pxNetIf);//tcpip_input
虽然有了这两句,还不是很清楚,可以确定的是后一句是把接收到的数据送入tcpip协议栈处理,为此,我们想到上一句是从硬件读出数据。看下具体的low_level_input函数实现:
len = ENET_HandleRxPkt(s_rxBuff);
这个函数很好理解,主要的是上面的那一句。
/******************************************************************************
* Function Name : ENET_HandleRxPkt
* Description : receive a packet and copy it to memory pointed by ppkt.
* Input : ppkt: pointer on application receive buffer.
* Output : None
* Return : ENET_NOK - If there is no packet
* : ENET_OK - If there is a packet
******************************************************************************/
u32 ENET_HandleRxPkt ( void *ppkt)
{
ENET_DMADSCRBase*pDescr;
u16 size;
static int iNextRx= 0;
if(dmaRxDscrBase[ iNextRx ].dmaPackStatus &
DMA_DSCR_RX_STATUS_VALID_MSK )
{
return0;
}
pDescr= &dmaRxDscrBase[ iNextRx ];
/*Get the size of the packet*/
size= ((pDescr->dmaPackStatus & 0x7ff) - 4);
//MEMCOPY_L2S_BY4((u8*)ppkt,RxBuff, size); /*optimized memcopy function*/
memcpy(ppkt, RxBuff[iNextRx], size); //string.h library*/
/* Give the buffer back to ENET */
pDescr->dmaPackStatus= DMA_DSCR_RX_STATUS_VALID_MSK;
iNextRx++;
if(iNextRx >= ENET_NUM_RX_BUFFERS )
{
iNextRx= 0;
}
/* Return no error */
returnsize;
}
这个函数也很好理解,是从DMA中直接拷贝数据到指定的pBuf。至此,input过程完事了,从代码调用流程上看真是千回百转,一会low_level,一会ethernetif。不过,总体来说是系统通过一个task(ethernetif_input)轮询检查DMA控制器的状态以判断是否有数据接收到。
下面再研究下output过程。Output过程是由应用程序以主动方式触发的,经过前面几篇的介绍,我们知道发送的数据后来被传递给了ip_output_if函数。我们就接着这个函数看,它直接调用了netif->output函数,刚才我们看到在ethernetif_init中有对这个变量【函数指针】赋值,它就是ethernetif_output。它倒是简单,直接return etharp_output();而它有在最后调用了etharp_send_ip,在这个函数的最后调用了return netif->linkoutput(netif, p);好了终于找到根了这里的linkoutput函数也就是low_level_output,果然有如下调用:
memcpy(&TxBuff[l], (u8_t*)q->payload, q->len);
还记得ENET_Init嘛,它的函数实现中有如下两句调用:
ENET_TxDscrInit();
ENET_RxDscrInit();
它们就是初始化DMA发送和接收的地址的,也就是上面所说的TxBuff和RxBuff。
OK,大功告成,自上而下的LWIP大体流程都说到了。如有以后碰到什么需要注意的细节之类,再补上吧。
SOCKET编程示例
首先要注意的一点是sys_thread_new和xTaskCreate的区别。我们知道xTaskCreate是用来创建一个task任务的。类似于windows下的process。
/*
Starts a new thread with priority"prio" that will begin its execution in the
function "thread()". The"arg" argument will be passed as an argument to the
thread() function. The id of the new threadis returned. Both the id and
the priority are system dependent.
*/
sys_thread_tsys_thread_new(void (* thread)(void *arg), void *arg, int prio)
{
xTaskHandleCreatedTask;
intresult;
result = xTaskCreate(thread, ( signedportCHAR * ) s_sys_arch_state.cTaskName, s_sys_arch_state.nStackDepth, arg,prio, &CreatedTask );
// For each task created, store the taskhandle (pid) in the timers array.
// This scheme doesn't allow for threads tobe deleted
timeoutlist[nextthread++].pid = CreatedTask;
if(result == pdPASS)
{
++s_sys_arch_state.nTaskCount;
return CreatedTask;
}
else
{
return NULL;
}
}
很显然,sys_thread_new最终对task的创建也是通过xTaskCreate来实现的。但是请注意不同点,前者会把新创建的task的pid放入到一个timeoutlist的链表中。
起初我也没有主要这个小问题,直到用socket系列函数的select的时候,一直过不去,而是abort中断了,具体原因请看select函数实现,其中sys_arch_timeouts的调用就是获取当前task的timeout,如果没有用sys_thread_new创建的话,这里就没有我用来调用select的当前task,所以就有了以后的abort中断了。
下面给一个socket编程的实现
staticvoid vLWIPSendTask( void *pvParameters )
{
int listenfd;
int remotefd;
int len;
struct sockaddr_inlocal_addr,remote_addr;
fd_set readset;
fd_set writeset;
struct timeval timeout;
timeout.tv_sec = 1;
timeout.tv_usec = 0;
//struct lwip_socket* sock;
listenfd = socket(AF_INET,SOCK_STREAM,0);
local_addr.sin_family = AF_INET;
local_addr.sin_port = htons(80);
local_addr.sin_len = sizeof(local_addr);
local_addr.sin_addr.s_addr = INADDR_ANY;
if (bind(listenfd, (struct sockaddr *)&local_addr, sizeof(local_addr)) < 0)
{
return ;
}
if (listen(listenfd, 1) == -1)
{
return;
}
len = sizeof(remote_addr);
while(1)
{
//这里注意一下,lwip的阻塞不是在listen函数,而是accept
remotefd = accept(listenfd, (struct sockaddr *)&remote_addr,&len);
//close(listenfd);
//listenfd = -1;
//getpeername(remotefd, (struct sockaddr *)&remote_addr, &len);
if(remotefd != -1)
{
int ret;
send(remotefd,"start towork!\r\n",16,0);
for(;;)
{
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_SET(remotefd, &readset);
FD_SET(remotefd, &writeset);
ret = lwip_select(remotefd+1,&readset, &writeset, 0, &timeout);
if(ret > 0)
{
if (FD_ISSET(remotefd,&readset))
{
memset(buf,0,50);
if(recv(remotefd,buf,50,0)<= 0)
{
close(remotefd);
remotefd = -1;
break;
}
else
{
int i = strlen(buf);
send(remotefd,buf,i ,0);
}
}
/*
else if(FD_ISSET(remotefd,&writeset))
{
send(remotefd,"this istime to send!\r\n",25,0);
}
*/
}
else if(ret < 0)
{
close(remotefd);
remotefd = -1;
break;
}
}
}
}
vTaskDelete( NULL );
}
对的,这是作为server端实现的,可以和通用的socket客户端配。经过测试至少可以与windows上的socket程序匹配(接收,发送数据)。
第三部分其他
MEM_SIZE:内存堆的大小。如果应用程序要发送许多需要内存拷贝的数据,这个值应被设置得大些。
MEMP_NUM_PBUF:memp结构的pbufs数目。如果应用程序要发送许多ROM类型(或者其他静态内存)以外的数据,这个值应被设置得大些。
MEMP_NUM_UDP_PCB:UDP协议控制块数目。每个活动的UDP“连接”对应一个。
MEMP_NUM_TCP_PCB:同时活动的TCP连接数
MEMP_NUM_TCP_PCB_LISTEN:监听TCP连接数
MEMP_NUM_TCP_SEG:同时排队TCP分段数
MEMP_NUM_SYS_TIMEOUT:同时活动超时数
MEMP_NUM_NETBUF:结构netbuf数
MEMP_NUM_NETCONN:结构netconn数
MEMP_NUM_APIMSG:结构api_msg数,用于在TCP/IP栈和顺序程序间通信。
MEMP_NUM_TCPIPMSG:结构tcpip_msg数,用于顺序API通信和收包。详见src/api/tcpip.c。
PBUF_POOL_SIZE:pbuf池中缓冲区个数
PBUF_POOL_BUFSIZE:pbuf池中每个pbuf的大小
PBUF_LINK_HLEN:应该分配给一个链路级包头的字节数
TCP_MSS TCP 最大分段长度
TCP_SND_BUF 设成20会造成链路断开,可能CDMA对窗口内数据大小有限制。抑或是队列长度要大于50。
TCP_SND_QUEUELEN 1200
TCP发送器缓冲区空间(pbufs)。这个值必须至少=2*TCP_SND_BUF/TCP_MSS以便正常工作。实测最好保持2倍关系,不要大于2倍。怀疑注释有误,不是至少,是至多。
TCP_WND TCP接收窗口
TCP_MAXRTX 最大重发数据分段数
TCP_SYNMAXRTX 最大重发SYN段数
IP_FORWARD 如果你希望拥有在多个网络接口间进行IP包转发的能力,那么定义IP_FORWARD为1。
IP_OPTIONS 如果为1,IP选项被允许(但不解析)。如果为0,所有带IP选项的包均被抛掉。
DHCP_DOES_ARP_CHECK 置1,如果你需要在给定地址上进行ARP检测(推荐)
参考文献:
嵌入式网络系统设计-基于AtmelARM7系列
[user1]是First Fit还是Next Fit需要再仔细阅读代码确认。