Python 电影评分分析
关注微信号:小程在线
关注CSDN博客:程志伟的博客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('H:/0date/ml-100k/u.user', sep='|', names=u_cols,
encoding='latin-1')
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings = pd.read_csv('H:/0date/ml-100k/u.data', sep='\t', names=r_cols,
encoding='latin-1')
m_cols = ['movie_id', 'title', 'release_date', 'video_release_date', 'imdb_url']
movies = pd.read_csv('H:/0date/ml-100k/u.item', sep='|', names=m_cols, usecols=range(5),
encoding='latin-1')
movie_ratings = pd.merge(movies, ratings)
lens = pd.merge(movie_ratings, users)
lens.head()
Out[6]:
movie_id title release_date ... sex occupation zip_code
0 1 Toy Story (1995) 01-Jan-1995 ... M retired 95076
1 4 Get Shorty (1995) 01-Jan-1995 ... M retired 95076
2 5 Copycat (1995) 01-Jan-1995 ... M retired 95076
3 7 Twelve Monkeys (1995) 01-Jan-1995 ... M retired 95076
4 8 Babe (1995) 01-Jan-1995 ... M retired 95076
[5 rows x 12 columns]
#查看数据集维度
lens.shape
Out[7]: (100000, 12)
#查看数据集的描述
lens[['age','rating']].describe()
Out[8]:
age rating
count 100000.000000 100000.000000
mean 32.969850 3.529860
std 11.562623 1.125674
min 7.000000 1.000000
25% 24.000000 3.000000
50% 30.000000 4.000000
75% 40.000000 4.000000
max 73.000000 5.000000
#男女性别比例分布
lens['sex'].value_counts()
Out[9]:
M 74260
F 25740
Name: sex, dtype: int64
#数据缺失值分布
total_null=lens.isnull().sum()
print(total_null)
movie_id 0
title 0
release_date 9
video_release_date 100000
imdb_url 13
user_id 0
rating 0
unix_timestamp 0
age 0
sex 0
occupation 0
zip_code 0
dtype: int64
#### 评论最多的电影 ####
most_rated = lens.groupby('title').size().sort_values(ascending=False)[:20]
most_rated
Out[12]:
title
Star Wars (1977) 583
Contact (1997) 509
Fargo (1996) 508
Return of the Jedi (1983) 507
Liar Liar (1997) 485
English Patient, The (1996) 481
Scream (1996) 478
Toy Story (1995) 452
Air Force One (1997) 431
Independence Day (ID4) (1996) 429
Raiders of the Lost Ark (1981) 420
Godfather, The (1972) 413
Pulp Fiction (1994) 394
Twelve Monkeys (1995) 392
Silence of the Lambs, The (1991) 390
Jerry Maguire (1996) 384
Chasing Amy (1997) 379
Rock, The (1996) 378
Empire Strikes Back, The (1980) 367
Star Trek: First Contact (1996) 365
dtype: int64
# 有评论记录前20的
lens.title.value_counts()[:20]
Out[13]:
Star Wars (1977) 583
Contact (1997) 509
Fargo (1996) 508
Return of the Jedi (1983) 507
Liar Liar (1997) 485
English Patient, The (1996) 481
Scream (1996) 478
Toy Story (1995) 452
Air Force One (1997) 431
Independence Day (ID4) (1996) 429
Raiders of the Lost Ark (1981) 420
Godfather, The (1972) 413
Pulp Fiction (1994) 394
Twelve Monkeys (1995) 392
Silence of the Lambs, The (1991) 390
Jerry Maguire (1996) 384
Chasing Amy (1997) 379
Rock, The (1996) 378
Empire Strikes Back, The (1980) 367
Star Trek: First Contact (1996) 365
Name: title, dtype: int64
#每个电影的评论数与评分的平均值
movie_stats = lens.groupby('title').agg({'rating': [np.size, np.mean]})
movie_stats.head(10)
Out[14]:
rating
size mean
title
'Til There Was You (1997) 9 2.333333
1-900 (1994) 5 2.600000
101 Dalmatians (1996) 109 2.908257
12 Angry Men (1957) 125 4.344000
187 (1997) 41 3.024390
2 Days in the Valley (1996) 93 3.225806
20,000 Leagues Under the Sea (1954) 72 3.500000
2001: A Space Odyssey (1968) 259 3.969112
3 Ninjas: High Noon At Mega Mountain (1998) 5 1.000000
39 Steps, The (1935) 59 4.050847
#按照评分高低排序
movie_stats.sort_values([('rating', 'mean')], ascending=False).head(10)
Out[15]:
rating
size mean
title
They Made Me a Criminal (1939) 1 5.0
Marlene Dietrich: Shadow and Light (1996) 1 5.0
Saint of Fort Washington, The (1993) 2 5.0
Someone Else's America (1995) 1 5.0
Star Kid (1997) 3 5.0
Great Day in Harlem, A (1994) 1 5.0
Aiqing wansui (1994) 1 5.0
Santa with Muscles (1996) 2 5.0
Prefontaine (1997) 3 5.0
Entertaining Angels: The Dorothy Day Story (1996) 1 5.0
#筛选评论条数大于100,评分由高到低排列
atleast_100 = movie_stats['rating']['size'] >= 100
movie_stats[atleast_100].sort_values([('rating', 'mean')], ascending=False)[:15]
Out[16]:
rating
size mean
title
Close Shave, A (1995) 112 4.491071
Schindler's List (1993) 298 4.466443
Wrong Trousers, The (1993) 118 4.466102
Casablanca (1942) 243 4.456790
Shawshank Redemption, The (1994) 283 4.445230
Rear Window (1954) 209 4.387560
Usual Suspects, The (1995) 267 4.385768
Star Wars (1977) 583 4.358491
12 Angry Men (1957) 125 4.344000
Citizen Kane (1941) 198 4.292929
To Kill a Mockingbird (1962) 219 4.292237
One Flew Over the Cuckoo's Nest (1975) 264 4.291667
Silence of the Lambs, The (1991) 390 4.289744
North by Northwest (1959) 179 4.284916
Godfather, The (1972) 413 4.283293
# 分析评分人数最多的百部电影
most_100 = lens.groupby('movie_id').size().sort_values(ascending=False)[:100]
most_100
Out[17]:
movie_id
50 583
258 509
100 508
181 507
294 485
8 219
95 219
427 219
678 219
322 218
Length: 100, dtype: int64
#评分与年龄的关系
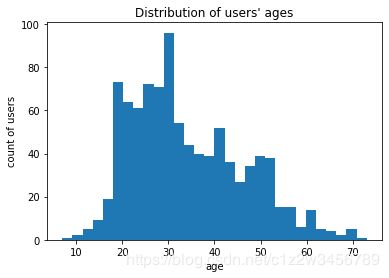
users.age.plot.hist(bins=30)
plt.title("Distribution of users' ages")
plt.ylabel('count of users')
plt.xlabel('age');
#添加趋势线
import seaborn as sns
sns.distplot(users.age)
H:\Anaconda3\lib\site-packages\statsmodels\tools\_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
Out[19]:
#分布点
sns.distplot(users.age, kde=False, rug=True)
Out[20]:
#年龄的大小
users.age.min(),users.age.max()
Out[21]: (7, 73)
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79']
lens['age_group'] = pd.cut(lens.age, np.arange(0, 81, 10), right=False, labels=labels)
lens[['age', 'age_group']].drop_duplicates()[:10]
Out[22]:
age age_group
0 60 60-69
397 21 20-29
459 33 30-39
524 30 30-39
782 23 20-29
995 29 20-29
1229 26 20-29
1664 31 30-39
1942 24 20-29
2270 32 30-39
lens.head()
Out[23]:
movie_id title release_date ... occupation zip_code age_group
0 1 Toy Story (1995) 01-Jan-1995 ... retired 95076 60-69
1 4 Get Shorty (1995) 01-Jan-1995 ... retired 95076 60-69
2 5 Copycat (1995) 01-Jan-1995 ... retired 95076 60-69
3 7 Twelve Monkeys (1995) 01-Jan-1995 ... retired 95076 60-69
4 8 Babe (1995) 01-Jan-1995 ... retired 95076 60-69
[5 rows x 13 columns]
#根据年龄组评分
lens.groupby('age_group').agg({'rating': [np.size, np.mean]})
Out[24]:
rating
size mean
age_group
0-9 43 3.767442
10-19 8181 3.486126
20-29 39535 3.467333
30-39 25696 3.554444
40-49 15021 3.591772
50-59 8704 3.635800
60-69 2623 3.648875
70-79 197 3.649746
lens.set_index('movie_id', inplace=True)
lens.head()
Out[26]:
title release_date ... zip_code age_group
movie_id ...
1 Toy Story (1995) 01-Jan-1995 ... 95076 60-69
4 Get Shorty (1995) 01-Jan-1995 ... 95076 60-69
5 Copycat (1995) 01-Jan-1995 ... 95076 60-69
7 Twelve Monkeys (1995) 01-Jan-1995 ... 95076 60-69
8 Babe (1995) 01-Jan-1995 ... 95076 60-69
[5 rows x 12 columns]
#查看每个电影每个年龄组的评分
by_age = lens.loc[most_100.index].groupby(['title', 'age_group'])
by_age.rating.mean().head(15)
Out[27]:
title age_group
2001: A Space Odyssey (1968) 0-9 5.000000
10-19 4.100000
20-29 3.924731
30-39 3.887500
40-49 4.093023
50-59 4.000000
60-69 4.285714
70-79 NaN
Air Force One (1997) 0-9 NaN
10-19 3.647059
20-29 3.666667
30-39 3.570000
40-49 3.555556
50-59 3.750000
60-69 3.666667
Name: rating, dtype: float64
#列转行计算
by_age.rating.mean().unstack(1).fillna(0)[0:20]
Out[28]:
age_group 0-9 10-19 ... 60-69 70-79
title ...
2001: A Space Odyssey (1968) 5.0 4.100000 ... 4.285714 0.000000
Air Force One (1997) 0.0 3.647059 ... 3.666667 3.666667
Aladdin (1992) 0.0 3.840000 ... 3.500000 0.000000
Alien (1979) 0.0 4.111111 ... 3.500000 4.000000
Aliens (1986) 0.0 4.050000 ... 3.800000 3.000000
Amadeus (1984) 0.0 4.250000 ... 4.750000 5.000000
Apocalypse Now (1979) 0.0 4.400000 ... 4.142857 5.000000
Apollo 13 (1995) 4.0 3.954545 ... 3.750000 4.000000
Babe (1995) 0.0 3.909091 ... 4.600000 3.000000
Back to the Future (1985) 0.0 4.037037 ... 3.857143 4.000000
Birdcage, The (1996) 0.0 3.217391 ... 3.888889 0.000000
Blade Runner (1982) 0.0 3.400000 ... 4.400000 0.000000
Blues Brothers, The (1980) 0.0 4.214286 ... 3.200000 0.000000
Braveheart (1995) 0.0 4.384615 ... 3.714286 4.000000
Broken Arrow (1996) 0.0 3.363636 ... 2.400000 0.000000
Casablanca (1942) 0.0 4.636364 ... 4.285714 5.000000
Chasing Amy (1997) 0.0 4.130435 ... 2.857143 0.000000
Clockwork Orange, A (1971) 0.0 4.600000 ... 3.714286 0.000000
Conspiracy Theory (1997) 0.0 3.565217 ... 2.600000 0.000000
Contact (1997) 5.0 3.693878 ... 3.777778 0.000000
[20 rows x 8 columns]
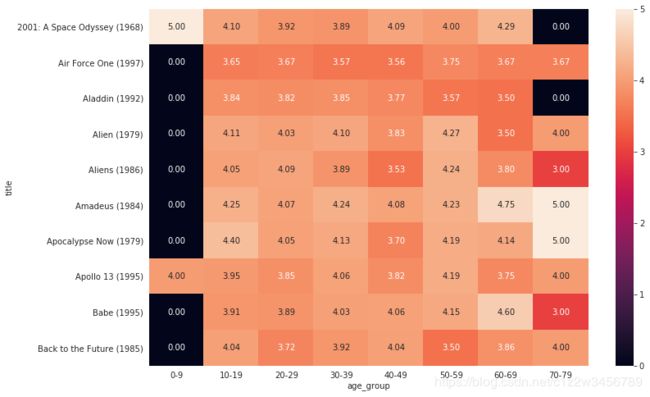
#使用热力图表示
with sns.axes_style('white'):
plt.figure(figsize=(12, 8))
sns.heatmap(by_age.rating.mean().unstack(1).fillna(0)[0:10], annot=True,fmt='4.2f');
#### 评分与性别的关系 ####
lens.reset_index('movie_id', inplace=True)
lens.head()
Out[30]:
movie_id title release_date ... occupation zip_code age_group
0 1 Toy Story (1995) 01-Jan-1995 ... retired 95076 60-69
1 4 Get Shorty (1995) 01-Jan-1995 ... retired 95076 60-69
2 5 Copycat (1995) 01-Jan-1995 ... retired 95076 60-69
3 7 Twelve Monkeys (1995) 01-Jan-1995 ... retired 95076 60-69
4 8 Babe (1995) 01-Jan-1995 ... retired 95076 60-69
[5 rows x 13 columns]
#分组统计男女的评分
pivoted = lens.pivot_table(index=['movie_id', 'title'],
columns=['sex'],
values='rating',
fill_value=0)
pivoted.head()
Out[31]:
sex F M
movie_id title
1 Toy Story (1995) 3.789916 3.909910
2 GoldenEye (1995) 3.368421 3.178571
3 Four Rooms (1995) 2.687500 3.108108
4 Get Shorty (1995) 3.400000 3.591463
5 Copycat (1995) 3.772727 3.140625
pivoted['diff'] = pivoted.M - pivoted.F
pivoted.head()
Out[32]:
sex F M diff
movie_id title
1 Toy Story (1995) 3.789916 3.909910 0.119994
2 GoldenEye (1995) 3.368421 3.178571 -0.189850
3 Four Rooms (1995) 2.687500 3.108108 0.420608
4 Get Shorty (1995) 3.400000 3.591463 0.191463
5 Copycat (1995) 3.772727 3.140625 -0.632102
pivoted.reset_index('movie_id', inplace=True)
#画出男女评分高的电影
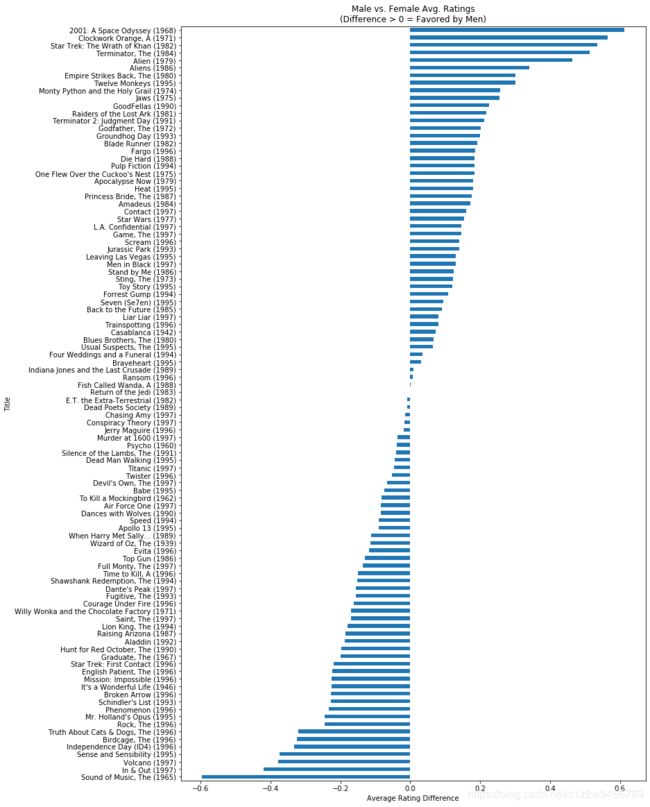
disagreements = pivoted[pivoted.movie_id.isin(most_100.index)]['diff']
disagreements.sort_values().plot(kind='barh', figsize=[12, 20])
plt.title('Male vs. Female Avg. Ratings\n(Difference > 0 = Favored by Men)')
plt.ylabel('Title')
plt.xlabel('Average Rating Difference');