作者|LAKSHAY ARORA
编译|VK
来源|Analytics Vidhya
概述
- PyCaret是一个超级有用的Python库,用于在短时间内执行多个机器学习任务
- 学习如何依赖PyCaret在几行代码中构建复杂的机器学习模型
介绍
我建立的第一个机器学习模型是一个相当麻烦的代码块。我仍然记得构建一个集成模型,它需要许多行代码,它十分需要一个向导来解开这些混乱的代码!
当涉及到构建可解释的机器学习模型时,尤其是在行业中,编写高效的代码是成功的关键。所以我强烈建议使用PyCaret库。

我希望PyCaret在我的刚学习机器学习的日子里出现!这是一个非常灵活和有用的库,我在最近几个月已经相当依赖。我坚信任何有志成为数据科学或分析专业人士的人都会从使用PyCaret中受益匪浅。
我们将看到PyCaret到底是什么,包括如何在你的机器上安装它,然后我们将深入研究如何使用PyCaret来构建可解释的机器学习模型,包括集成模型。
目录
- 什么是PyCaret?为什么要使用它?
- 安装PyCaret
- 熟悉PyCaret
- 使用PyCaret训练我们的机器学习模型
- 使用PyCaret构建集成模型
- 分析模型
- 做出预测
- 保存并加载模型
什么是PyCaret?为什么要使用它?
PyCaret是Python中一个开源的机器学习库,它可以帮助你从数据准备到模型部署。它很容易使用,你可以用一行代码完成几乎所有的数据科学项目任务。

我发现PyCaret非常方便。以下是两个主要原因:
- PyCaret是一个代码库,它使你的工作效率更高。你可以在代码上花更少的时间,做更多的实验
- 它是一个易于使用的机器学习库,将帮助你执行端到端的机器学习实验,无论是输入缺失值、编码分类数据、特征工程、超参数调整,还是构建集成模型
安装PyCaret
这是最直接的。可以直接使用pip安装PyCaret的第一个稳定版本v1.0.0。只需在Jupyter Notebook中运行以下命令即可开始:
!pip3 install pycaret熟悉PyCaret
问题陈述和数据集
在本文中,我们将解决一个分类问题。我们有一个银行数据集,包括客户年龄、经验、收入、教育程度,以及他/她是否有信用卡。该行希望建立一个机器学习模型,帮助他们识别购买个人贷款可能性更高的潜在客户。
数据集有5000行,我们保留了4000行用于训练模型,剩下的1000行用于测试模型。你可以在这里找到本文中使用的完整代码和数据集。
https://github.com/lakshay-ar...
让我们从使用Pandas库读取数据集开始:
# 导入panda以读取CSV文件
import pandas as pd
# 读取数据
data_classification = pd.read_csv('datasets/loan_train_data.csv')
# 查看数据的顶行
data_classification.head()
在PyCaret中启动机器学习项目之前的第一步是设置环境。这只是一个两步的过程:
- 导入模块:根据要解决的问题类型,首先需要导入模块。在PyCaret的第一个版本中,有6个不同的模块可用:回归、分类、聚类、自然语言处理(NLP)、异常检测和关联挖掘规则。在本文中,我们将解决一个分类问题,因此我们将导入分类模块
- 初始化设置:在这个步骤中,PyCaret执行一些基本的预处理任务,比如忽略id和Date列、填充丢失的值、对分类变量进行编码,以及在其余建模步骤中将数据集拆分为train test。当你运行setup函数时,它将首先确认数据类型,然后如果你按enter,它将创建环境。
# 导入分类模块
from pycaret import classification
# 设置环境
classification_setup = classification.setup(data= data_classification, target='Personal Loan')

我们都准备好探索PyCaret了!
使用PyCaret训练我们的机器学习模型
训练模型
用PyCaret训练一个模型非常简单。你只需要使用create_model函数,该函数只接受一个参数(模型缩写为字符串)。
在这里,我们将首先训练一个决策树模型,我们必须通过“dt”,它将返回一个表,其中包含用于分类模型的常用评估指标的k倍交叉验证分数。
以下是用于监督学习的评估指标:
- 分类:Accuracy, AUC, Recall, Precision, F1, Kappa
- 回归:MAE、MSE、RMSE、R2、RMSLE、MAPE
你可以查看PyCaret的文档页以了解更多缩写。
https://pycaret.org/create-mo...
# 建立决策树模型
classification_dt = classification.create_model('dt')
同样,为了训练XGBoost模型,只需要传递字符串“XGBoost”:
# 构建xgboost模型
classification_xgb = classification.create_model('xgboost')
超参数调整
我们可以通过使用tune_model函数来调整机器学习模型的超参数,该函数接受一个参数,模型缩写字符串(与我们在create_model函数中使用的相同)。
PyCaret为我们提供了很多灵活性。例如,我们可以使用tune_model函数中的fold参数定义折叠次数。或者我们可以使用n_iter参数更改迭代次数。增加nòiter参数将明显增加训练时间,提供更好的性能。
让我们训练一个CatBoost模型:
# 构建和调优catboost模型
tune_catboost = classification.tune_model('catboost')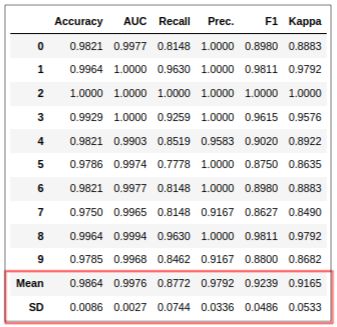
使用PyCaret构建集成模型
机器学习中的集成模型将来自多个模型的决策结合起来,以提高整体性能。
在PyCaret中,我们可以用一行代码创建bagging、boosting、blending和stacking集成模型。
让我们在这里训练一个集成模型。它还将返回一个表,其中包含常用评估指标的k折交叉验证分数:
# boosting
boosting = classification.ensemble_model(classification_dt, method= 'Boosting')
另一个非常著名的合成技术是blending。你只需要传递在blend_models函数列表中创建的模型。
# blending
blender = classification.blend_models(estimator_list=[classification_dt, classification_xgb])就这样!你只需要用PyCaret编写一行代码就可以完成大部分工作。

比较模型
这是PyCaret库的另一个有用功能。如果不想逐个尝试不同的模型,可以使用compare models函数,它将为所有可用模型训练和比较通用的评估度量。
此函数仅在pycaret.classification以及 pycaret.regression模块中。
# 比较不同分类模型的性能
classification.compare_models()
分析模型
现在,在训练模型之后,下一步是分析结果。从商业角度来看,这特别有用,对吧?分析PyCaret中的模型也很简单。只需一行代码,你就可以执行以下操作:
- 对模型结果绘图:分析PyCaret中的模型性能与编写plot_model一样简单。可以绘制决策边界、精确召回曲线、验证曲线、残差图等。此外,对于群集模型,可以绘制肘部图和轮廓图。对于文本数据,可以绘制字云图、bigram图和trigram频率图等。
- 解释结果:通过分析重要特性,解释模型结果有助于调试模型。这是工业级机器学习项目中至关重要的一步。在PyCaret中,我们可以用一行代码通过SHAP值和相关图来解释模型
对模型结果绘图
可以通过提供模型对象作为参数和所需的打印类型来打印模型结果。绘制AUC-ROC曲线和决策边界:
# AUC-ROC 图
classification.plot_model(classification_dt, plot = 'auc')
# 决策边界
classification.plot_model(classification_dt, plot = 'boundary')
绘制训练模型的精确召回曲线和验证曲线:
# Precision Recall 曲线
classification.plot_model(classification_dt, plot = 'pr')
# 验证曲线
classification.plot_model(classification_dt, plot = 'vc')
评估我们的模型
如果你不想单独绘制所有这些可视化效果,那么PyCaret库还有另一个惊人的功能——evaluate_model。在这个函数中,你只需要传递model对象,PyCaret将创建一个交互式窗口,供你以所有可能的方式查看和分析模型:
# 评估模型
classification.evaluate_model(classification_dt)解释我们的模型
在大多数机器学习项目中,解释复杂模型是非常重要的。它通过分析模型认为什么是重要的来帮助调试模型。在PyCaret中,这一步与编写解释模型以获取Shapley值一样简单。
# 解释模型:SHAP
classification.interpret_model(classification_xgb)
让我们尝试绘制相关图:
# 解释模型:相关性
classification.interpret_model(classification_xgb,plot='correlation')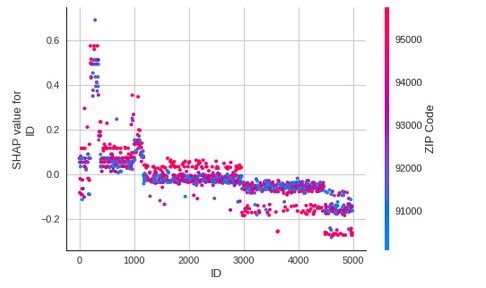
做出预测
最后,我们将对看不见的数据进行预测。为此,我们只需要传递我们将用于预测和数据集的模型。确保它的格式与我们之前设置环境时提供的格式相同。
PyCaret构建一个包含所有步骤的管道,并将未看到的数据传递到管道中,并给出结果。
让我们看看如何预测数据的标签:
# 读取测试数据
test_data_classification = pd.read_csv('datasets/loan_test_data.csv')
# 做出预测
predictions = classification.predict_model(classification_dt, data=test_data_classification)
# 查看预测
predictions
保存并加载模型
现在,一旦构建并测试了模型,我们就可以使用save_model函数将其保存在pickle文件中。传递要保存的模型和文件名,即:
# 保存模型
classification.save_model(classification_dt, 'decision_tree_1')我们可以稍后加载此模型并预测数据上的标签:
# 加载模型
dt_model = classification.load_model(model_name='decision_tree_1')结尾
它真的很容易使用。我个人发现PyCaret对于在时间紧迫的情况下快速生成结果非常有用。
在不同类型的数据集上练习使用它——你会越充分利用它,就越能真正掌握它的实用性!它甚至只需要一行代码就可以在AWS等云服务上支持模型部署。
原文链接:https://www.analyticsvidhya.c...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/