知识图谱前沿技术课程(华东师范大学站)
知识图谱表达了各类实体、概念及其之间的各种语义关系,成为了大数据时代知识表示的主要形态之一。知识图谱是目前人工智能领域的一个重要支撑,已经在诸如智能问答、搜索、推荐等具体领域得到很好的应用。
华东师范大学计算机应用研究所长期以来专注于知识图谱构建、精化和应用等各方面研究,目前已在学术、电商、对话机器人等领域有了较为深入的应用。
为此举办此次知识图谱前沿技术课程,邀请了清华大学、复旦大学、华东师范大学、苏州大学等高校著名学者,及阿里巴巴、微软亚洲研究院等业界领先企业代表,共济一堂,开堂授课,交流研讨。旨在集中展示知识图谱的当前在学术界和工业界的进展,讨论现有主要问题,为下一步知识图谱方向的研究工作做好规划。欢迎广大师生、研究人员参与。
活动时间
10月19日(周四)
9:00 - 17:30
活动地点
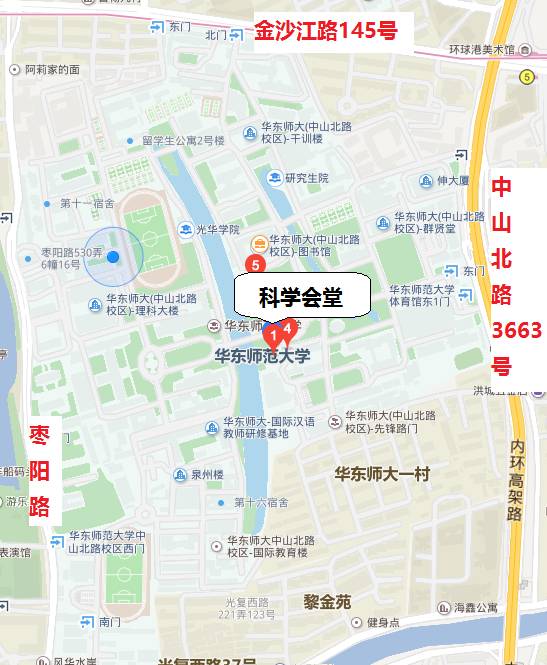
华东师范大学中北校区(中山北路3663号)科学会堂
自驾请从 中山北路3663号或者 金沙江路145号进入华东师范大学中北校区,进入时告知保安参加本次会议,并在其引导下有序停车。或者搭乘地铁3、4号线从5号口出右转,步行或乘共享单车至华师大科学会堂。
报名方式
本课程不收取任何费用,与会人员食宿自理。为更好为大家提供服务,需在线报名,并在与会时签到。请点击「阅读原文」进行报名。
日程安排

讲者简介
组织者简介

肖仰华 复旦大学
肖仰华博士,复旦大学计算机学院副教授、博导,复旦大学知识工场实验室创始人、负责人,上海市互联网大数据工程技术中心副主任,兼任多家规模企业高级顾问或首席科学家。主要研究兴趣包括知识图谱、大数据管理与挖掘。在SIGMOD,VLDB, ICDE, IJCAI, AAAI等国际顶级学术会议发表论文100多篇。领导构建国内首个知识库云服务平台(知识工场平台kw.fudan.edu.cn),以API形式对外服务4亿次。
报告题目:知识图谱研究的回顾与展望
报告摘要:
自2012年谷歌正式推出知识图谱技术以来,知识图谱技术经历了飞速的发展,吸引了来自工业界和学术界的广泛关注,在一系列实际应用中取得了显著效果,成为了人工智能技术知识工程分支在大数据时代的代表性进展。但随着知识图谱技术应用的深入,知识图谱技术自身局限性也日益暴露,当前知识图谱技术已经难以应对智能化大潮对其提出的严峻要求。本报告将结合复旦大学知识工场实验室自2011年以来在知识图谱研发与落地方面的科研实践,系统总结知识图谱研究与落地中的一系列关键科学问题,梳理突破当前技术瓶颈的主要技术思路,展望知识图谱技术下一阶段发展前景。

林欣 华东师范大学
林欣,男,出生于 1981 年 7 月,2003 年和 2008 年分别于浙江大学计算机学院获得学士和博士学位。现担任华东师范大学信息科学技术学院副教授。主要致力于新型数据管理研究和群智计算研究。先后在该领域发表论文 40 余篇,其中近三年在中国计算机学会推荐的 A 类顶级期刊 TKDE 和 A 类会议 ICDE 发表论文 8 篇。曾作为项目负责人主持了三项国家自然科学基金项目、上海市博士后科研计划、中国博士后面上项目一等资助等项目。2011 年入选首批“香江学者计划”,赴香港浸会大学从事为期 2 年的访问研究。2014 年回国后入选上海市“浦江人才计划”。现担任 SCI 杂志《Frontier of Computer Science》青年副主编,担任 TKDE、TPDS 等权威学术期刊的审稿人,并多次担任 WAIM,ICPADS 等国际会议的 PC member。获得授权专利 2 项,并获得上海科技进步奖一项。
报告题目:知识图谱的众包构建与精化
报告摘要:
知识图谱的构建是知识图谱领域中最受关注,也是最难的问题之一。由于语料来源杂乱不堪、自然语言处理技术存在瓶颈,完全靠机器并不能实现覆盖度和准确率双高。在构建的过程中,加入众包可以实现知识图谱的精化, 尤其在对计算机难以完成而人较容易完成的任务中,如实体对齐、范式匹配和关系判定等,众 包可以发挥更大的作用。本次课程从众包的基本原理展开,讲授其中若干关键子问题,如众包问题设计、质量控制等。结合知识图谱构建中面临的若干问题,分析各个众包的例子,讨论深智众包的设计原则。

李直旭 苏州大学
李直旭,2013年毕业于澳大利亚昆士兰大学,获计算机科学博士学位。现为苏州大学计算机学院特聘副教授,硕导,江苏省“双创”博士入选者。研究方向为数据质量,众包技术和知识图谱。现为CCF数据库专委会通讯委员,人工智能学会智能服务专委会委员。IEEE TKDE, WWWJ等期刊长期审稿人,已发表论文50余篇。
报告题目:知识图谱构建的质量控制
报告摘要:
在当今大数据时代,拥有可靠、准确、及时的高质量数据是充分发挥大数据所赋予的机遇和优势的基本前提。然而如何在大量“脏”数据的使用中进行质量控制成为数据工程和知识工程领域最重要最艰巨的课题之一。作为知识工程的核心内容 - 知识图谱的构建涉及到方方面面的质量控制问题。比如多源数据的融合和统一、错误及矛盾知识的诊断和修正、以及缺失知识的推理和填补。在本次报告中,我们将介绍有关知识图谱的质量控制方面的相关前沿工作,并简要介绍我们在该方向上做的一些前瞻性研究工作。
报告人简介

杨燕 华东师范大学
杨燕,华东师范大学,博士,讲师,研究方向包括自动问答系统、知识图谱、信息抽取等,获得两次上海市科技进步二等奖,作为主要研究人员参与了国家科技支撑项目2项,主持和参与了多项上海市科委重大重点课题和上海市经信委科研课题;参与了多项上海市科委信息技术领域战略研究和上海市科委软科学研究项目。发表论文10余篇,编写教材1本,发明专利授权3项。
报告题目:大规模分布式知识图谱表示推理模型及应用
报告摘要:
知识图谱来源于大量人类归纳总结的结构化知识,作为知识的载体填补了信息和智慧之间的空白,为人工智能提供了具有可解释的并按照人的思维逻辑演绎的基础。近年来,随着开放域知识图谱的规模剧增,专业领域结构化数据融合转型的需求,对大规模知识图谱的表示、存储以及复杂的查询推理带来了效率和性能的挑战。如何高效简洁的表示、存储、推理大规模知识图谱被人们广泛关注。本报告首先介绍目前主流的知识表示、存储和推理技术,然后提出了大规模分布式知识图谱表示和推理模型KGPro,探讨KGPro-Schema表示和NoSQL存储方案,知识图谱查询和推理KGPro-Logic算法,知识图谱分布式中间件KGPro-middleware以及基于KGPro 开发的知识图谱问答系统。最后,我们探讨大规模分布式知识图谱表示和推理的未来发展趋势。

张鹏 清华大学
张鹏,清华大学计算机科学与技术系知识工程研究室资深工程师,清华数据科学研究院科技大数据研究中心研究员。研究领域包括文本数据挖掘和语义分析、知识图谱构建和应用等。作为主要研究人员参与欧盟第七合作框架跨语言知识抽取、国家863计划“海量知识库建设与构建关键技术及系统”等项目的研究工作,并参与设计和研发了国内首个中英文平衡的跨语言知识图谱系统XLORE(http://xlore.org)。长期致力于将知识图谱研究理论应用于实际需求,在语义大数据分析、智能问答、辅助决策等应用领域拥有丰富的实践经验。
报告题目:跨语言知识图谱构建

张富峥 微软亚洲研究所
Fuzheng Zhang is now a researcher atMicrosoft Research Asia. His research mainly focuses on recommender systems anduser modeling by using techniques such as deep learning, knowledge base,natural language analysis, etc. He has published academic papers frequently on reputableinternational conferences and journals in his research area, such as KDD, WWW,WSDM, Ubicomp, TIST. He has received the best paper award in ICDM2013.
Fuzheng Zhang received his Ph.D. degree inComputer Science from University of Science and Technology of China in 2015,and B.S. degrees both in Computer Science and Statistics & Finance from theUniversity of Science and Technology of China in 2010.
Hisresearch interests include user modeling, recommender systems, deep learning,sentiment/emotion detection, location-based social networks, spatial temporaldata mining, ubiquitous computing, and large-scale systems.
报告题目:Collaborative Knowledge Base Embedding for Recommender Systems
报告摘要:
Among different recommendation techniques, collaborative filtering usually suffer from limited performance due to the sparsity of user-item interactions. To address the issues, auxiliary information is usually used to boost the performance. Due to the rapid collection of information on the web, the knowledge base provides heterogeneous information including both structured and unstructured data with different semantics, which can be consumed by various applications. In this paper, we investigate how to leverage the heterogeneous information in a knowledge base to improve the quality of recommender systems. First, by exploiting the knowledge base, we design three components to extract items’ semantic representations from structural content, textual content and visual content, respectively. To be specific, we adopt a heterogeneous network embedding method, termed as TransR, to extract items’ structural representations by considering the heterogeneity of both nodes and relationships. We apply stacked denoising auto-encoders and stacked convolutional auto-encoders, which are two types of deep learning based embedding techniques, to extract items’ textual representations and visual representations, respectively. Finally, we propose our final integrated framework, which is termed as Collaborative Knowledge Base Embedding (CKE), to jointly learn the latent representations in collaborative filtering as well as items’ semantic representations from the knowledge base. To evaluate the performance of each embedding component as well as the whole system, we conduct extensive experiments with two real-world datasets from different scenarios. The results reveal that our approaches outperform several widely adopted state-of-the-art recommendation methods.

钱正平 阿里巴巴
Dr. Zhengping Qian is a Senior Staff Engineer in the Big-Datainfrastructure team at Alibaba. He is responsible for driving the developmentof new systems and business solutions for emerging applications such aslow-latency graph analytics and machine learning. Before joining Alibaba in2015, he was a Lead Researcher at Microsoft Research. His research interestsare in distributed and data-parallel computing. Dr. Qian received his PhD inComputer Science from South China University of Technology in 2009.
报告题目:Challenges and Opportunities in Large-Scale Graph Processing at Alibaba
报告摘要:
Many business-critical applications concern a tremendous graph consisting of billions of vertices and trillions of edges. For example in e-commerce, the vertices can represent users, items and accounts, and the edges model various user behaviors. Key scenarios like recommendation and fraud detection often rely on the detection and understanding of complex patterns in real time, where the graph needs updating dynamically at a high speed with every user transaction. In this talk we will outline concrete use cases from both inside and outside Alibaba and highlight some of the key challenges ranging from algorithm design to efficient distributed computing and even data visualization. We believe those challenges present research opportunities and future prospects in building modern data-processing infrastructures.

司华健 安徽富驰信息技术有限公司
司华健,安徽富驰信息技术有限公司(Future-Data)高级自然语言处理工程师,2012年从中国科学技术大学硕士研究生毕业。长期从事自然语言理解、知识库、智能客服、知识图谱等方面的研究工作。曾负责中国平安集团智能客服项目的开发工作。目前负责公司司法领域知识图谱的研究。
报告题目:知识图谱实践之司法裁判应用
报告摘要:
随着国家大力推进人工智能产业的展,司法行业作为应用领域之一,也在积极探索和尝试。本报告重点介绍我们在尝试解决司法类案检索问题构建的两个知识图谱:案件知识图谱和裁判知识图谱,以及应用。
主办单位
华东师范大学计算机科学技术系
复旦大学知识工场实验室
苏州大学
上海数眼科技发展有限公司
赞助单位
国家自然科学基金
上海市自然科学基金
点击文末“阅读原文”即可在线报名